
ICML 2026 | 多任务贝叶斯上下文学习:让 Transformer 在测试时显式适应新先验
论文题目:Multi-Task Bayesian In-Context Learning 论文链接:https://arxiv.org/abs/2606.20538 论文机构:New York University、NYU Langone Health 论文作者:Qingyang Zhu、Eric Karl Oermann、Kyunghyun Cho 代码地址:https://github.com/martianmartina/multi-task-bayesian-icl/

这篇 ICML 2026 论文讨论了一个很核心但常被隐藏的问题:如果我们把上下文学习看成一种近似贝叶斯推断,那么模型到底如何知道“先验”是什么? 已有 Prior-Data Fitted Networks、TabPFN 和各类 in-context learner 通常在大量模拟任务上训练,把某个训练先验隐式写进模型权重中。这样做可以把测试时的推断变成一次前向传播,但也带来明显限制:一旦测试环境的先验改变,模型没有一个显式入口去切换、修正或表达新的先验。现实任务中,先验往往随用户、领域、地理环境、时间窗口、医疗人群或实验设计变化而变化,固定在权重里的先验并不够灵活。 本文提出 Multi-Task Bayesian In-Context Learning,把“先验信息”显式表示为一组 prior datasets,并作为上下文前缀输入 Transformer;目标任务数据则接在后面。模型在训练时看到由同一元先验生成的多个 prior tasks 和一个 target task,因此学到的是:如何从前缀数据推断当前 episode 的先验,再基于目标任务证据输出后验预测分布。测试时,只要替换前缀数据,就可以改变模型使用的先验,无需微调参数。
1. 研究背景:ICL 的贝叶斯能力缺了一个接口
贝叶斯预测推断的优势在于,它可以把先验知识与观测证据结合起来,给出具备不确定性刻画的后验预测分布。理论上,这种方式适合数据少、噪声大、分布会变的场景;但实际计算中,后验预测分布通常需要对潜变量积分,MCMC 代价高,变分推断又会受近似族限制。 神经网络式的摊销推断提供了另一条路线:训练一个模型直接从数据集映射到预测分布。上下文学习进一步把数据集表示成序列,让 Transformer 在前向传播中完成类似推断的行为。PFN/TabPFN 等工作已经证明,在某些任务族中,Transformer 可以非常接近贝叶斯 oracle。 问题在于,这些模型通常只看目标任务证据,而不显式接收先验。训练先验被“烘焙”在权重中,测试时不能像贝叶斯模型那样自然地更换 prior。本文的切入点正是补上这个接口:让先验也成为上下文的一部分。
