
导读
AI 正在进入科研流程的各个环节,但“自动研究”并不是一个单点工具问题,而是一条从想法生成、文献综述、代码与实验、论文写作、同行评审到传播复用的完整生命周期问题。这篇综述将这一生命周期拆成创造、写作、验证和传播四个阶段,并系统梳理每个阶段中大模型、多智能体系统、检索、代码执行和人机协作的作用边界。 论文的核心价值在于,它没有简单宣称 AI 可以替代研究者,而是给出了一张更谨慎的路线图:AI 在结构化、可验证、工具化的任务中已经很强,例如文献检索、代码生成、实验编排、表格和图形生成;但在开放式科学判断、真正新颖性评估、跨阶段忠实性和责任归属上仍然脆弱。因此,可靠的自动研究更可能来自人类主导的协作系统,而不是完全无人闭环。 对于关注 AI4Research、科研智能体、论文写作自动化、自动评审和科研工作流基础设施的读者,这篇综述提供了一个很有用的总框架:哪些环节已经可用,哪些环节需要强验证,哪些环节必须保留人类判断,以及未来要如何构建可复现、可审计、可治理的 AI 辅助研究系统。
Abstract / 摘要
AI辅助研究正在跨越一个门槛:全自动系统如今能以低至15美元的价格生成研究论文,而长时程代理可以在极少人工输入的情况下执行实验、撰写手稿和模拟评审。然而,这一生产力前沿暴露了更深层次的诚信问题:在科学压力下,即使是前沿大语言模型仍然会伪造结果、遗漏隐藏错误,并且无法可靠地判断新颖性。本文对截至2026年4月的发展进行端到端分析,将AI辅助研究组织为四个认识论阶段:创造(想法生成、文献综述、编码与实验、表格与图表)、写作(论文撰写)、验证(同行评审、反驳与修订)和传播(海报、幻灯片、视频、社交媒体、项目页面和交互式代理)。我们识别出可靠辅助与不可靠自主之间尖锐的、阶段依赖的边界:AI擅长结构化、检索锚定和工具介导的任务,但在真正新颖的想法、研究级实验和科学判断方面仍然脆弱。生成的想法常常在实现后退化,研究代码远落后于模式匹配基准,端到端自主系统尚未一致达到主要会议接受标准。我们进一步表明,更大程度的自动化可能掩盖而非消除故障模式,使得人机协作成为最可信的部署范式。最后,我们提供了结构化分类、基准套件和工具清单、跨阶段设计原则以及面向实践者的操作手册。
1 Introduction / 引言
AI辅助研究正在跨越一个门槛。大语言模型及其代理扩展不再局限于局部的写作或编码支持,它们开始在整个研究生命周期中运作。最近的系统说明了这种转变的规模:AI科学家系统能以约15美元生成完整研究论文[122];FARS持续运行228小时,消耗114亿tokens,产生100篇论文,平均每2.3小时一篇[14];ARIS报告了一个隔夜工作流,运行了20多个GPU实验,修剪了无根据的声明,并通过迭代评审和修订将草稿评分从5.0提升至7.5[232]。这些系统暗示了一个新范式:AI正从辅助单个研究任务转向编排多阶段工作流,这些工作流生成想法、检索文献、执行实验、起草手稿、模拟评审并准备传播材料。 这一快速进展也暴露了该领域的核心张力。AI系统越来越能够产生类似研究的制品,但在验证这些制品是否新颖、忠实、可执行和具有科学意义方面却远不那么可靠。