
导读
自回归语言模型推动了代码生成、代码补全和软件工程智能体的快速发展,但“从左到右预测下一个 token”并不天然适合代码。代码不是线性散文:开发者会先写接口再补实现,会回到文件开头补 import,会根据运行错误修改前面的设计,也会在多个文件之间维护依赖关系。论文《Beyond the Autoregressive Horizon》正是从这个矛盾出发,系统梳理三类可能突破自回归瓶颈的代码建模范式:扩散模型、代码世界模型和状态空间模型。 这篇综述的核心观点是:下一代代码智能不能只把程序当文本,而要把代码看成具有结构、状态和执行语义的对象。扩散模型强调全局迭代修正,适合代码编辑、修复和结构化生成;状态空间模型用线性复杂度维护长上下文状态,适合仓库级代码理解;代码世界模型则试图学习程序执行后的状态变化,让模型理解“代码做了什么”,而不只是“代码长什么样”。作者进一步把这些方向与认知神经科学联系起来,认为更强的代码智能应接近人类编程中的 System 2 能力:规划、验证、调试和执行感知推理。
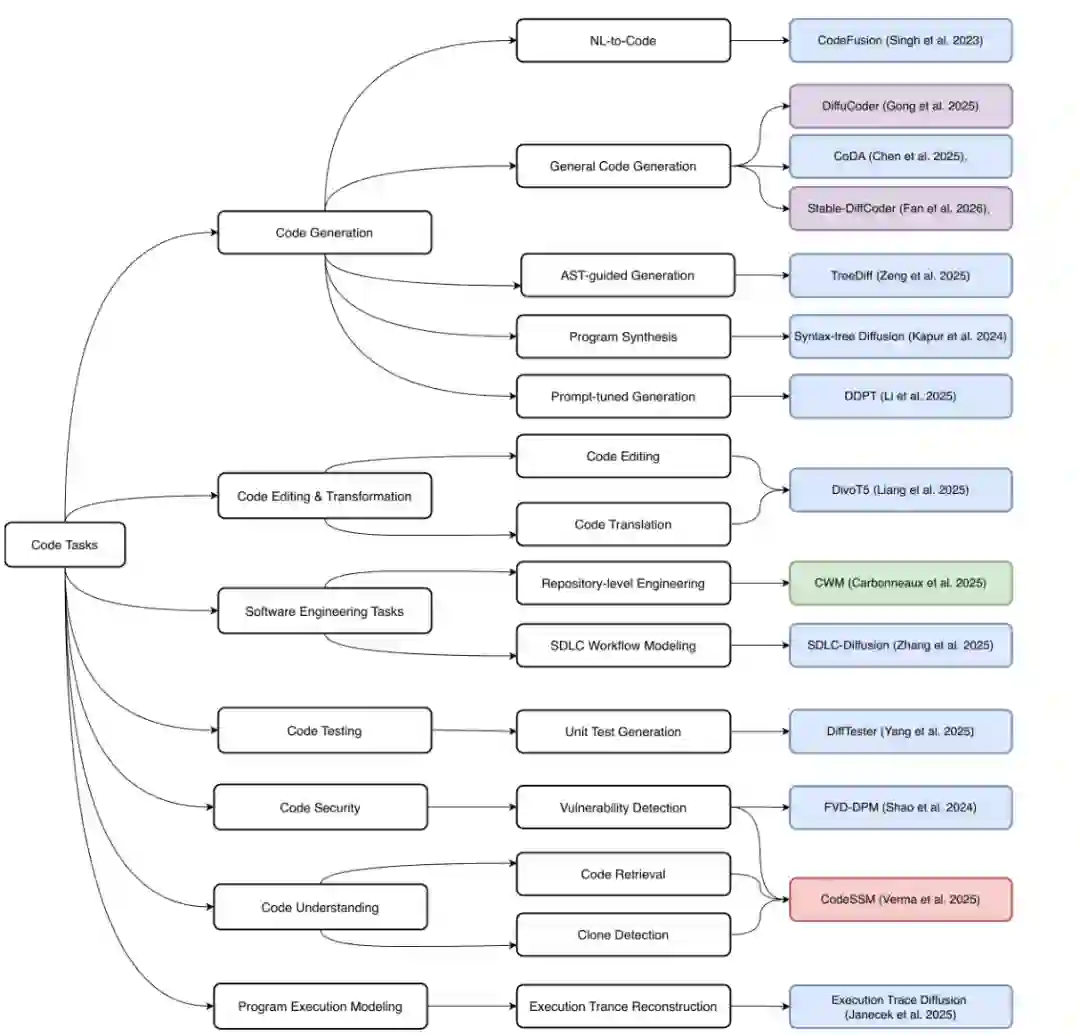
图1:非自回归代码建模范式在不同代码任务中的分布。蓝色表示扩散模型,绿色表示世界模型,红色表示状态空间模型。
Introduction: The Autoregressive Bottleneck / 引言:自回归瓶颈
自回归模型将序列概率分解为逐 token 条件概率,形式简单、训练稳定,也与自然语言的线性表达高度匹配。但论文指出,这种范式在代码场景中会形成“顺序依赖陷阱”:早期 token 决策会持续约束后续生成,一旦模型在文件开头选错库版本、误写函数签名或采用不合适的数据结构,后续内容只能在这个错误上下文上继续展开,错误会被不断放大。 代码的依赖方向并不总是从前到后。函数体中的实现细节可能决定文件开头需要导入什么模块;类型定义和变量作用域可能跨越数百行;一个右括号必须匹配远处的左括号;仓库级任务还涉及跨文件接口、测试行为和运行环境。自回归模型虽然可以通过注意力访问长上下文,但生成动作仍然是单向的,缺少天然的回看、重写和全局修正机制。 论文由此提出三条非自回归或非纯自回归路线。扩散模型通过反复去噪来生成或修改整段代码,允许全局结构在多轮迭代中逐步成形;状态空间模型通过隐状态压缩历史信息,以线性复杂度处理长上下文;代码世界模型学习程序执行状态的变化,将代码建模从语法统计推进到执行语义。三者并不是简单替代自回归模型,而是为代码智能补上规划、长程依赖和执行 grounding。
Diffusion: The Paradigm of Iterative Refinement / 扩散:迭代式精化范式
离散扩散与代码生成