2. 核心想法:把先验写成上下文前缀
本文框架可以理解为一个层级贝叶斯 episode。每个 episode 先从元分布中采样一个 episode-level 超参数,再由这个超参数生成多个任务。前 K 个任务作为 prior datasets,最后一个任务作为 target dataset。Transformer 的输入序列中,prior datasets 被放在前缀位置,target dataset 的观测样本和查询点接在后面。
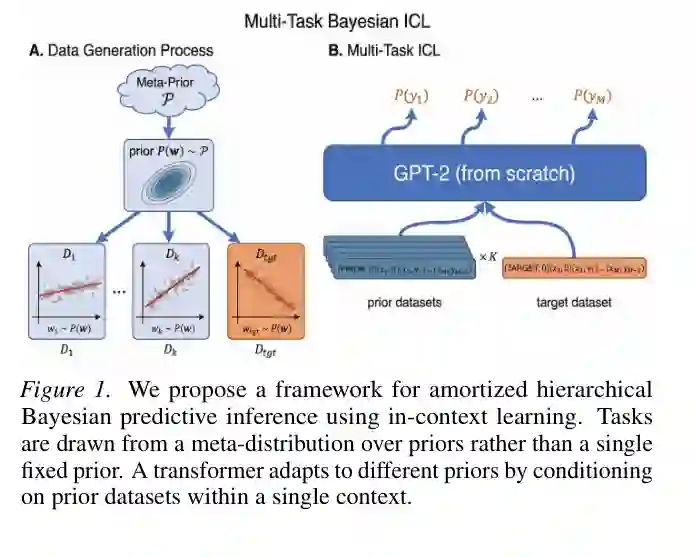
这相当于把传统贝叶斯推断中的 prior 参数从“模型权重中的隐变量”转化为“可替换的上下文证据”。如果测试时给模型不同的 prior datasets,它就应该推断出不同的先验形态,并相应改变 target task 的后验预测。 与普通 ICL 的区别可以概括为:
- 普通 ICL:上下文只有目标任务证据,训练先验固定在权重中。
- Multi-task Bayesian ICL:上下文包含 prior datasets 和 target dataset,先验可以在测试时由前缀数据控制。
- 层级贝叶斯对应关系:prior datasets 用来推断 episode-level prior,target dataset 用来形成目标任务后验。
作者使用一个从头训练的小型 GPT-2 作为 in-context learner,并通过负对数似然训练模型输出预测分布。对回归任务,模型输出高斯预测分布的均值和方差;对分类/逻辑回归任务,模型输出对应概率。
3. 实验设置:从可解析任务到复杂先验
论文设计了由易到难的实验序列,目的不是单纯刷分,而是检验模型是否真的学会了可控的层级贝叶斯推断。

主要实验包括三类合成先验和一个真实数据任务:
- 高斯先验下的线性回归与逻辑回归,用于检查模型能否匹配贝叶斯 oracle。
- Student-t 重尾先验,用于测试 out-of-meta-distribution prior shift 下的泛化。
- flow-based 高维结构先验,用于检验复杂 latent structure 下的可扩展性。
- ERA5 时空温度预测,用于验证 prior prefix 在真实数据中的实用价值。
作者还设置了多种贝叶斯参考模型和 ICL 对照组,包括 MCMC oracle、SVI、层级 MCMC、层级 SVI、带 prefix 的 ICL 和不带 prefix 的 ICL。

这个对比很关键:MCMC/SVI baseline 在某些设定下拥有生成模型形式或真实超参数知识,因此更像“上界参考”;神经 ICL 模型并不知道真实生成过程,只能从样本中学习推断规则。如果神经模型仍然接近 oracle,说明它学到的不只是模式匹配。