生成的想法看似有前景,但在实现后变弱[184];生成的代码可以运行,但实现的是错误的算法[71];流畅的手稿可能掩盖无根据的声明;自动评审可能连贯但宽松,或易受操纵[266];反驳可能承诺后续并未履行的修订[21];传播材料可能简化结果至超出证据支持的程度。因此,核心挑战不再是AI能否产生研究的形式,而是能否保持研究的实质:证据、判断、溯源和问责。 生命周期视角对于理解这一挑战至关重要。研究不是独立任务的集合:想法变成实验,实验变成声明,声明变成手稿,评审变成修订,论文变成面向公众的总结。早期引入的错误可能会在下游放大,尤其是当AI系统在未保留证据或溯源的情况下生成看似合理的输出时。尽管研究代理、写作助手、科学编码工具、自动评审员、反驳系统和 Paper2X 应用迅速涌现,该领域仍然缺乏对跨完整学术生命周期的 AI 自动研究的统一分析。没有这样的视角,就很难确定AI在哪里可靠地帮助,在哪里系统性地失败,以及哪些部署模式是科学可信的。 通过对截至2026年4月的发展进行调研,我们首次提供了跨完整学术研究生命周期的AI自动研究端到端分析。我们将该领域组织为四个认识论阶段和八个步骤:1创造阶段,涵盖想法生成、文献综述、编码与实验以及表格与图表;2写作阶段,涵盖论文撰写;3验证阶段,涵盖同行评审和反驳与修订;以及4传播阶段,涵盖海报、幻灯片、视频、社交媒体、项目页面和交互式论文代理。这一结构遵循研究的时间顺序,同时明确了每个阶段引入的不同AI能力、风险和验证要求。 我们的分析产生了五个核心发现。第一,当任务结构化、有根基且可外部检查时,AI能力最强,但对于需要新颖性、隐式领域知识、长时程推理或科学判断的开放式研究任务,能力急剧下降。第二,制品生成始终超越验证:跨阶段来看,AI通常能比它证明自身正确、忠实或有意义更快地生成看似合理的输出。第三,最可靠的部署模式是人机协作,而非完全自主:AI可以减少检索、起草、编码、可视化、评审支持和传播中的机械摩擦,但研究者必须保留判断、解释、实验设计、论证和问责的责任。第四,有效的系统日益依赖分层架构,该架构结合了探索、基于工具的执行和验证,这表明编排、溯源和反馈设计与模型规模同样重要。第五,AI在研究中的使用正成为一个治理问题而非检测问题:随着AI辅助变得常规,关键问题是披露、归属、责任以及科学诚信是否得到维护。 这项研究为AI自动研究这一新兴领域做出了三项贡献:
- 我们提供了跨四个阶段和八个步骤的AI自动研究统一分类,涵盖写作和编码等成熟领域,以及反驳、科学可视化和研究传播等尚未充分探索的领域。
- 我们综合了跨生命周期的工具、基准和方法家族,展示了系统如何从基于提示的辅助演变为检索增强、代理化、微调和混合工作流。
- 我们识别了跨领域的能力边界和开放挑战,包括阶段边界忠实性、科学判断、可复现性、引用溯源、治理、跨领域泛化和认知所有权。
本文其余部分组织如下。第2节介绍生命周期框架、方法家族、文献收集范围和发展时间线。第3节至第6节按时间顺序构建AI辅助研究四个阶段的路线图。第7节综合了端到端系统、评估范式、跨领域洞察和开放挑战。第8节总结全文。
2 Preliminaries / 预备知识