扩散模型最初在连续图像空间中取得成功,而代码由离散 token 构成,因此需要离散扩散机制。论文重点讨论了基于 [MASK] 的吸收态扩散:前向过程逐步把干净代码 token 替换成 mask,反向过程则学习从带噪序列恢复完整程序。与图像扩散不同,代码扩散必须同时满足语法、类型、变量引用和结构约束,这使它天然面向全局一致性。 扩散模型的关键优势在于不必严格按照左到右顺序生成。模型可以在同一轮中更新多个位置,利用左右双向上下文判断函数签名、变量使用、括号匹配和返回语句是否一致。这与人类写代码时“先草拟,再修改,再修复错误”的过程更接近。
并行解码与反复修正
论文将扩散生成动态概括为两个机制:并行解码和迭代精化。并行解码使模型可以同时更新序列中的多个 token,而不是每次只生成一个 token;迭代精化则让模型在多轮去噪中反复修正不一致之处。例如,模型可以先生成粗略结构,再补全函数体,随后根据变量定义修正调用位置。 这带来了一个重要性质:解码步数可以与序列长度解耦。自回归模型生成更长代码通常需要更多顺序步骤,而扩散模型可以通过固定或较少的去噪轮次更新整段代码。这对长文件、跨函数编辑和代码修复尤其有吸引力。当然,扩散模型也存在训练复杂、离散 token 去噪难度高、评估标准尚未统一等问题。

图2:自回归、状态空间模型和扩散模型的代码生成动态对比。颜色强度表示 token 生成时间,扩散模型更接近全局异步精化。
软件开发任务中的扩散模型
论文梳理了扩散模型在代码任务中的一系列应用:自然语言到代码、一般代码生成、AST 引导生成、程序合成、prompt 调优生成、代码编辑、代码翻译、单元测试生成、漏洞检测、执行轨迹重建以及软件开发生命周期建模。相比传统代码生成只关注 HumanEval、MBPP 这类短程序 benchmark,扩散模型覆盖的任务更偏向“修改、修复、编辑和结构化生成”。 作者特别强调了一类将自回归模型改造为扩散框架的工作。它们通常利用 shift operation 对齐预训练模型的 next-token 能力,再通过 attention mask annealing 逐步从因果注意力过渡到双向注意力。这种路线说明,未来系统未必需要完全抛弃自回归模型,而可以在已有生成能力上叠加全局精化能力。
State-Space Models for Code / 面向代码的状态空间模型
从控制理论到长上下文建模
状态空间模型源自控制理论和信号处理,用隐状态描述系统随输入变化而演化的过程。用于序列建模时,SSM 维护一个持续更新的 latent state:每读入一个 token,状态被更新,并产生相应输出表示。与 Transformer 显式计算 token 两两注意力不同,SSM 通过状态传播信息,因此复杂度可以随序列长度线性增长。 这对代码尤其重要。真实代码仓库包含长文件、跨文件依赖、重复定义、远距离调用和版本演化记录。Transformer 的二次注意力成本会限制上下文长度,而 SSM 的线性更新更适合处理大规模上下文。论文回顾了 HiPPO、S4、S4D、S5、Mamba 等路线,指出现代 SSM 正在从理论结构走向可扩展的大模型架构。
