
导读
这篇综述系统梳理了一个正在快速形成的新方向:AutoResearch,即由AI参与乃至主导科学研究工作流的自动化研究体系。它关心的不是单点任务上的“AI写论文”或“AI做实验”,而是把科学研究拆解为文献与研究依据、假设形成与计划、实验与工具使用、反馈验证与评审、报告与知识传播五个阶段,再考察AI在这些阶段中能够承担多少控制权、执行权与验证权。 论文最重要的贡献,是给出了一个五级自主性谱系:从完全人工研究的L0,到人类主导AI辅助的L1,再到人类验证AI执行的L2,进一步到AI主导人类辅助的L3,以及远期的AI自主研究L4。作者强调,当前大多数系统仍集中在L1-L2,L3和L4更多是未来目标,而不能被简单等同于现有LLM代理流水线。 这篇综述值得关注的原因在于,它把AutoResearch从“模型能力展示”拉回到“科学工作流基础设施”的问题:AI系统是否能形成可追踪证据、能否设计可执行实验、能否被可靠验证、能否保留数据与代码溯源,才是研究自动化能否真正进入科学实践的关键。
Abstract / 摘要
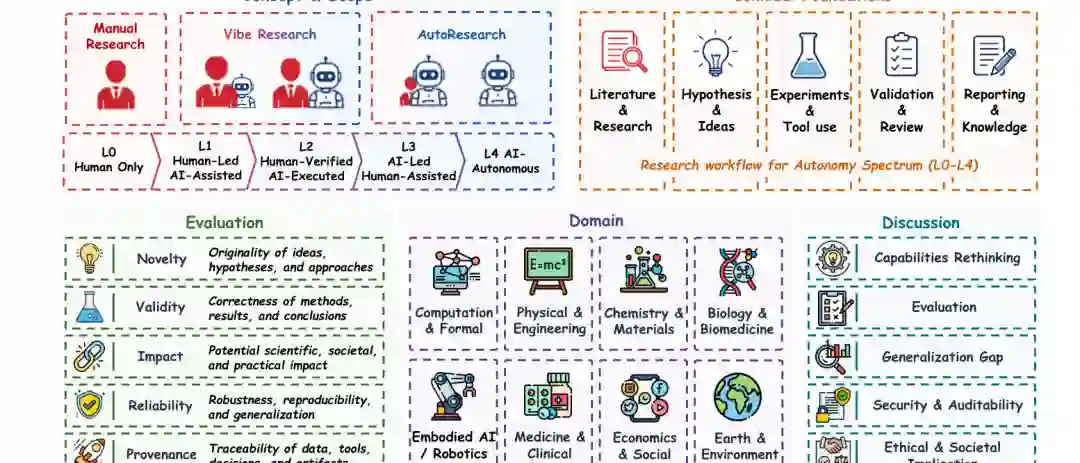
科学研究正被那些超越孤立辅助、迈向更长程工作流——涵盖文献依据、假设生成、实验、验证、报告和修订——的AI系统所重塑。这一转变标志着从任务级AI for Science向工作流级研究自动化的过渡。然而,该领域仍然碎片化:现有系统在自主性、领域范围、执行环境、验证机制和对人类监督的依赖程度上差异显著。虽然许多系统能够生成合理的想法、操作工具、运行有界实验或生成精致的产物,但它们在证据保存、可复现性、弱方向拒绝、溯源追踪、跨领域鲁棒性和可负责科学闭环方面仍面临持续挑战。 本综述通过"AutoResearch"的视角审视这些发展,我们将其定义为AI驱动科学工作流自动化的演化谱系。在这个谱系中,"Vibe Research"指的是人类引导的区域,AI通过基于提示的辅助和人类验证的执行来扩展局部研究能力,而新兴的AI主导系统开始协调更大范围的发现环路,但尚未实现稳健的自主性。我们并未仅根据模型家族、智能体架构或基准性能对先前工作进行分类,而是分析研究系统如何在整个科学工作流中重新分配控制权、证据、执行、验证和问责。我们围绕五个重复出现的工作流条件来组织AutoResearch的技术基础:文献与研究依据、假设形成与计划、实验与工具使用、反馈验证与评审、以及报告与知识传播。我们进一步综合了AI科学家系统、混合主动协同研究框架、基准生态系统、特定领域部署和开源基础设施。 为了评估进展,我们提出了五个评估维度——新颖性、有效性、影响力、可靠性和溯源——将关注点从仅任务完成转移到工作流级输出的科学可信度。我们的分析表明,AutoResearch的实际天花板具有强烈的领域条件性:在研究成果是结构化、可执行且可快速验证的环境中,更高的自主性目前更可信;而在科学声明依赖于具身实验、延迟验证、异质证据、伦理约束或制度问责的领域中,则受到更多限制。通过连接概念边界、技术基础、评估逻辑和领域条件性的自主性天花板,本综述厘清了AutoResearch的当前图景,并确定了值得信赖的AI参与科学探究的要求。
1 Introduction / 引言
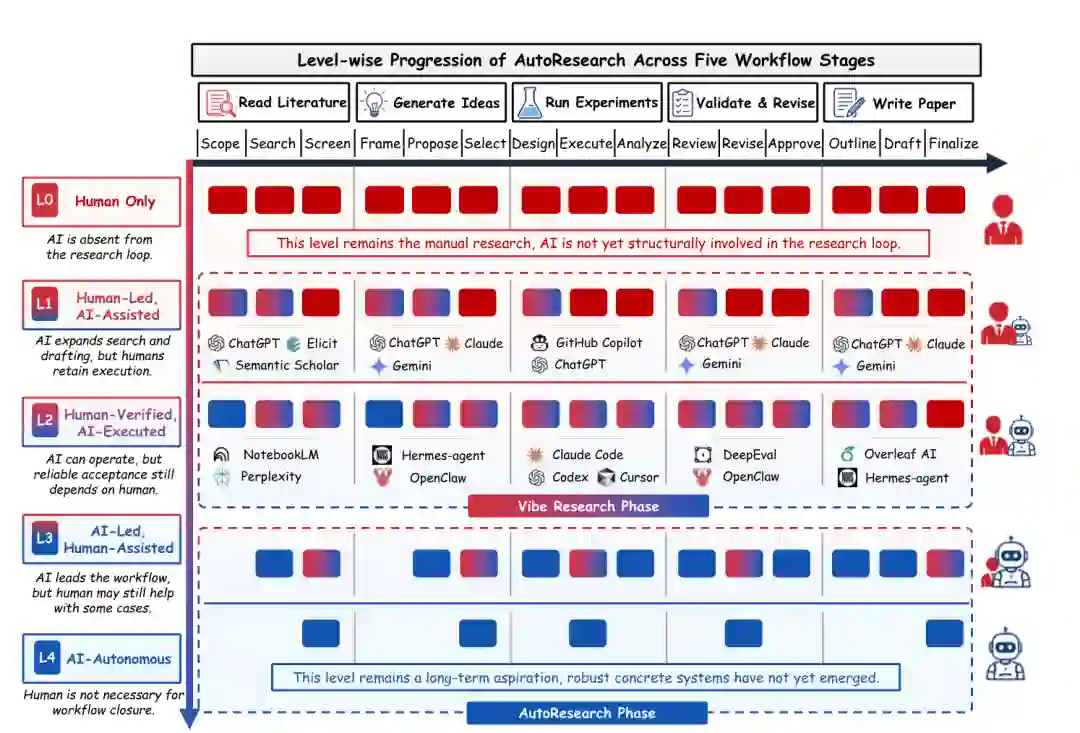
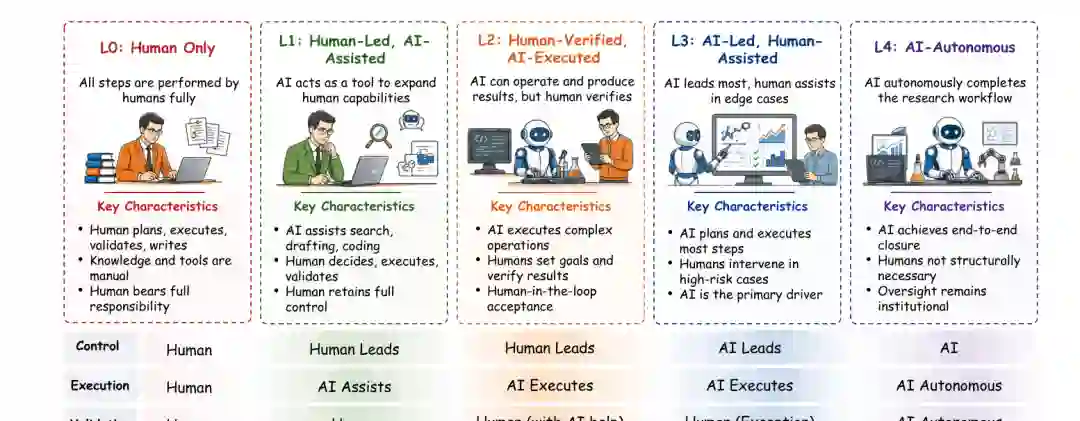
- 我们提供了一个AutoResearch作为工作流级科学自动化的概念框架。 我们将AutoResearch定义为一个工作流级范式,其中AI参与科学探究的组织、执行、验证和传播,而非一组孤立的AI for Science工具或独立研究智能体。我们引入了从L0到L4的五级自主性谱系,并区分了L1–L2的人类引导"Vibe Research"区域和L3–L4的更严格AutoResearch前沿。该框架通过分离有界辅助、人类验证的AI执行、管线自动化和成熟的AI主导的科学自主性,为比较当前系统提供了一套保守的词汇。它还有助于避免将更广泛的工作流覆盖等同于可靠的自主研究闭环。