随着AI辅助研究工具从孤立的单阶段(如写作或编码辅助)扩展到多阶段助手,该领域变得日益难以用单一词汇进行比较。现有系统不仅在其技术设计上不同,还在它们所针对的研究阶段、假设的自主程度以及引入的科学风险形式上有所差异。 为了支持统一分析,我们首先建立四个基础要素:(i)组织本文调研的高层次学术研究生命周期框架(第2.1节),(ii)在每个阶段重复出现的方法家族(第2.2节),(iii)文献收集的范围和方法(第2.3节),以及(iv)主要发展的简要时间线(第2.4节)。
研究生命周期
我们将研究生命周期定义为八个相互关联的阶段,组织成四个阶段。每个阶段将服务于科学知识生产、验证和传播中共享功能的阶段分组。 阶段1:创造。 该阶段涵盖研究贡献被实质性地产生所经过的阶段,包括假设形成、证据收集、实验和科学可视化。
- S1 想法生成 生成、精炼和评估研究假设。技术包括直接LLM提示、检索增强生成、知识图谱推理和多代理协作。
- S2 文献综述 检索、综合和组织先前工作,形成连贯的研究背景。现代系统涵盖语义检索、引用图遍历、调研生成和迭代探索文献的深度研究代理。
- S3 编码与实验 将想法转化为可执行代码,运行实验,分析实证结果。这个阶段包括代码生成、论文到代码翻译、自主实验编排和结果解释。
- S4 表格与图表 构建方法图、结果图、比较表、数学公式和算法插图。这些制品将原始输出和概念设计转化为结构化的科学表示。
阶段2:写作。 该阶段将创造的输出组织成正式的学术手稿,以供交流和外部审查。
- S5 论文写作 起草、编辑、润色和构建学术手稿。AI辅助范围从语法校正和引用支持到章节级草稿和全篇论文生成。
阶段3:验证。 该阶段涵盖研究社区审查、批评和迭代精炼手稿的过程。
- S6 同行评审 生成结构化评审报告,将评审人匹配到手稿,评估评审质量,以及支持元评审决策。这些系统旨在协助而非取代社区的评估过程。
- S7 反驳与修订 分析评审人评论,识别所需证据,起草回复,以及支持手稿修订。这个阶段将外部批评与额外的分析、澄清和实验跟进联系起来。
阶段4:传播。 该阶段将手稿及其支持材料转化为广泛研究和公众可访问的形式。
- S8 Paper2X 将论文转化为海报、幻灯片、视频、项目页面、演示和社交媒体内容。每种输出格式针对不同的受众,需要独特的设计选择、保真度约束和沟通策略。
虽然按时间顺序呈现,但生命周期并非严格线性的。阶段3(验证)中的评审人批评可能需要返回到阶段1(创造)进行额外实验,而阶段4(传播)中的传播输出可能暴露出歧义或错误,触发阶段2(写作)中的修订。这些反馈循环是研究实践的核心,对于AI辅助工作流尤为重要,因为如果没有明确检查,错误可能会跨阶段传播。
方法家族
在整个研究生命周期中,AI辅助研究系统复用一小套方法论模式。我们将它们分为五个广泛家族:1提示工程、2检索增强生成(RAG)、3无训练代理方法、4基于训练的方法和5混合方法。这些家族并非互斥或严格按时间顺序排列;相反,它们描述了当前系统如何引出、锚定、专精和编排LLM行为。许多实用系统结合了其中几种,例如使用提示进行分解,使用RAG进行锚定,使用工具进行执行,以及使用训练模块进行评分或排序。 表1(原文表1)将这些方法论家族映射到八个生命周期阶段,使用主次标记来指示近期系统中的常见设计模式。
范围与文献收集