4. 主要结果一:带先验前缀的 ICL 接近贝叶斯 oracle
在线性回归实验中,作者用 KL divergence 衡量不同模型的后验预测分布与 oracle PPD 的差距。结果显示,带 prior prefix 的 multi-task ICL 在多种上下文长度和测试先验下都接近层级 MCMC 的表现;不带 prefix 的 ICL 则在先验偏移时明显退化。
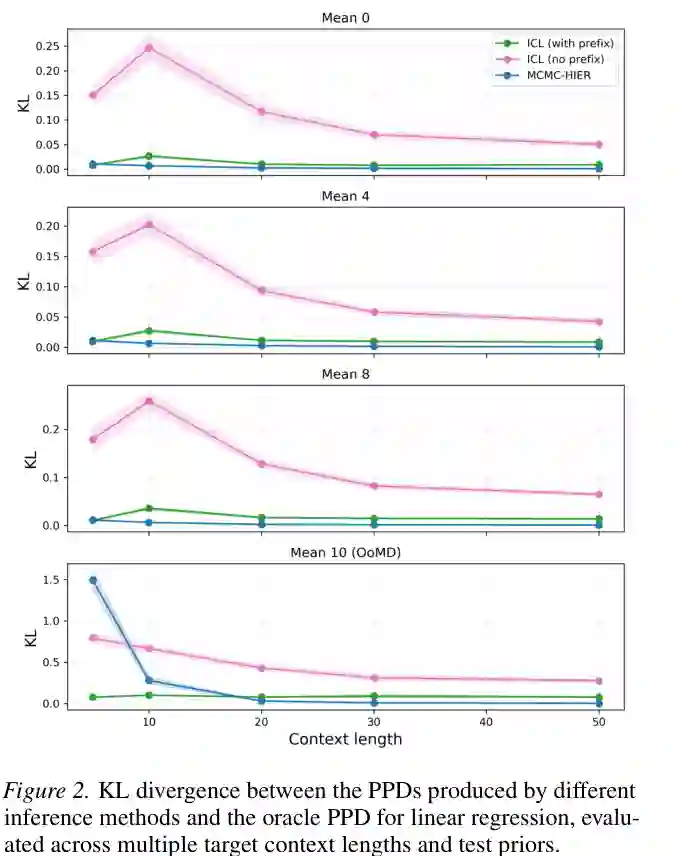
在线性高斯场景中,贝叶斯 oracle 可以相对清晰地定义,因此这是一个干净的 sanity check。它说明 Transformer 不是简单记住某个固定 prior,而是在前缀数据提供信息时,能够把它转化为目标任务的预测分布调整。 逻辑回归更难,因为后验预测分布没有闭式形式,需要用收敛 MCMC 近似 oracle。论文发现,在目标任务证据较少时,先验影响更强,不带 prefix 的 ICL 很难匹配 oracle;带 prefix 的 multi-task ICL 则能显著缩小差距。当目标任务样本增多时,似然逐渐主导,先验差异影响减弱,不带 prefix 的模型表现也会有所追上。
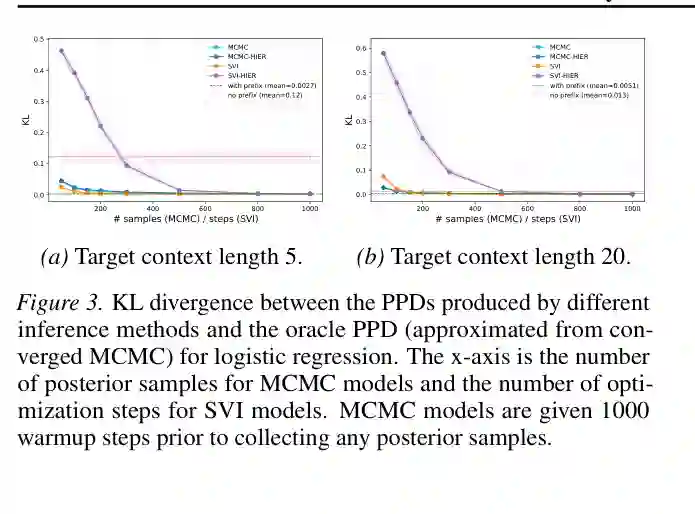
这一结果符合贝叶斯直觉:数据少的时候,先验更重要;数据多的时候,似然更重要。模型表现也跟随这一规律变化,说明它并不是任意利用前缀,而是在做与贝叶斯推断一致的权衡。
5. 主要结果二:模型确实把 prefix 当作先验,而不是额外目标数据
一个潜在质疑是:模型是否只是把 prior datasets 粗暴合并进 target dataset,相当于增加了样本量?如果是这样,它并没有理解“先验”,只是做了 evidence pooling。 作者通过 prior adaptability check 排除了这个解释。实验固定 target context,只改变 prior prefix 的分布,然后观察模型输出 logit 分布如何变化。结果显示,不同前缀会系统性改变预测 logit 分布,且神经模型更接近 oracle MCMC,而不是把 prior 与 target 混在一起的 pooled MCMC。
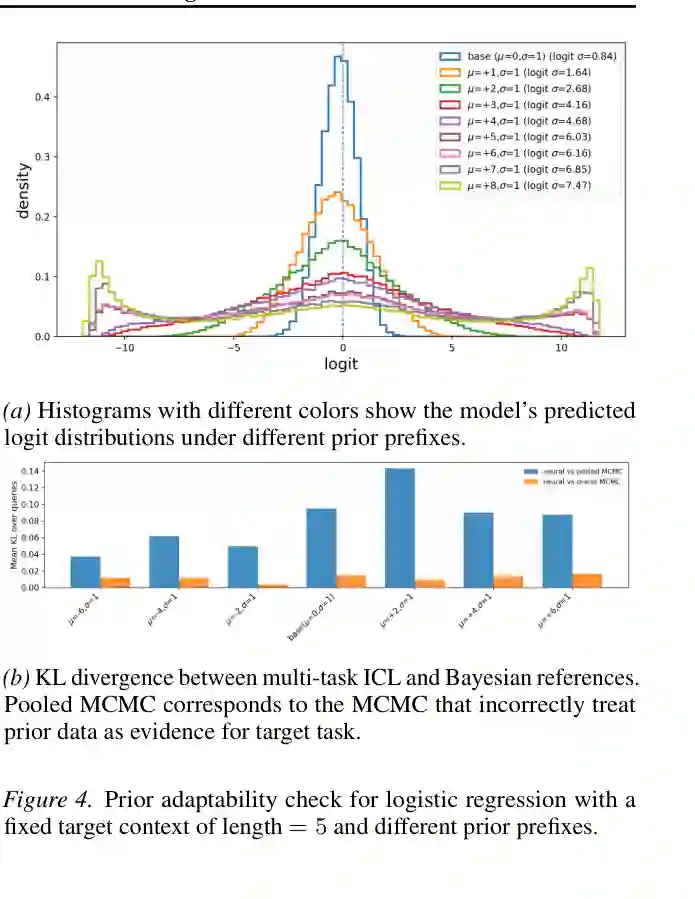
这张图是本文机制验证的核心。它表明模型不是把前缀当成普通训练样本,而是在学习一种“先验上下文条件化”:前缀描述 episode 的先验结构,target evidence 描述当前任务的观测证据,两者在预测中扮演不同角色。
6. 主要结果三:在 OoMD 重尾先验下保持可解释泛化
为了测试先验分布偏移,作者使用 Student-t 先验,并系统改变自由度。自由度越小,尾部越重,统计推断也越困难。训练时的元分布覆盖某些重尾程度,测试时则扫描更广的先验范围,包括 in-meta-distribution 和 out-of-meta-distribution 区域。