- 我们围绕五个工作流条件发展了AutoResearch的技术分类。 我们围绕五个重复出现的工作流条件组织AutoResearch的技术基础:文献与研究依据、假设形成与计划、实验与工具使用、反馈验证与评审、以及报告与知识传播。该分类学阐明了当前系统如何在研究工作流中重新分配科学工作,从证据构建和想法选择到执行、拒绝、修订和产物生成。它进一步表明更强的自动化不仅需要有能力模块,还需要在证据、计划、环境、验证机制和可传播的研究产物之间建立持久耦合。通过此视角,不同的研究智能体、AI科学家系统和工作流基础设施可以在共同的技术框架内进行比较。
- 我们综合了AutoResearch的评估原则和领域条件性自主性极限。 我们围绕工作流级科学可信度的五个维度组织AutoResearch评估:新颖性、有效性、影响力、可靠性和溯源。这些维度将关注点从系统能否完成任务转移到其研究输出是否原创、正确、有用、可复现和可在工作流中追溯。我们进一步分析了自主性天花板在不同领域之间的差异,表明更强的自动化目前在对执行和审计友好的环境中更可信,如计算和形式科学,而具身、延迟、异质或高风险领域则更受限于验证、安全、不确定性和问责要求。这种领域条件性的视角解释了为何向自主研究的进展在科学各领域是不均匀而非统一的。
论文组织。 本综述的其余部分组织如下。第2节从历史和概念角度介绍AutoResearch,阐明其范围、边界及与AI for Science和研究自动化相邻分支的关系。第3节通过科学发现环路的各主要组成部分检查其技术基础,包括文献依据、假设生成与计划、实验与工具使用、验证和报告。第4节发展了一个以新颖性、有效性、影响力、可靠性和溯源为中心的统合评估视角,并将当前基准、审计工具和评估实践置于该框架内。第5节分析了AutoResearch的实际天花板如何在主要科学领域之间不同,强调了为何工作流可移植性在实践中仍然有限。最后,第6节讨论了能力边界、评估差距、领域泛化局限、可靠性、审计性以及AutoResearch的伦理和社会影响。
2 Overview of AutoResearch / AutoResearch概述
自动研究的历史
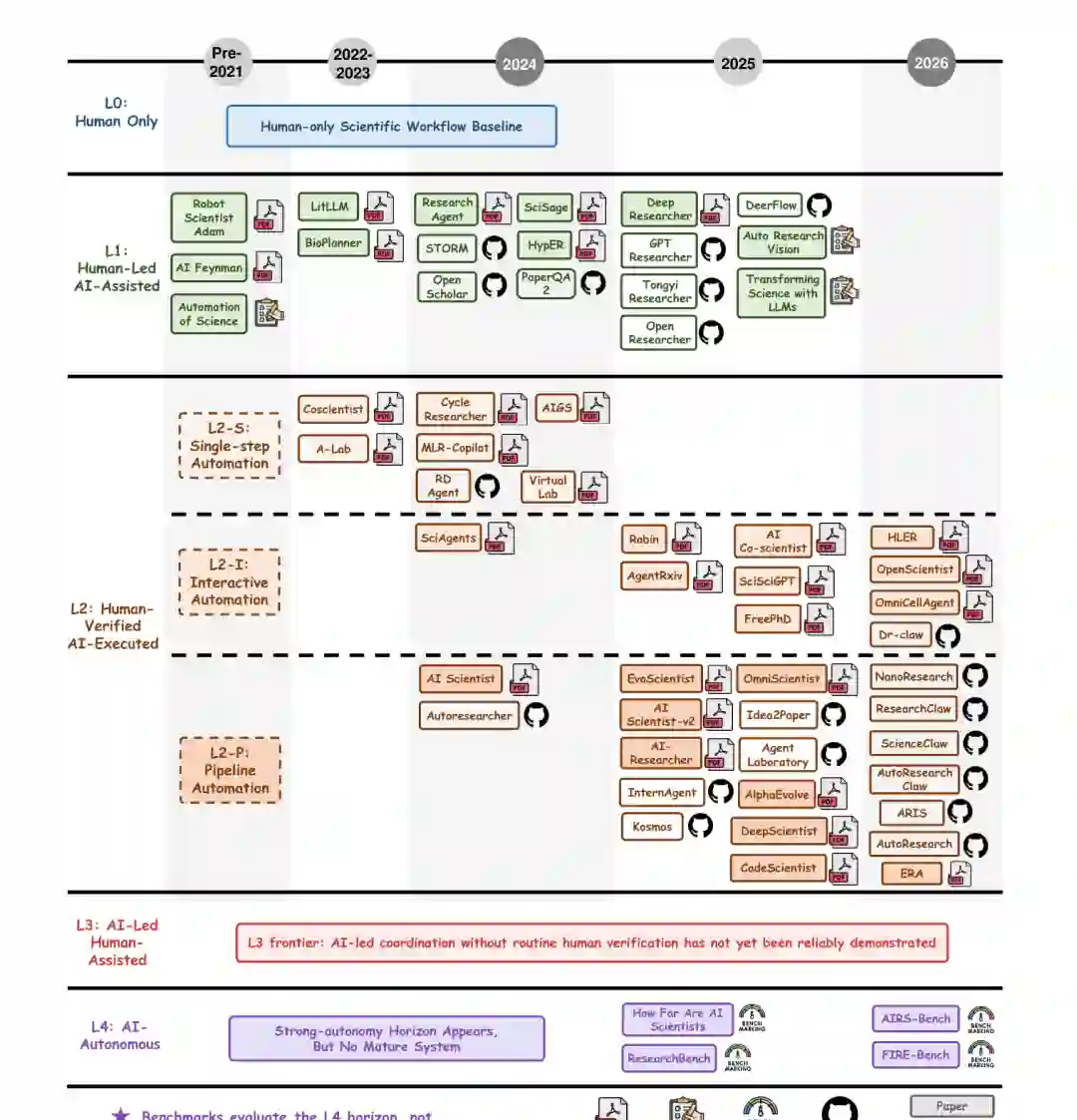
- 作为基准线的人类中心科学实践。 在研究自动化成为技术议程之前,科学探究围绕人类的问题构建、文献解释、假设构建、实验设计、证据评估和面向共同体的传播来组织。经典的科学发展框架通过猜想与反驳、范式引导的探究与断裂以及稳定知识声明的共同体规范来定位这一机制。战后科学传播的扩展扩大了发表、协作和机构评审的规模,但并未将科学闭环从人类研究人员和研究共同体手中重新分配。在时间线上,这表现为人类唯一的科学工作流基准线:一个参照点,后来自动化改变了搜索、执行、验证和报告的分配,而没有立即替换科学判断。
- 辅助、领域框架与知识工作自动化。 AutoResearch的第一个持久层出现在科学知识工作变得可搜索、可综合和部分可形式化时。早期锚点如Robot Scientist Adam和AI Feynman展示了在有结构的环境中,如自动化假设测试、符号恢复或约束科学空间上的推理,发现的选择性组件可以被自动化,而更广泛的对科学自动化的讨论将自动化定位为一个工作流级问题。随着语言模型的兴起,如BioPlanner和LitLLM等系统将这一层转向协议推理和以文献为中心的研究支持。到2024年,检索和综合导向的系统,包括Research Agent、STORM、OpenScholar、SciSage、HypER和PaperQA2,使基于依据的搜索、多视角综合、假设支持和基于论文的问答成为稳定的辅助工作流的一部分。STORM,例如,明确是一个用于基于依据的长篇写作的检索和多视角提问系统,而非执行性研究智能体。到2025–2026年,Deep Research Arena、GPT Researcher、Tongyi Researcher、Open Researcher和DeerFlow,连同Auto Research Vision和Transforming Science with LLMs等定位性工作,巩固了AI作为科学工作中一种重复出现的认知和组织层。历史上,这一L1层提高了研究吞吐量和组织能力,但它并未将执行权或科学闭环从人类研究人员处转移。