长程记忆与混合架构
SSM 的优势不是替代所有注意力,而是提供高效长程记忆。Mamba 通过输入相关的选择性状态更新提升表达能力,同时保留线性推理效率;Jamba 等混合架构则将注意力块与 SSM 层结合,让注意力负责精确局部交互,让 SSM 承担长程记忆和压缩。 这种混合思路很适合代码。局部代码片段需要精确 token 对齐,例如函数调用参数、运算符和缩进;而全局上下文需要跨越长距离保留项目结构、变量定义和 API 使用模式。将注意力和 SSM 结合,可能比单一结构更适合仓库级代码理解。
状态空间模型在代码智能中的角色
论文指出,目前 SSM 在代码领域更多被用作表示学习器,而不是强生成器。代表性工作 CodeSSM 将 SSM 编码器用于代码检索、漏洞检测、克隆检测和 token 分类等任务,显示出较好的样本效率和长上下文扩展能力。也就是说,SSM 在“理解代码”和“维护长程状态”上已有潜力,但在程序合成、复杂代码生成和多文件编辑中的能力仍处于探索阶段。 作者还提到,SSM 对程序语义的内部表示值得关注。代码的语义不只来自文本邻近关系,还来自控制流、数据流、类型系统和运行行为。SSM 是否能在隐状态中压缩这些信息,决定了它能否从长上下文编码器进一步发展为面向代码推理的核心架构。
Code World Modelling for Learning Execution Semantics / 代码世界模型:学习执行语义
从文本预测到状态预测
代码世界模型的核心是“next-world prediction”而不是“next-token prediction”。模型不只预测下一段代码文本,而是预测一个动作执行后程序状态会如何变化。对代码而言,这意味着理解变量、堆栈、文件系统、测试结果、依赖关系和运行时环境如何随代码变动而改变。 论文认为,当前 LLM 往往把代码当作文本统计模式,因此可能生成语法正确却运行失败的程序。真正的软件工程能力要求模型知道代码执行后会发生什么。例如,某一行代码如何改变局部变量,某个函数调用会触发哪些副作用,修改一个文件会让哪些测试失败。世界模型通过学习这些状态转移,为代码生成提供执行语义 grounding。
执行轨迹与智能体交互轨迹
