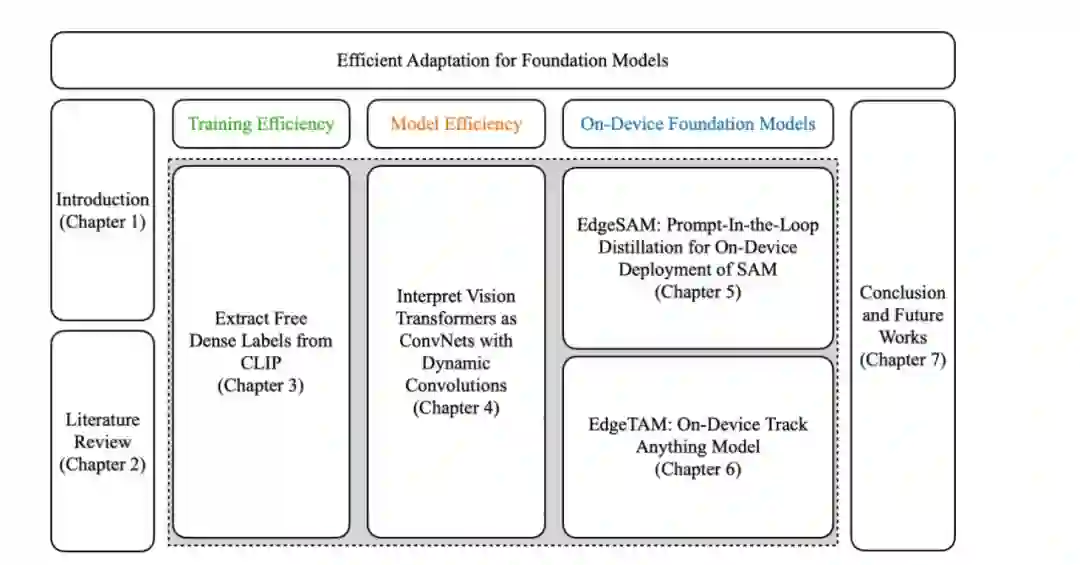
基础模型已成为计算机视觉和自然语言处理领域的一种强大范式,通过在海量多样化数据上进行大规模预训练,实现了极强的泛化能力。通过学习丰富且可迁移的表征,这些模型能够在统一的框架下处理广泛的下游任务。然而,其广泛应用仍受限于若干效率挑战,包括将预训练模型适配至新任务的高昂成本、常用骨干架构的计算低效,以及在资源受限设备上部署此类模型时难以承受的推理需求。
本论文从三个互补的视角研究了基础模型的效率问题。首先,为提升训练效率,我们提出了 MaskCLIP。这是一种视觉-语言模型 [1] 的轻量化适配方案,能够在不依赖人工像素级标注监督的情况下实现密集预测。通过保留预训练 CLIP 模型原始的视觉-语言对齐特性,并利用弱监督与间接监督,MaskCLIP 在保持对未知概念强泛化能力的同时,显著降低了标注成本。
其次,为提升模型效率,我们对卷积神经网络(CNN)与视觉 Transformer(ViT)提出了统一的解释。该视角深入分析了两者各自的归纳偏置、缩放行为(Scaling behavior)及计算特性,并阐明了这些架构在效率与性能之间的权衡关系。基于此解释,本论文分析了基于 Softmax 的注意力机制等核心组件的作用,并证明了替代设计如何在不牺牲精度的情况下实现更高的效率。
最后,为实现部署效率,我们开发了 EdgeSAM 和 EdgeTAM。通过架构重构与任务感知蒸馏(Task-aware distillation),我们将大型分割基础模型 [2, 3] 蒸馏为适用于移动端和边缘设备实时推理的轻量化变体。这些模型在大幅降低延迟和内存占用的同时,保留了其大型对应模型所具备的交互式与通用化能力。 在多个基准测试上的广泛实验表明,所提方法有效降低了标注成本,提升了计算效率,并使基础模型在设备端的实际部署成为可能。综上所述,这些贡献推动了基础模型在现实世界计算机视觉应用中的高效适配与部署。