- L2-S:单步自动化执行。 下一个历史性转变发生在AI系统开始执行有界科学操作而非仅支持知识工作时。我们将这一机制描述为L2-S,或单步自动化执行。该层的系统可以执行明确定义的操作,如工具调用、代码执行、协议实施、实验室控制、模型训练、数据驱动分析或有界实验支持。Coscientist将语言模型连接到化学中的搜索、代码执行、实验室文档和实验自动化,而A-Lab展示了通过计算、历史或文献推导知识、主动学习和机器人执行的自主材料合成。两者扩展了执行能力,但处于受控科学领域而非通用研究工作流中。到2024年,CycleResearcher、MLR-Copilot、RD Agent、AIGS和Virtual Lab将有界执行扩展到计划、实施、修订和虚拟实验环境。这一层的定义性质不是完全的工作流自主性,而是在约束目标、受控设置和外部验证下,选择的可执行任务从人类向AI的转移。
- L2-I:交互式工作流自动化。 第二种L2模式随着系统开始通过交互、反馈和混合主动控制支持多步工作流而出现。我们称这一机制为L2-I,或交互式工作流自动化。与执行有界操作的L2-S系统不同,L2-I系统帮助在几个研究行动中维持进展,同时依赖人类反馈、引导或接受。SciAgents将执行从简单的工具使用扩展到多智能体推理和结构化科学表现上的科学构思。2025–2026年浪潮进一步拓宽了这一层:AI co-scientist、SciSciGPT、FreePhD、Robin和AgentRxiv通过协作构思、反馈、代码或数据驱动实验、论文生成和研究生产,向更强的混合主动协同研究推进。HLER、统计遗传学的AI co-scientists和Dr-claw进一步将此模式扩展到经济学、遗传学、生物医学分析、细胞研究和项目级辅助。
- L2-P:人类验证下的管线自动化。 当前填充最强的层是L2-P:人类验证下的管线自动化。该机制中的系统连接多个研究阶段——如文献依据、构思、实施、实验、分析、评审和写作——在更长的操作环路内部。The AI Scientist通过将想法生成、代码编写、实验执行、图表制作、论文起草和模拟评审耦合到一个端到端的研究框架中,使这一方向尤为可见,同期的Autoresearcher也做出了早期工作。到2025年,Idea2Paper、Agent Laboratory、AlphaEvolve、DeepScientist、CodeScientist和OmniScientist通过论文生成、编码、实验管理、多智能体生态系统或更长地平线的研究生产进一步扩展了这一管线视图。AI Scientist-v2、AI-Researcher、InternAgent和Kosmos通过智能体搜索、实验管理、持久研究状态以及文献、假设生成、数据分析和科学报告之间的更紧密耦合,加强了这一前沿。到2026年,NanoResearch、ResearchClaw、ScienceClaw、AutoResearchClaw、ARIS和EvoScientist等开放基础设施进一步将该领域从孤立的研究智能体演示转向可重用工作区、工具丰富的编排、持久项目状态和研究管线基础设施。
- 作为基准化地平线的自主闭环。 最后一层不是一个密集填充的系统类别,而是一个评估前沿。L3仍然是AI主导的研究所需不仅仅是管线广度的点:系统需要能够协调更大的工作流部分,并在无需常规逐级人类验证的情况下生成科学可信的中间和最终输出。当前系统展现出向这一条件的部分压力,但成熟的L3的稳健证据仍然有限。L4仍然更远,需要具有可靠拒绝、验证、溯源、可复现性和问责的自主科学闭环。时间线有意地将成熟系统与抱负性地平线分开:没有当前系统被视为完全自主科学闭环的稳健实例。相反,最近的基准层测量了现有智能体离那个地平线还有多远。How Far Are AI Scientists from Changing the World? 通过将系统抱负与科学影响之间的差距前景化,尖锐化了该领域的瓶颈分析。ResearchBench将科学发现重新定位为一个可分解的基准问题,而AIRS-Bench和FIRE-Bench将评估推向前沿研究智能体和全周期再发现任务。这一阶段在历史上很重要,因为该领域不再仅由日益有能力的系统定义;它也越来越由日益明确的工作流闭环、实施可靠性、证据质量和科学推理测试来定义。
自动研究的当代图景