本调研聚焦于支持人类驱动的学术研究的AI工具、方法和基准,重点放在计算机科学和机器学习领域。我们涵盖2023年至2026年初期间发表或公开发布的工作,同时也引用早期的奠基性方法。当跨学科系统展示了与研究生命周期相关的能力时,也会被纳入,例如自主实验、文献综合、科学编码或基于证据的写作。我们排除了与研究工作流没有明确关联的通用LLM能力,以及缺乏足够技术或评估信息的封闭系统。 为了构建调研语料库,我们结合了三种互补的收集策略:
- 系统性关键词搜索 在Google Scholar、Semantic Scholar、arXiv和DBLP上,使用与AI辅助研究、自动研究代理、文献综述、科学编码、论文写作、同行评审、反驳生成和研究传播相关的查询。
- 雪球引用追踪 从每个生命周期阶段的代表性种子论文出发,包括向后追踪到奠基性工作,以及向前追踪到近期系统和基准。
- 社区和仓库监控 包括开源项目、策展阅读列表和基准排行榜,这些记录了尚未被正式出版物涵盖的新兴工具。
只有当一篇论文、系统或基准满足所有三个标准时才会被纳入:(i)它针对第2.1节定义的研究生命周期的至少一个阶段;(ii)它通过出版物、预印本、开源仓库、基准页面或技术报告公开可获取;以及(iii)它提供了足够的方法或评估细节以支持批判性分析。当同一系统存在多个版本时,我们优先选择最新或技术上最完整的版本,同时注意标志重要历史里程碑的早期版本。 由此产生的语料库涵盖了生命周期的所有四个阶段,但分布不均。大多数已记录的系统集中在阶段1(创造),尤其是文献综述、编码和实验自动化,其次是阶段2(写作)、阶段3(验证)和阶段4(传播)。这种不平衡既反映了研究成熟度也反映了出版可用性:创造阶段工具更常被基准测试和开源,而面向传播的工具通常是商业化的、工作流特定的,或通过不太标准化的标准进行评估。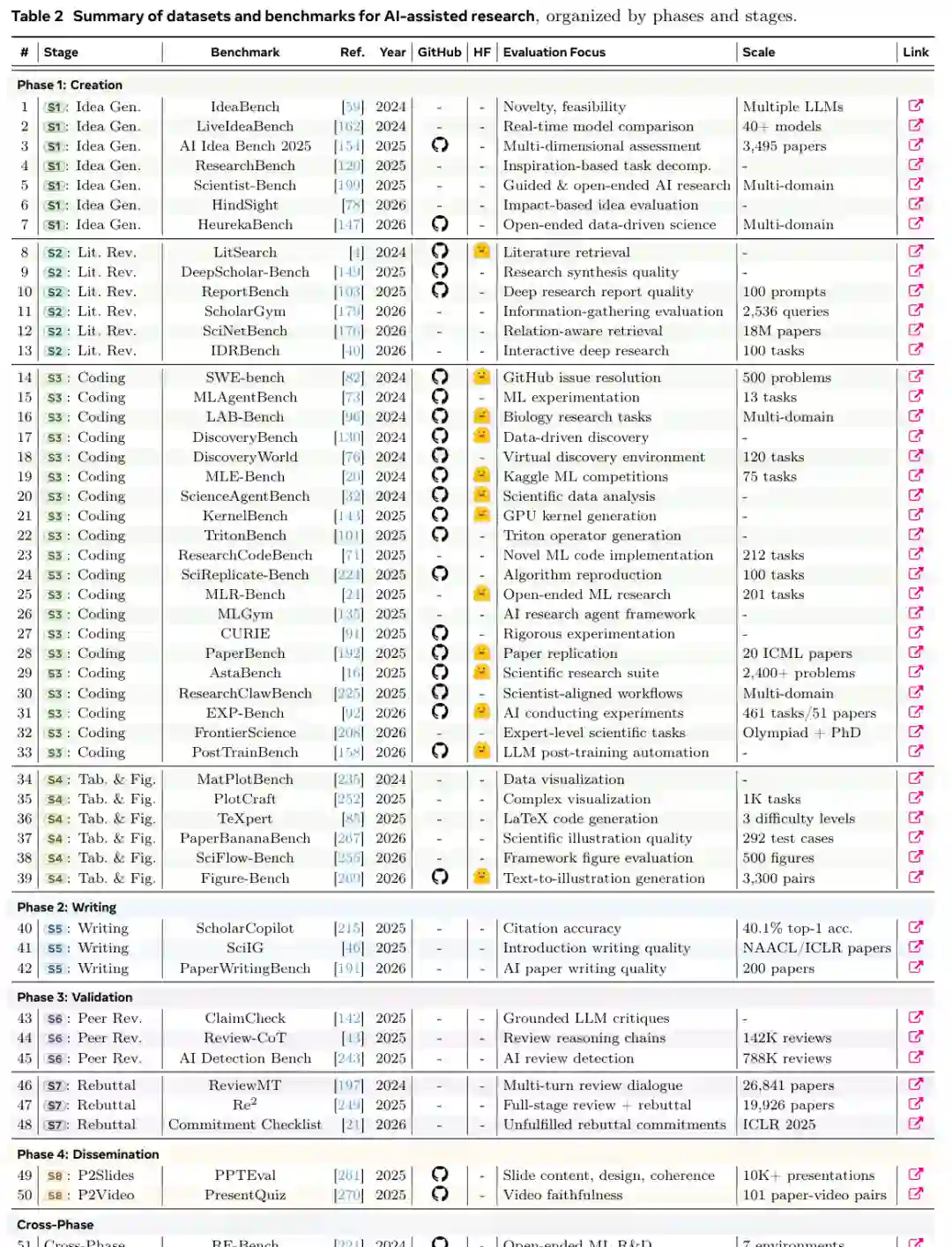
发展时间线
AI辅助研究的发展可以被理解为从阶段特定辅助向多阶段研究自动化的转变。在2024年之前,大多数系统针对孤立的单阶段研究任务,如文献搜索、科学问答、代码生成或领域特定的实验规划。早期的演示,包括Coscientist[15],展示了基于LLM的代理可以在受限的实验室环境中规划和执行科学工作流,而域基础模型如AlphaFold 3[1]说明了AI系统改变专业科学发现的更广泛潜力。 2024年,该领域开始从孤立的工具转向端到端的研究代理。AI科学家[122]提供了一个自动化管道的早期演示,涵盖想法生成、实验执行、论文写作和评审式评估。大约在同一时期,通用编码代理、检索增强文献系统和科学推理基准迅速成熟,使得更系统地评估研究生命周期的各个组件成为可能。这一转变标志着一个重要的重点变化:AI系统不再仅被视为局部任务的助手,而是越来越多地被视为多步骤研究工作流的编排者。 到2025年和2026年初,该领域进入了快速专业化和基准测试的阶段。几乎每个生命周期阶段都出现了专门的系统,包括文献综合、论文到代码翻译、自主实验编排、手稿写作、同行评审、反驳支持、图表生成和研究传播。例如,OpenScholar[9]推进了检索增强的科学综合,AI Scientist v2[228]探索了更强的端到端自动研究形式,FARS[14]展示了大规模自主论文生成。同时,以前未充分探索的阶段开始获得专门关注,包括反驳写作(例如RebuttalAgent[63])和科学可视化(例如AutoFigure-Edit[114])。 这些发展表明,该领域不再仅受限于模型能力,还受限于跨完整研究生命周期的编排、评估、可靠性和治理。