作者将代码世界模型的训练信号分为两类:执行轨迹和智能体交互轨迹。执行轨迹记录程序在解释器、测试器或容器中的中间状态,例如变量更新、函数调用栈和输入输出结果;智能体交互轨迹则记录 LLM 软件工程 agent 在仓库环境中的多步操作,例如编辑文件、运行测试、读取报错并继续修复。 这两类数据能让模型学习“代码改变如何影响环境”。在 SWE-bench、Terminal-Bench、CruxEval 等任务中,评估不再只看生成片段是否通过样例,而是看模型能否在真实或近真实开发环境中完成修复、执行和验证。论文认为,这是从代码生成走向代码智能的关键转变。
Cross-Paradigm Benchmarking Trends / 跨范式基准趋势
论文的表1总结了不同范式的评测实践,也揭示了当前研究的一大问题:各范式使用的任务、数据集和指标并不统一,直接横向比较很困难。 自回归模型仍主要绑定传统代码生成评测,如 HumanEval、APPS 和 pass@k,重点是短程序功能正确性。扩散模型的评测范围更广,覆盖 CoNaLa、代码修复、编辑、测试、漏洞检测和软件工程工作流,指标也扩展到 execution match、结构相似度、覆盖率、吞吐量和工作流级指标。SSM 目前主要出现在代码理解任务中,如检索、漏洞检测和克隆检测,指标包括 MRR、F1 和 accuracy。世界模型则更常出现在仓库级任务中,强调 resolve rate、任务完成率和执行验证。
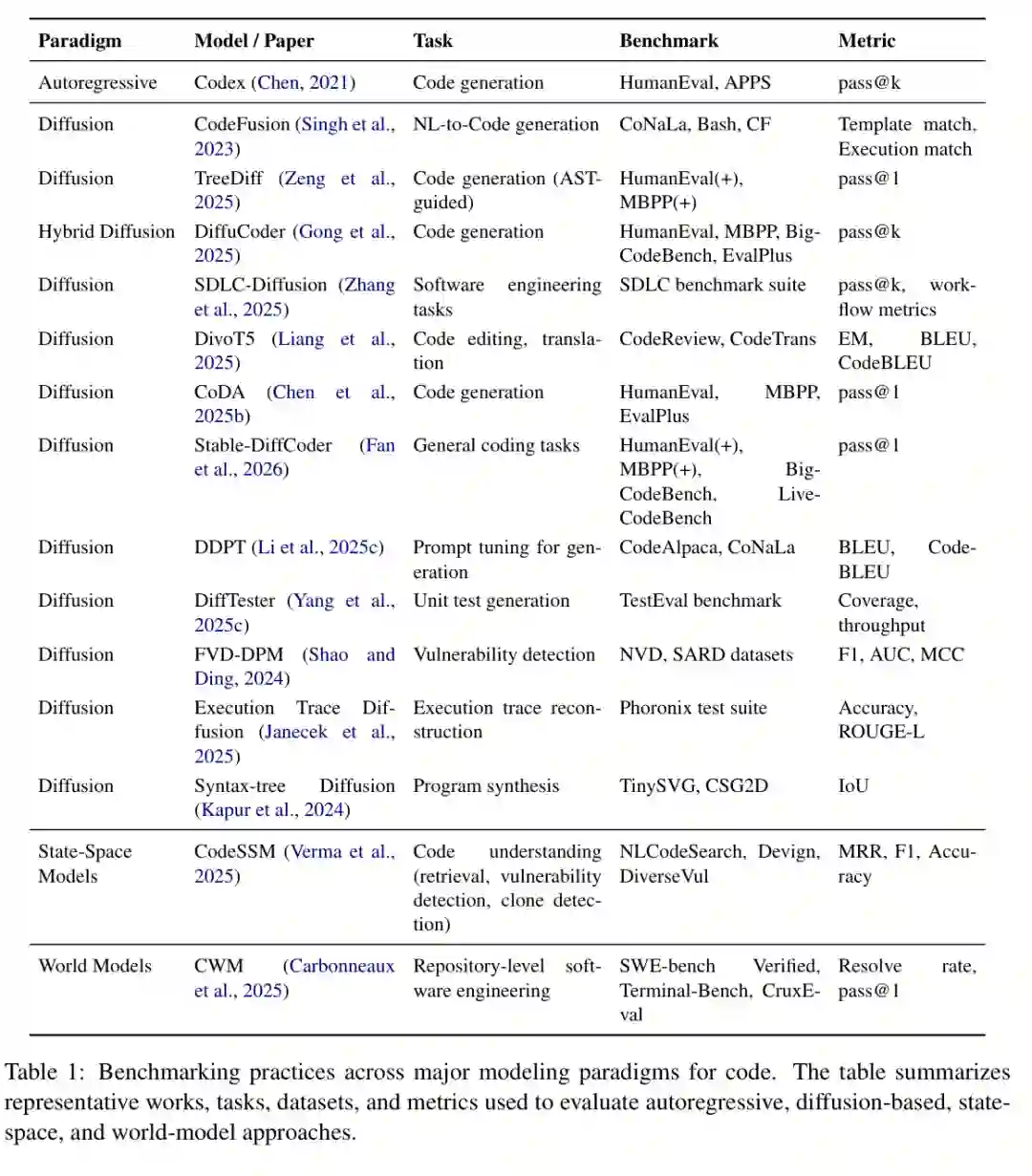
图3:主要代码建模范式的代表工作、任务、数据集与评测指标对比。 这个评测差异说明,代码智能正在从“短代码片段生成”扩展到“结构化修改、长上下文理解和执行环境交互”。但它也带来一个挑战:如果不同范式使用完全不同的 benchmark,就很难判断谁真正更强。作者呼吁建立统一评估框架,覆盖长上下文推理、迭代编辑、执行感知和仓库级软件工程。
Discussion: Cognitive Alignment of Code Models / 讨论:代码模型的认知对齐
编程不是语言模仿
论文在讨论部分引入认知神经科学,反驳一个常见误解:编程不是简单的自然语言任务。自然语言生成可以近似看作线性表达,但编程涉及逻辑推理、数学问题求解、工具使用、结构规划和调试控制。fMRI 研究显示,代码理解主要激活多需求网络,而不是传统语言中枢,这意味着代码能力与一般语言能力并不完全同源。 因此,纯自回归预训练在认知上存在错位。它擅长模拟线性文本,但不擅长模拟人类开发者的循环过程:规划、草拟、运行、观察、修正、再验证。代码模型要真正对齐编程任务,需要具备类似 System 2 的能力,即有意识的计划、反思和错误纠正。
三类范式与系统二编程