当代AutoResearch图景并非围绕一个单一的规范架构组织,而是围绕功能性的劳动分工。一层通过文献依据、基于来源的综合、问答、计划和报告构建来稳定知识支持;STORM和OpenScholar等系统通过使检索增强的知识工作更加结构化和持久,体现了这一层。第二层提供执行环境,包括代码智能体、工具使用、实验室接口、受控环境和软件智能体执行。第三层将这些能力连接成更长的研究管线,涵盖构思、实施、实验、分析、论文生成和评审式反馈;The AI Scientist和AI Scientist-v2是代表,因为它们使代码原生的端到端研究环路得以明确。开源项目和基础设施为这些系统提供操作基础,包括软件智能体执行、工具编排、持久工作区和可重用研究环境。因此,该领域通过辅助、执行、交互和管线编排的共同成熟而前进。 表1选择了对当前图景在结构上具有重要性的工作,而非试图进行全面编目。纳入标准是工作流相关性:每个条目要么阐明了AutoResearch的概念边界,引入了可重用的研究支持或执行环境,实现了多阶段研究过程,提供了用于依据、执行、编排或报告的开放基础设施,要么评估了向自主科学闭环的进展。这一选择使该表成为该领域的一个结构图,而非按时间顺序的文献目录。主机制列遵循与图4相同的保守放置规则。 (表1:AutoResearch当代图景中的代表性工作。选定的综述、工作流级系统和开源项目按其在该领域中的结构角色分组。"级别"列指示每个工作的工作流范围、执行能力和人类监督程度所暗示的主要自主性机制,而非普适性能排名。来源:原论文PDF第11页。) 根据这一规则,当前图景集中在L1和L2,最快速的扩张发生在L2内部。基于文献的助手和深度研究系统填充L1;使用工具的有界执行系统和有界实验系统填充L2-S;混合主动协同研究系统填充L2-I;最近的AI科学家系统和非科学家系统大致填充L2-P。这种分布并不会削弱其重要性。相反,它阐明了当前AutoResearch的核心经验故事:该领域正从局部辅助转向集成的人类验证管线自动化,而成熟的AI主导自主性仍然是一个更严格的前沿。 这种分布反映了一种结构性的自主性过滤,而非模型规模的简单差距。AutoResearch在工作流片段模块化、输出可判断、环境可编程且反馈足够快速以支持迭代的领域进展最快。它在科学进展依赖于长地平线协调、领域特定解释、昂贵验证、异质证据、拒绝、溯源或制度问责的领域进展缓慢。因此,当代领域最好被理解为一个分层生态系统:概念框架定义空间,辅助系统稳定知识工作,执行系统扩展AI在研究工作流中的能力,管线系统测试这些组件能在多长的循环中被连接成人类验证的研究环路。
3 Technical Foundations of AutoResearch / AutoResearch的技术基础
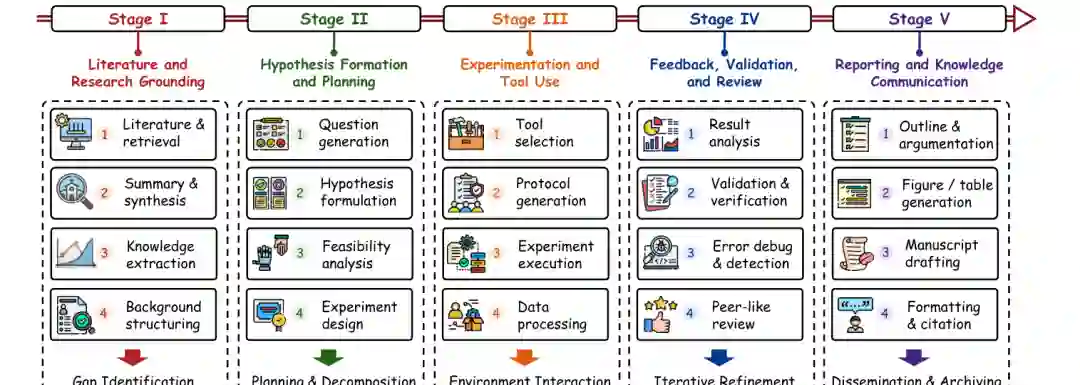
科学自主性的工作流条件
科学自主性取决于研究能力在工作流中如何组织,而非仅取决于单个组件的存在。检索、计划、工具使用、实验、验证和报告现在出现在许多研究导向的系统中,但它们对自主性的贡献取决于它们是否支持基于依据的推理、可执行行动、修订、拒绝和跨阶段的可问责沟通。图5提供了本节采用的工作流视图。因此,我们通过科学工作的五个技术条件——文献依据;假设形成与计划;实验与工具使用;反馈验证与评审;以及报告与知识传播——来分析AutoResearch,而不是通过像单智能体、多智能体、检索增强或工具使用架构这样的系统级标签。 每个条件提供了不同形式的科学约束。依据通过证据约束推理;计划通过可行性和比较约束探索;执行通过环境约束假设;验证通过拒绝压力约束输出;报告通过溯源和产物对齐约束沟通。这些条件共同决定了系统是保持局部助理、成为人类验证执行者,还是在人类验证下支持更广泛的管线级协调。
- 文献与研究依据。 研究自动化首先取决于先前工作如何在工作中被检索、过滤、解释、组织和重用。这一阶段包括搜索、重排、总结、引用处理、证据提取、声明追踪,以及为下游推理构建一个可用的科学上下文。其技术作用是将之后的阶段锚定于可追溯的证据,而非通用模型先验。
- 假设形成与计划。 基于依据的上下文随后必须转化为候选的科学方向。这一阶段包括提案生成、任务分解、可行性评估、优先级排序、分支,以及在执行开始前组织研究备选路径。其技术作用是使候选假设足够有依据、可操作化和可比较,以便于下游测试。
- 实验与工具使用。 科学声明只有在暴露给可执行、计算或经验环境时才获得抗性。这一阶段包括实施、环境调用、工具路由、协议实施、执行时修订,以及处理由代码、工具、模拟器、仪器或实验室设置生成的中间输出。其技术作用是通过将声明与能约束、细化或使之无效的环境耦合,将工作流推离思辨推理。
- 反馈、验证与评审。 单独执行并不产生科学进步,除非输出被检查、挑战、修订或拒绝。这一阶段包括重跑、基线比较、错误检测、不确定性揭示、评审者式批评、验证,以及其他决定结果是否应持续存在的机制。其技术作用是引入拒绝压力,并将较强的结果与较弱的结果区分开。