3 Phase 1: Creation / 阶段1:创造
该阶段涵盖了研究贡献被实质性产生所经过的阶段:生成想法(S1),将其置于先前工作背景中(S2),产生实证或分析证据(S3),以及构建方法和结果的视觉表示(S4)。这些阶段共同解决了两个基本问题:贡献是什么,以及什么证据支持它? 在四个阶段中,创造目前拥有最丰富的工具生态系统和最广泛的基准覆盖,但其成熟度仍然不均衡。S1(想法生成)吸引了大量工具,但遭受着构思-执行差距,即看似新颖的想法在实现后往往会变弱。S2(文献综述)通过检索增强和代理化综合迅速改进,但引用忠实性、覆盖完整性和多论文关系推理仍然困难。S3(编码与实验)通过代码生成、论文到代码翻译和自主实验编排取得了进展,但在真正新颖的研究代码上性能仍然急剧下降。S4(表格与图表)尽管在日常研究实践中很重要,但仍然相对欠发达。
想法生成
想法生成是研究生命周期的入口点,在这里提出并精炼候选假设、研究问题和实验方向。现有方法从直接LLM提示到外部锚定生成、多代理协作以及专门的新颖性、可行性、多样性和下游影响评估。在这些方向上,核心挑战是LLM可以产生看似新颖且动机良好的想法,但常常难以生成在执行后仍然可行、独特和有影响力的想法。
# 基于LLM内部知识的生成
AI辅助构思的最简单形式是直接以研究领域、问题描述或文献背景提示LLM。Si等人[183]通过一项涉及100多名NLP研究者的大规模人类研究建立了一个有影响力的基线,发现LLM生成的想法在新颖性方面被显著评为高于人类想法(p < 0.05)。这一结果证明了LLM的表面生成能力,但也引发了该阶段的核心问题:表面上的新颖性是否对应于可执行和有影响力的研究。 后续工作探索了三种加强直接生成的方法。首先,迭代精炼使用反馈循环来提高想法特异性并减少浅层新颖性。ResearchAgent[10]结合学术图谱反馈来精炼生成的想法,SciMON[209]迭代地将候选想法与先前工作进行比较以减轻直接LLM提示趋向浅层贡献的倾向,Chain of Ideas[102]将文献组织成渐进推理链,其表现优于简单提示基线。其次,学习质量信号引入显式评分或优化目标。Spark[168]将检索增强生成与在60万条OpenReview评论上训练的评判模型相结合以估计创造力,DeepInnovator[39]在“下一个想法预测”范式下训练了一个140亿参数模型,并在构思任务中报告了对前沿模型80-94%的胜率,Goel等人[52]使用从现有论文中提取的rubric奖励来优化AI联合科学家计划,强化学习优化的计划被人类专家偏好的比例为70%。第三,自适应测试时计算将推理努力视为可控资源。IRIS[47]在人机循环构思平台中使用蒙特卡洛树搜索,随着想法收敛而分配搜索资源,而FlowPIE[210]通过流引导的文献探索在测试时演化科学想法。