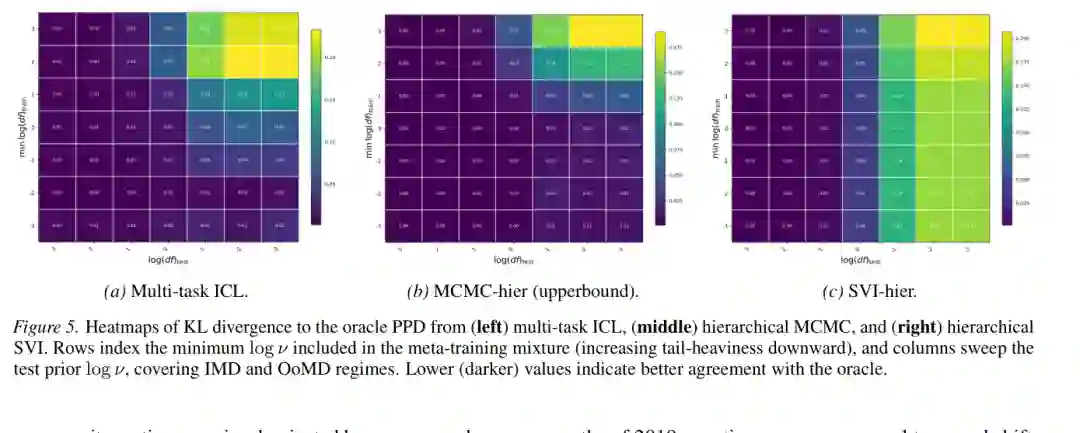
结果有两点值得注意。 第一,multi-task ICL 在训练元分布覆盖较充分时,可以在广泛测试先验上保持较低 divergence,并且表现模式与层级 MCMC 相似。这说明模型学到的是可推广的层级贝叶斯推断机制,而不是只拟合某个窄先验族。 第二,当测试先验进入更极端的重尾区域时,泛化会出现清晰阈值:训练混合分布需要包含足够重尾的成分,模型才能可靠外推到对应测试区域。这种退化不是随机失败,而与统计问题本身的难度一致。
7. 主要结果四:高维 flow 先验下速度优势明显
现实先验往往不是一个低维标量可以描述的。论文进一步构造 flow-based prior,用 normalizing flow 把高斯基础分布变换成高维、非高斯、有结构的任务分布。这里的潜变量更复杂,传统 MCMC 的采样代价也更高。
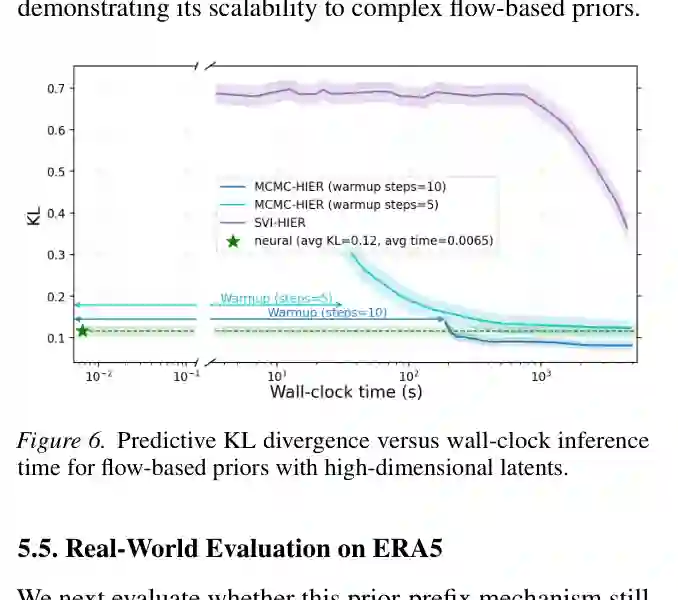
结果显示,multi-task Bayesian ICL 可以用极短推理时间达到接近 Bayesian baseline 的预测质量。MCMC 即使最终可以收敛,仍然受 warmup 和逐样本采样成本限制;SVI 也需要优化过程。相比之下,神经模型把推断摊销到训练阶段,测试时只需前向传播。 这也是本文的实际价值所在:它不是替代贝叶斯推断的理论定义,而是把“可控先验 + 近似后验预测”变成一种低延迟推理机制。
8. 真实数据:ERA5 时空温度预测
论文最后在 ERA5 气候数据上做真实世界评估。任务是根据纬度、经度、时间和海拔等信息预测地表气温。这里的数据噪声更真实,潜在结构也不清晰;prior datasets 来自同一空间区域但不同时间窗口,目标任务则来自另一个时间段。
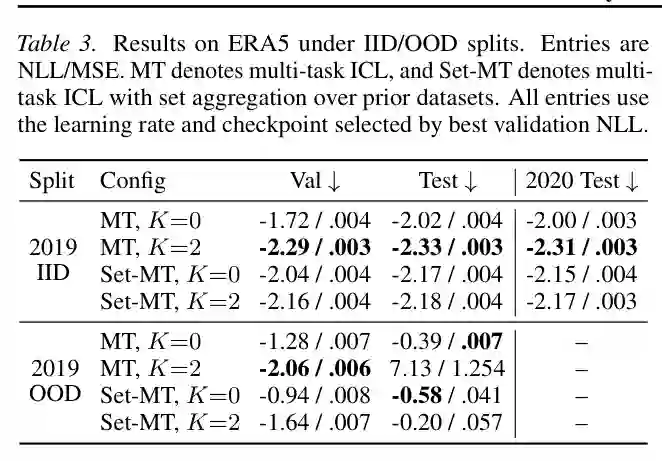
在 2019 IID split 中,使用 K=2 prior datasets 的 MT 模型在验证、测试和 2020 测试上都优于 K=0,说明当训练/测试覆盖相近季节结构时,辅助 prior context 能帮助模型利用跨数据集相关性。 在更困难的 2019 OOD split 中,结果更复杂:一些设置下 prior prefix 改善验证表现,但也可能在测试上失效。这与作者的分析一致:如果验证分布和测试分布发生季节性错位,模型依赖的相关性可能在测试时不再成立。尽管如此,prior prefix 仍显示出对时空结构建模的潜力,尤其是在真实环境中可用少量相关历史数据作为上下文先验时。
9. 方法意义:给摊销推断一个可控先验入口