- 报告与知识传播。 最后阶段将工作流状态转化为可传播的科学产物。它包括起草、修订、图表生成、评审回应、产物打包,以及声明、证据、代码和溯源之间的显式连接。其技术作用是使输出作为科学对象保持可解释、可检查和可重用,而不仅仅是打磨过的文本。
合起来看,这些阶段定义了AutoResearch系统从辅助到执行和集成管线自动化的技术路径。更强的工作流自动化不仅需要检索工具或写作模块的存在;它需要一个工作流,其中依据为计划提供信息,计划指导执行,执行产生证据,验证施加拒绝压力,报告保留溯源和问责。这种耦合也解释了为何当常规人类验证仍然必要时,广泛的管线自动化对于成熟的AI主导自主性仍然不足。以下子节依次分析这些阶段。
阶段一:文献与研究依据
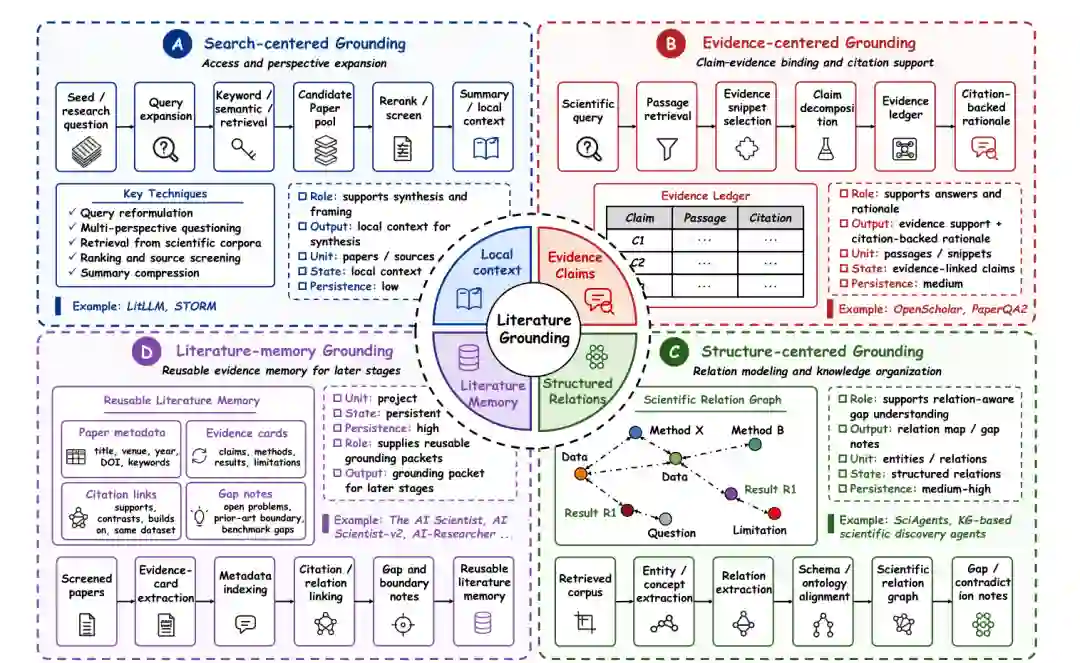
- 1) 搜索中心依据。 这是最轻量也是最广泛的机制。其工作流通常组织为:查询构建 → 检索/重排 → 摘要压缩 → 局部科学上下文构建。LitLLM是这里最清晰的锚点:它从一个查询摘要中检索论文,对其进行重排,并生成一个基于依据的相关工作部分。STORM在多视角模式中遵循类似阶段,通过提出不同角度的深入问题并综合基于依据的书面输出。搜索中心机制的关键限制是后续阶段不能轻易遍历、质疑或拆分到证据层面。上下文主要作为综合和框架的输入,而不能在假设形成、实验设计或验证中系统性地引用或修订。
- 2) 证据中心依据。 更强大的机制是证据中心依据,其中检索输出被处理为明确的证据片段,这些片段被链接到特定声明。工作流通常包括:科学查询 → 段落检索 → 声明分解 → 证据分类账 → 引用支持的推理。PaperQA2是这一方向的代表:它从科学语料库中检索段落,提取证据性的支持或反驳,并将这些证据分类账链接回源段落以支持基于引用的答案和推理。OpenScholar遵循类似的证据中心结构,结合了检索、重排和声明级证据集成,以进行基于文献的综合和问答。与搜索中心机制相比,核心区别在于工作流状态包含了明确的、可引用的单位知识,支持下游系统输出引用支持的推理而非仅基于来源综合的文本。它还包括指向原始文献源的跟踪,通过减少不基于证据的声明来提高工作流的可审计性。
- 3) 结构中心依据。 证据中心机制提升到关系级理解。搜索中心机制检索文档,证据中心机制构建声明-证据对,而结构中心机制将文献提取为关系网络。工作流包括:检索语料库 → 实体/概念提取 → 模式/本体对齐 → 科学关系图 → 空白/矛盾说明。这些关系可以是方法-数据集-结果三元组、基准性能比较、间隙-局限性对应,或跨论文的声明关系(如支持、对比、构建于、使用相同数据集)。SciAgents通过跨论文结构化关系使关系提取成为假设构成和构思的一部分。结构中心机制提供了在概念层次探索文献的能力,识别跨多个来源的间隙、矛盾、迁移和依赖关系。然而,在实践中,关系的忠实性和覆盖范围仍有限,特别是在高度专业化和快速演进的科学子领域。
- 4) 文献记忆依据。 结构中心机制延伸到文献记忆,其中经过筛选的论文、证据卡片、关系、间隙和边界说明被巩固成一个可重用的知识库。工作流框架包括:筛选论文 → 证据卡片提取 → 元数据/引用链接 → 间隙和边界说明 → 可重用文献记忆。文献记忆在跨多个工作流运行或阶段的研究中特别有价值,因为依赖经常重复。The AI Scientists、AI Scientist-v2和AI-Researcher将文献记忆构建为持久结构,用于构思、实验管理和论文写作。文献记忆机制的关键优势在于下游阶段可以逐步依赖累积的结构;证据不会随每次查询重新开始。然而,维护、更新和保持证据完整性在跨论文和跨时间运行时仍构成重大挑战。
阶段二:假设形成与计划
假设形成和计划是AutoResearch的第二个主要技术阶段,因为基于依据的上下文必须转化为候选科学方向,这些方向足够具体以指导行动,但也足够灵活以允许搜索、比较和修订。当前的系统在假设来源、表示和生成过程方面差异显著,产生了四种反复出现的机制:基于检索的假设生成、基于结构理解的假设生成、基于约束优化和执行的计划生成、以及可验证假设生成的集成循环。
