图机器学习提供了一个强大的框架,它在化学、生物学和材料科学等科学领域有着天然的应用。通过将数据表示为图,我们编码了先验知识,即数据由一组实体组成,这些实体之间的互动与它们的单独属性一样有信息量,并且手头的任务不取决于它们的排序。虽然图表示允许有效的学习,但构建既有表达能力又高效的图神经网络带来了重要的挑战。
这篇论文的主要焦点是推进在构建能够处理大规模数据的置换等变神经网络的最新技术。为了实现这一点,我们首先会深入了解置换等变性及其实际意义,然后提出新的算法,利用图神经网络的优势,同时避开如图匹配等具有挑战性的问题。
在我们的第一项贡献中,我们提出了结构消息传递(SMP)模型。SMP以单热编码的形式引入节点标识符,并以置换等变的方式处理它们。使用标识符使网络比标准的消息传递神经网络具有更高的表达能力,但仍保留其对学习局部函数的归纳偏见。从经验上看,与不利用消息传递方案的其他表达架构相比,SMP显示出更好的泛化能力。
虽然学习无序数据的表示的架构已经被广泛研究,但我们在接下来的贡献中显示,图生成架构仍然存在许多未解决的问题。我们首先考察了许多集合和图生成架构的一个重要组成部分,即将向量转化为集合的运算符。由于置换转换集合但不转换向量,向量到集合的层对于标准的等变理论构成了一个挑战,当一个群在函数输入上平凡地作用时,不能使用此理论。为了应对这一挑战,我们分析了这一设置中的等变要求,并提出了一个名为Top-n创建层的新向量到集合层。这一层可以插入到几个架构中,作为其他向量到集合函数的替代。我们展示了它在几个集合和图生成任务上改善了生成质量。
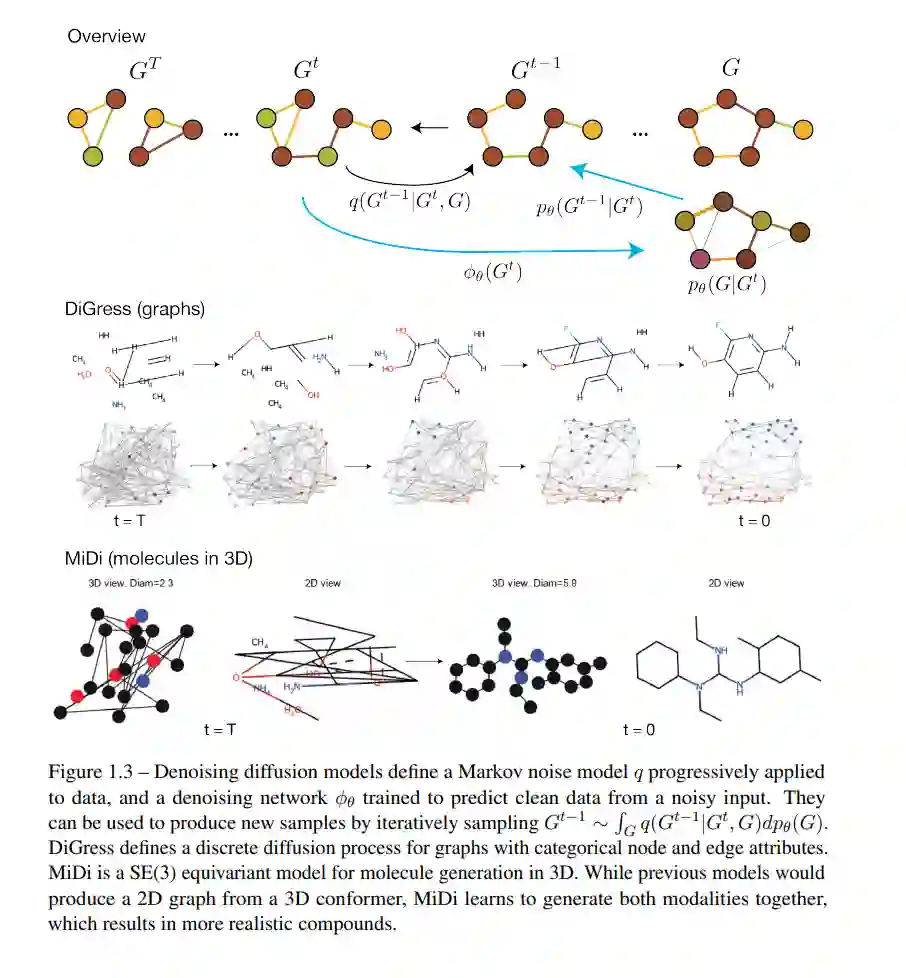
我们接着展示,通过构建去噪扩散模型,即那些迭代去噪随机集合或图的结构,性能可以得到大幅提升。具体来说,我们提出DiGress模型用于图生成,以及MiDi用于联合生成分子的2D和3D结构。这些模型利用了图的离散结构,并能够在扩散过程中保持其稀疏性。因此,它们可以成功地模拟比以前的高斯扩散模型更大的图。
总体来说,所呈现的研究显示,表示和生成图数据需要仔细考虑。使用为其他数据模式(如图像)开发的结构可能会导致严重的理论问题,这些问题和同构测试一样具有挑战性。通过识别这些限制,我们可以提出更有效的新方法,为图神经网络在各种科学领域的新应用铺平道路。
关键词:置换等变性、图神经网络、消息传递神经网络、图生成、去噪扩散模型。 图机器学习已成为机器学习中的强大而多功能的工具,在广泛的应用中获得了普及。最初用于传感器和社交网络分析,图机器学习现在越来越多地用于化学、计算生物学和材料科学等科学领域。将数据表示为图的优势在于图自然编码的不变性,特别是认为数据顺序对手头的任务是不相关的。这种先验对于许多真实世界的系统,包括分子、n体系统、游戏中的代理、社交网络和场景中的对象,都是有益的。然而,计算机需要用有序的张量,如邻接矩阵或邻接列表,来表示图。这提出了一个关键的挑战。排列等价性,即使用有序表示来处理无序对象的需求,是图机器学习及其相关困难的核心。