扩散模型对应“草稿-审查-精化”的认知过程。开发者通常不会一次写出最终代码,而是从模糊结构开始,逐步修复语法、变量、逻辑和边界条件。扩散的反复去噪正好形式化了这种迭代修正。 状态空间模型对应持续状态追踪。程序理解需要跟踪变量、栈、作用域、依赖和上下文历史,SSM 的隐状态为长程记忆提供了架构基础。代码世界模型则对应心理模拟:开发者会在脑中预测某段代码执行后的结果,世界模型试图把这种预测能力显式学习出来。 作者最终设想的是混合式代码智能体:用自回归模型保持强大的自然语言与代码生成能力,用扩散机制提供全局编辑与修复,用 SSM 提供长程上下文记忆,用世界模型提供执行语义 grounding。这样的系统更接近软件工程中的真实工作流,而不是一次性文本续写。
Conclusion and Future Scope / 结论与未来方向
论文总结认为,代码智能正在从 token-level prediction 走向 program-level reasoning。自回归模型仍然重要,但它的结构限制在复杂软件工程任务中越来越明显。扩散模型已经在代码编辑、修复、结构化生成和软件开发生命周期建模中展现成熟度;SSM 和代码世界模型仍较早期,但分别指向长上下文效率和执行语义理解。 未来最有前景的方向不是单一范式取代另一范式,而是混合架构。一个可行路线是保留自回归模型强大的生成和指令跟随能力,再引入扩散式全局精化、SSM 长程状态记忆和世界模型执行预测。Block Diffusion 等早期工作已经展示了将自回归生成与扩散修正结合的可能性。 对软件工程智能体而言,这种范式融合尤其关键。真实任务要求模型规划修改、理解仓库状态、运行测试、解释错误并反复迭代。下一代代码模型的竞争焦点,可能不再只是 HumanEval 上的 pass@1,而是能否在复杂环境中稳定完成长程、可验证的软件任务。
Limitations / 局限性
论文也明确指出,本综述的局限在于跨范式比较困难。自回归模型、扩散模型、SSM 和世界模型往往在不同任务、数据集和指标上评估,缺少统一 benchmark。因此,当前更适合把这些范式理解为互补能力地图,而不是简单排名。 此外,扩散模型在离散代码空间中的训练效率、SSM 在生成式代码任务中的能力、世界模型的大规模数据构建和评估可靠性,都还需要更多实证研究。作者的结论偏向趋势性判断:代码智能的未来会更关注规划、迭代编辑和执行感知,但具体架构仍处于快速探索阶段。
原文信息
论文标题:Beyond the Autoregressive Horizon: A Comprehensive Survey of Diffusion Models, World Modelling, and State Space Models for Code 作者:Kishan Maharaj, Ashita Saxena, Srikanth Tamilselvam 论文链接:https://arxiv.org/abs/2606.23690 PDF:https://arxiv.org/pdf/2606.23690