- 1) 基于检索的假设生成(假设作为文献综合)。 机制一是假设通过新的、基于文献的综合隐含产生。假设没有以声明形式明确表示,而是通过研究总结隐含形成。虽然看似简单,但这种方法在高度动态或快速变化的领域中有实际用途,其中即使当前边界是什么的简单综合也提供了有用的新视角。然而,这种机制将假设生成与验证和实验耦合在一起,使得实验设计和假设测试与文献综合难以区分。
- 2) 基于结构理解的假设生成(假设作为图间隙)。 机制二以结构理解编码假设。输出是在关系网络中标记、识别或基于全局属性的间隙。SciAgents跨论文运行关系提取以生成关系图,然后通过概念级推理识别间隙区。结构中心假设生成提供了更明确的理由:为什么一个假设是新颖的,它可以被关系图中的间隙所支持。然而,间隙识别方法往往受益于额外的领域知识和详细的覆盖范围,以避免过低分量的新颖性声明。
- 3) 基于约束优化和执行的计划生成(假设作为可执行计划)。 机制三将假设主要编码为可执行计划。假设被编码为潜在的行动序列,每个行动旨在提取受控结果。HypER是这种方案的代表,它产生基于文献的假设、实验细节和预期结果。Agent Laboratory代表了工作流级计划模板的兴起:系统分解任务并产生可执行计划,然后由下游执行环境消耗。在这种机制中,假设形式化是一个挑战:并非所有方向的约束都是预先设定的。
- 4) 可验证假设生成的集成循环(假设作为可测试且可验证的方向)。 机制四将假设生成与测试和验证循环耦合起来。The AI Scientist-SP (科学协议) 是一个代表:它首先生成基于科学文献的假设,然后指定可执行的实验计划,然后通过代码和模拟器执行实验。AI Scientist-v2通过基于证据的评估和世界奖励的明确过滤器进一步扩展了这一循环。这种方案将假设生成定位为连接所有后续阶段(从依据到实验到验证到报告)的核心循环。
阶段三:实验与工具使用
实验和工具使用是AutoResearch的第三个主要技术阶段,因为科学主张只有通过暴露于计算或经验环境才能获得说服力,让研究人员比较指标、检验错误并修正或拒绝方向。当前系统在环境的复杂性、工具的范围、自动化的程度以及与环境失败的处理方式上差异显著。
- 1) 代码执行驱动实验。 最成熟的实验环境形式是代码执行。这是许多AI for Science系统的基础,因为代码提供确定性的、可重放的中间输出。测量自动化程度的有用方法是将这些系统映射到代码执行能力的层级上:原始代码接口(将代码视为高级文本生成)、单步代码执行(计划-执行-观察循环)、多步代码执行(多个代码和工具与条件逻辑链接在一起)、完整的环境交互(通过容器化环境进行多步骤实验)。
- 2) 物理代理和机器人实验。 物理代理实验在化学、生物学和材料科学等需要物理操作的领域中尤为重要。这些系统连接了LLMs,机器人硬件和传感器输入,允许AI系统在实验室环境中提议和执行实验,但通常仍处于人的监督下。
- 3) 虚拟实验室和模拟。 虚拟实验室环境,如Virtual Lab,允许在运行实验之前模拟实验。这些环境降低了运行昂贵或危险实验的风险。例如,Coscientist在化学领域使用了一个虚拟实验室来模拟化学实验,从而避免了物理限制。
阶段四:反馈、验证与评审
反馈、验证和评审是AutoResearch的第四个主要技术阶段,因为仅靠执行并不能带来科学进步,除非输出也经过检查、挑战、修订或拒绝。这个阶段至关重要,因为它引入了拒绝压力,并将科学工作流从简单的输出生成转变为自我纠正的循环。当前系统在这个领域表现最弱,主要瓶颈包括:缺乏严格的验证方法、缺乏对正确结果的稳健判断、对薄弱方向的持久拒绝做得不够,以及对自我纠正的过度依赖。
- 1) 执行时自我纠正。 最即时的验证形式是执行时自我纠正,其中系统自动检测错误并发起纠正。这通常通过运行时环境、代码解释器和模拟器的反馈发生。对于代码相关任务,这是一个相对成熟的方向,许多编码代理(如OpenHands)都包含冗余的运行时验证作为工作流的一个正式步骤。
- 2) 反思和弱点检测。 反思框架明确地执行自我验证步骤,其中模型生成对自身输出的批评。虽然这种方法对语言模型在更广泛任务上的性能产生了可测量的改进,但在科学研究背景下其局限性逐渐显现。模型生成的反思倾向于接受结构上可靠但不一定在科学上有说服力的结果。
- 3) 科学评审。 更复杂的机制试图模拟同行评审过程本身。The AI Scientist包含一个自动评审者,评估论文的新颖性、有效性和清晰度。然而,在这些系统中,自动评审的可信度仍然是一个开放性挑战。
阶段五:报告与知识传播