为了利用基于图的表示的威力,需要专门的神经结构。可以说,理论上可以使用多层感知器(MLP)来完成基于图的任务,因为它是紧凑空间上连续函数的通用逼近器(Cybenko,1989)。然而,这种方法在实践中是有限的(Zaheer等,2017),因为MLP没有对手头的任务编码大量的先验知识(Xu等,2020b)。由于连续性和平滑性不构成克服维度诅咒的足够先验(von Luxburg & Bousquet,2004),我们可以预期,用MLP学习图的所需数据量是图大小的指数。
图神经网络(GNNs)已经成为学习图结构数据的常见框架。GNNs历史上是基于图的傅里叶变换的定义构建的(Bruna等,2013)。然后将这些光谱过滤器制定为拉普拉斯多项式(Defferrard等,2016;Khasanova & Frossard,2017),这可以使用迭代传播方案来实现。这种观点导致了Message-Passing Neural Networks(MPNNs)的重新发现(Gilmer等,2017),这最初是在(Scarselli等,2008)的开创性工作中提出的。MPNNs的计算复杂性是边数的线性,并且它们计算的数据局部描述类似于图像的卷积核。由于这些有益的特性,MPNNs在各种任务上都取得了令人印象深刻的性能,包括社交网络的半监督分类(Kipf & Welling,2016)和物理模拟(Garcia & Bruna,2017)。从理论上讲,图神经网络的样本复杂性只在图大小上呈二次增长(Scarselli等,2018;Garg等,2020),使它们比MLP更适合于学习图。
尽管图神经网络在各种任务上都表现出色,但其局限性已被识别,特别是在具有有限属性的图上(Cai & Wang, 2018)。例如,它们在需要学习图的结构属性的任务上表现出奇差,如其连通性(Corso等,2020)或循环计数(Vignac等,2020)。这些局限性不仅从经验上观察到,而且根植于对MPNNs表示能力的分析。具体而言,Morris等(2019)和Xu等(2019)已经证明,MPNNs只能学习图上的一个受限类函数,证明它们在图同构测试中的能力不比Weisfeiler和Lehman在(Weisfeiler & Lehman, 1968)中提出的1-Weisfeiler-Lehman测试(1-WL)更强。这意味着,对于1-WL测试认为是同构的任何两个图,MPNNs将输出相同的嵌入。除其他后果外,这一结果意味着MPNNs在图中计数子结构的能力有限(Chen等,2020)。对MPNNs表示能力的研究导致了开发更强大的架构,这些架构通常考虑节点的三元组(Morris等,2019)或在比典型的MPNNs更大的结构上执行消息传递(de Haan等,2020)。这些架构产生了丰富的理论分析(Morris等,2021),但它们通常不包括MPNNs的重要局部性先验,这最终限制了它们的性能。
图神经网络的表达能力不是它们的唯一局限性。构建高效的图粗化函数(Mesquita等,2020)或丰富的全局池化层(Corso等,2020)也令人意外地具有挑战性。此外,在具有丰富节点属性的几个数据集上,MPNNs的性能并不比简单的光谱滤波器更好(Wu等,2019)。虽然这些结果中的一些来自标准基准中使用的数据集的特定属性,但其他则构成了MPNNs和排列等变网络的基本局限性。