本文最重要的贡献不是提出一个更大的 Transformer,而是重新组织 ICL 的输入语义:上下文不只包含 target evidence,也可以包含用于表达 prior 的数据化前缀。 这种设计有几个启示:
- ICL 可以被用作层级贝叶斯预测引擎。模型通过 prefix 估计 episode-level prior,再结合 target data 做预测。
- 先验不必以公式或参数形式输入。只要能收集到与先验共享结构的辅助任务数据,就可以把它作为 prior context。
- 测试时适应不一定需要微调。换一组 prior datasets,就能改变模型的预测倾向。
- 神经摊销推断可以与传统贝叶斯 oracle 对齐,而不只是追求任务指标。
在应用层面,这种机制适合那些“先验随场景变化,但每个场景可提供少量相关历史数据”的问题。例如个性化医疗、药物发现、环境预测、金融风险、用户行为建模等场景,都可能把相似患者、相似区域、相似分子或相似用户的历史观测作为 prior prefix。
10. 局限与后续方向
作者也指出了方法的局限。 第一,Transformer 的注意力成本随序列长度二次增长。Multi-task ICL 把多个 prior datasets 和 target dataset 拼进同一上下文,计算成本会随任务数和样本数增长。 第二,当前模型没有显式保证置换不变性。数据集本质上是集合,但 Transformer 接收的是序列。论文附录中显示模型对排列的敏感性较小,但这仍不是架构层面的严格性质。 第三,真实世界中 prior prefix 的质量会影响结果。如果前缀数据与目标任务共享的结构在测试阶段不再成立,模型可能把错误相关性带入预测。这一点在 ERA5 OOD split 中已经有所体现。 第四,本文主要在受控合成任务和一个环境数据任务中验证。未来还需要在更大规模、更高维、更异质的真实任务上测试,例如临床预测、因果结构变化、复杂多模态观测和跨域科学建模。
11. 小结
《Multi-Task Bayesian In-Context Learning》提出了一个简洁但很有解释力的思路:把先验从模型权重中解耦出来,以 prior datasets 的形式放进上下文前缀,让 Transformer 在测试时显式适应不同先验。 实验表明,该方法在高斯、逻辑回归、重尾 Student-t、flow-based 高维先验和 ERA5 真实数据上,都展现出接近贝叶斯 oracle 的预测质量、对 prior shift 的可解释泛化,以及相比 MCMC/SVI 的显著推理效率优势。 如果说传统 ICL 更像“给模型一些样例,让它猜当前任务”,本文则进一步把任务上下文拆成两层:一层描述当前环境的先验,一层描述目标任务的证据。这个结构化视角,使上下文学习更接近可控、可解释、可迁移的贝叶斯推断。