报告和知识传播是AutoResearch的第五个主要技术阶段,因为科学工作流程的最终产品是传播性产物:论文、报告、演示文稿和数据集。这一阶段的目标是将工作流状态转换为可传播的科学产物,这些产物对读者保持有意义、可解释和可操作。
- 1) 基于模板的论文生成。 最简单的写作方法越来越多地包含自动论文起草。许多AutoResearch系统使用预定义或脚本化的论文结构,根据从早期阶段提取的数据填充部分。这允许快速生成结构化文档,但灵活性有限。
- 2) 根据研究状态生成文本。 更灵活的系统根据完整的研究状态(数据、图、源代码、运行日志、结果)起草手稿。AI Scientist-v2使用这种端到端方法,在实验和验证后起草完整手稿、参考文献和图表。
- 3) 对同行评审的修订和响应。 传播的最后一英里涉及准备手稿以供正式提交、对同行评审的回应以及复制。像Robin、Kosmos等系统开始整合这些功能。
4 Evaluation of AutoResearch / AutoResearch的评估
评估AutoResearch不仅是测量任务完成程度,还要评估工作流程的稳健性、产出的质量和科学发现过程的可靠性。
自动研究谱系中的评估负担
评估负担随着工作流程步调而增加。L1辅助系统的评估相对简单:它通常测量速度和准确性。L2系统的评估开始强加特定工作流程的功能:执行的正确性、代码的可用性以及编译文档的准确性。然而,L3和L4系统的评估越来越评估科学成果:产出假设的新颖性、实验的有效性、结果的可靠性和工作流程的可追溯性。
科学质量与自主性评估
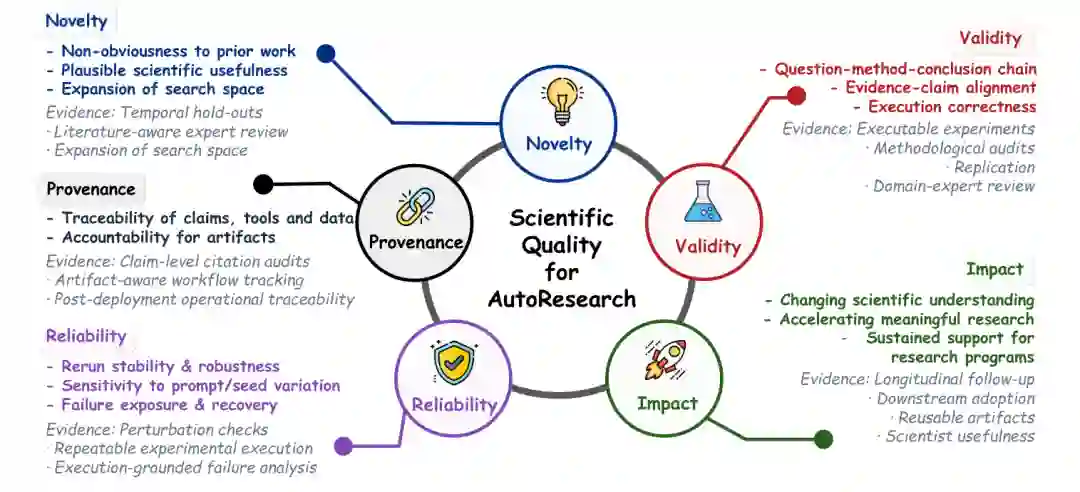
- 新颖性(Novelty): 想法、假设、方法和方法的原创性。评估系统的产出是否在真正推进知识边界。
- 有效性(Validity): 方法、结果和结论的正确性。评估产出的科学正确性。
- 影响力(Impact): 成果在科学、社会和实践应用中的潜在或实际影响。评估产出的有用性。
- 可靠性(Reliability): 系统在不同运行、环境和条件下产生可重复结果的稳健性。评估系统是否一致且稳定。
- 溯源(Provenance): 数据、工具、决策和成果的可追溯性。评估产出是否可审计和可理解。
这些维度不是独立的任务指标,而是共同评估工作流级产出的科学完整性。它们还提出了不同科学领域之间不同的门槛要求。
评估工具与基准图景
AutoResearch的基准和评估基础架构正迅速增长,以跟上能力的提升。虽然该领域缺乏一个通用的工作流基准套件,但出现了几个有影响力的工具。
- ResearchBench: 将科学发现重新定义为一系列可分解的基准任务。它包括项目规划、基准选择、实验执行和结果分析等任务。
- AIRS-Bench: 将评估推向综合型研究智能体。它包括跨不同科学领域的规划、工具使用和推理基准。
- FIRE-Bench: 专注于全周期再发现任务。它评估系统从数据和文献到发现和验证的循环能力。
- How Far Are AI Scientists from Changing the World? 这个视角尖锐化系统抱负和科学影响之间的差距,并定义新的基准来测量科学影响。
5 Domains of AutoResearch / AutoResearch的领域
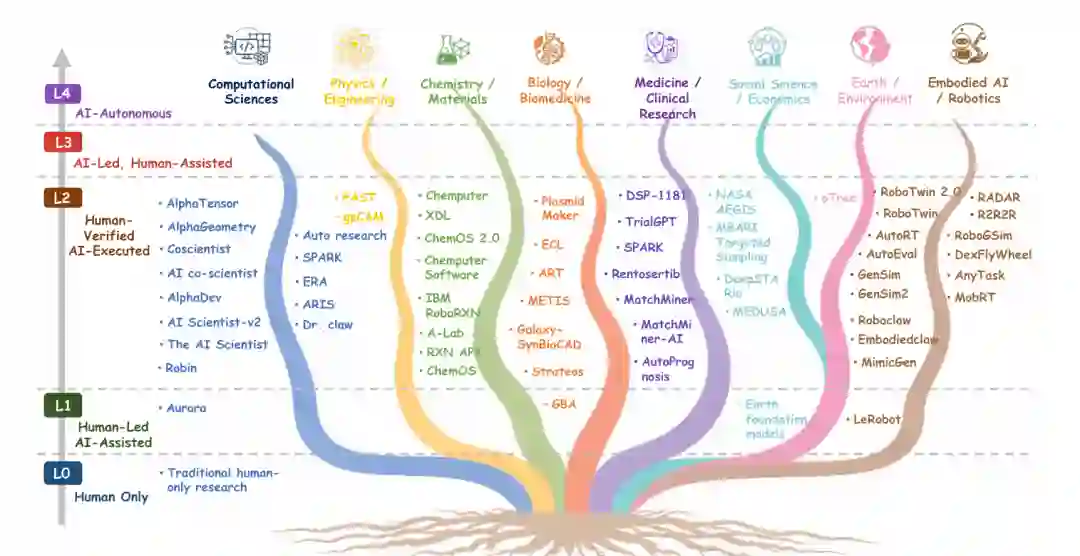
计算与形式科学
计算和形式科学包括计算机科学、统计学、数学等领域。这些领域是AutoResearch目前最成功的领域。这些领域的产物本质上通常是可执行的:想法、程序、代码、仿真、证明、形式逻辑。这允许快速、自动化的验证和迭代。Reprozip、OpenHands、SWE-agent 等系统展示了高度可靠的单步和多步执行。因此,这些领域的系统可以达到L2-P甚至L3的迹象。关键优势在于自动化反馈循环。
物理科学与工程
物理科学与工程包括物理学、机械工程、土木工程等领域。这些领域面临更高的延迟反馈。物理实验往往更慢、更昂贵,并且更难完全数字化。机器人实验室和自动化实验平台如A-Lab展示了有限的自动化,但通常仍需要大量的人类设计和验证。这些领域目前主要处于L2-S和L2-I。
具身智能
具身智能,特别是指机器人学和自主系统,向AutoResearch提出了独特的挑战。这些领域依赖于现实世界的物理交互,这需要感官反馈、执行器协调以及对不确定环境的鲁棒性。目前,研究主要集中在L1和L2-S级别。