虽然图表示学习中的方法和未解决的问题现在相对较好地被理解,但与此相反,图生成仍处于初级阶段。然而,它在药物发现(Xia等,2019)、计算生物学(Yang等,2021a)、催化剂设计(dos Passos Gomes等,2021)、代码完成(Brockschmidt等,2019)和电路设计(Brophy & Voigt, 2014)等领域有重要应用。图生成可以在分布学习设置中使用,其中的目标是生成与训练集中相似的图,也可以在面向目标的设置中使用,其中需要在约束条件下优化特定属性。在这两种情况下,正确捕获训练集的分布都是至关重要的先决条件。
图生成既有图表示学习的挑战,也有其自身的困难。为了理解它们,我们可以将图生成架构与图像生成的相应架构进行比较。用于图像生成的神经网络通常具有“U-net”结构,其中编码器中有池化层,解码器中有上采样层。由于相邻的图像像素往往非常相关,这些层通常非常有效。U-Net结构允许定义一个降维的潜在空间,在该空间中数据表示被压缩,这是设计生成架构的有效策略。相反,图是无序的,并且不能假定邻接矩阵的两个邻近条目是相关的。因此,对于图而言,图的粗化和图的上采样明显比对于图像更为困难。因此,图通常很难压缩成向量或更小的图。
从理论上看,我们可以观察到,如果我们可以访问一个排列不变的图到向量模型,以及一个从其潜在向量重构输入图的确定性解码器,我们就可以得到一个图规范化算法。图规范化至少与图同构测试一样困难,因此不足为奇的是,早期使用低维潜在空间的图生成架构只能成功生成微小的图(Simonovsky & Komodakis, 2018; De Cao & Kipf, 2018)。
在这篇论文中,我们的目标是发展我们对排列等变性对机器学习任务的实际后果的理解。通过更好地理解排列等变函数的好处和与之相关的挑战,我们能够设计架构,这些架构利用图神经网络的优势,并尽可能少地依赖它们的弱点。这些架构选择可能对性能产生巨大影响,正如在本论文中提出的Set2GraphVAE和DiGress架构之间的比较中所示。
在第4章,我们提出了一个图生成架构,经过在QM9数据集上训练6小时后,可以生成60%的真实分子,这接近于发表时的最新技术水平。在第5章中提出的模型中,我们在同一数据集上在一个小时内达到了99%的有效性,大部分改进来自于另一个问题表述,不需要在潜在空间中压缩数据。
在这个简介的其余部分,我们总结了这篇论文的贡献。在第2章,我们介绍了关于排列等变神经架构的背景,并回顾了关于它们表示能力的已知结果。
第3章接着回答以下问题:我们如何设计更有表现力的架构,同时保留MPNNs的归纳偏见,以及何时需要这样的架构?我们提出了结构化消息传递框架(SMP),一个等变消息传递架构,它克服了MPNNs的局限性,但需要操作更大的张量。SMP是基于消息传递框架的第一个架构,它在网络中不引入随机性就实现了更高的表示能力。与其他强大的架构相比,它保留了MPNNs的局部性先验,这在经验上导致了更好的泛化性能。