化学与材料
化学和材料科学是AutoResearch增长最快的领域之一。机器人实验室(如A-Lab、Coscientist)展示了在机器人硬件和AI引导下的自主合成。这些领域正从L2-S快速过渡到L2-P。
生物学与生物医学
生物学和生物医学显著受益于AutoResearch,特别是在基因组学、蛋白质组学和药物发现领域。AlphaFold在此产生了重大影响。然而,验证和反馈延迟很高,特别是涉及湿实验室实验。这些领域目前主要处于L1和L2-S。
医学与临床研究
医学和临床研究受伦理和监管高度的制约,对问责要求极高。由于高风险,AI辅助通常被限制在L1或L2-I级别,并需要强大的人类验证。
经济学与社会科学
经济学和社会科学面临独特的挑战,因为它们的证据通常是不确定的、异质的,并且难以通过传统实验验证。AI辅助目前的角色是增强现有研究,而不是替换关键方法。这些领域主要处于L1。
地球与环境科学
地球与环境科学利用自动化的数据分析、遥感和预测建模。这些领域的反馈延迟高,因为预测误差可能需要数年才能显现。目前的部署处于L1和L2-S。
6 Discussion / 讨论
本节将综合研究结果,识别关键差距,并提出关键的开放性问题。
重新思考自动研究的能力
AutoResearch当前的能力不应该被误解为已经实现的自主性。最先进的系统目前被正确归类为L2-P,而不是L3。这个区别很重要,因为它避免了将流程广度误认为科学自主性。
自动研究的评估
AutoResearch缺乏黄金标准基准。尽管新颖性、有效性、影响、可靠性和溯源等维度提供了一个结构化的框架,但可靠和自动化的评估仍然难以实现,特别是在科学新颖性和影响力方面。
泛化差距:超越计算与形式科学
AutoResearch的表现高度依赖于领域。在计算和形式科学中,由于快速的反馈、可执行性、低成本和高结构化,高度自动化是可行的。在物理科学、生物学和临床环境中,由于高延迟、高成本、异质证据和伦理约束,自动化仍然有限。
自动研究的可靠性、可信赖性与可审计性
AutoResearch面临着可靠性挑战。输出中仍然存在幻觉、错误和科学有效性未知的倾向。此外,可审计性至关重要,以确保结果能够被人类审查。
伦理与社会影响
AutoResearch的兴起引发了一些重要问题。这些包括:谁对AI生成的科学成果负责?AI研究如何影响科学过程的完整性?AI研究是否会导致误解?答案取决于AI如何被部署——是作为辅助、执行者还是主导协调者。
7 Conclusion / 结论
本综述提出了AutoResearch作为AI驱动科学工作流自动化的一个演化概念。我们提出了五级自主性谱系(L0-L4),涵盖了从人类中心到完全自主的科学工作。通过工作流条件(文献依据、假设形成、实验、验证和报告)对此进行了结构化,并且评估了科学质量维度(新颖性、有效性、影响、可靠性和溯源)。我们的分析表明AutoResearch的自主性有强烈的领域条件性。虽然系统正在LLM、编码和环境交互方面取得进展,但它们主要处于L2级别,而L3仍是一个已经界定的前沿。 这个领域将从对AI任务性能的关注转移到更严格的科学工作流质量和系统性的评估。信任、可审计性以及不同领域差异化的自主性天花板仍然是关键的研究方向。
原文信息
英文题目: AutoResearch AI: Towards AI-Powered Research Automation for Scientific Discovery 作者: Guiyao Tie, Jiawen Shi, Dingjie Song, Yixiao Huang, Ziji Sheng, Xueyang Zhou, Daizong Liu, Pan Zhou, Yongchao Chen, Ran Xu, Lifang He, Qingsong Wen, Manling Li, Cong Lu, Shuai Li, Pengtao Xie, Yixuan Yuan, Rui Meng, Lei Xing, Lichao Sun, Caiming Xiong, Philip S. Yu, Jianfeng Gao arXiv ID: 2605.23204 类别: cs.AI Comments/项目信息: 49 pages, 12 figures, 10 tables 原文链接: http://arxiv.org/abs/2605.23204v1