# 外部信号驱动生成
直接LLM生成受限于模型的参数知识及其产生看似合理但锚定薄弱的想法的倾向。外部信号驱动方法通过将构思锚定在结构化知识、检索到的文献或时间研究趋势中来解决这一限制。三种信号来源尤为常见,每种都从不同角度锚定想法:关系结构、文本证据和时间机会。
- 知识图谱提供假设形成的关系结构。SciAgents[49]在科学知识图谱上进行多代理推理,而MOOSE-Chem[237]将化学假设分解为灵感检索、假设组合和排序,重新发现了来自51篇高影响力论文的假设。MOOSE-Chem2[236]将这一方向扩展到细粒度、实验上可操作的假设。
- 论文检索将想法锚定在非结构化文献中。SciPIP[211]提出锚定于检索论文的想法,IdeaSynth[152]在交互式画布上将想法方面表示为节点,用于文献锚定的精炼;在一项有20名参与者的用户研究中,IdeaSynth鼓励用户探索比仅使用LLM的基线更多的替代方案。
- 趋势分析针对研究机会的时间维度。Nova[69]使用迭代规划和搜索来识别具有改进多样性的新兴研究方向。这些方法表明,外部锚定不仅仅是辅助特征,而是将生成的想法与研究前沿连接起来的关键机制。
# 多代理协作生成
多代理构思系统试图通过模拟研究社区互动的各个方面,如角色专业化、批评、修订和辩论,来提高想法质量。VirSci[193]构建了一个虚拟科学社区,其中多个LLM代理参与结构化讨论,报告了比单代理AI科学家基线更高的新颖性得分(5.24对4.94)。其分析表明,代理多样性和讨论结构很重要,最佳配置使用8个成员、5轮和50%的多样性。然而,多代理扩展并非均匀有益的。一项SIGDIAL 2025研究[206]发现,三轮批评-修订通常足够,而额外轮次产生递减的回报。其他系统探索了超越单纯讨论的更丰富的协作机制:Gu等人[57]研究了通过跨领域组合思想的组合创造力,Deep Ideation[258]设计了通过结构化图谱探索导航科学概念网络的代理。然而,最近的证据也指向一个更深的局限性:“人工蜂群思维”研究[79]报告称,LLM生成的想法倾向于聚集在想法空间的狭窄区域,表明多样性崩溃可能是当前模型的结构性属性,而不是简单地通过增加更多代理就能解决的问题。
# 评估:新颖性与可行性
评估生成的想法是困难的,因为强研究想法必须同时满足多个标准:新颖性、可行性、清晰度、重要性和最终影响力。早期基准量化了这个领域的部分内容,但核心问题是想法在实施、测试和与先前工作对比后是否仍然有价值。 IdeaBench[59]基于八个研究领域的2374篇有影响力的论文评估想法生成,而LiveIdeaBench[162]使用跨22个领域的1180个关键词提示探索科学创造力。两者都表明,科学创造力并不能很好地被通用基准预测,通常以推理为重点的模型表现更好。ResearchBench[120]通过基于灵感的任务分解扩展了评估,AI Idea Bench 2025[154]将评估扩展到两个评估轴上的3495篇论文。 这些基准中的一个重复模式是表面新颖性与实际可行性之间的差距。IdeaBench报告,许多LLM在新颖性上得分高于0.6,但在可行性上低于0.5[59],这表明生成看似合理的想法仍然比生成可以执行和验证的想法更容易。HindSight[78]引入了一个基于时间分割、基于影响力的评估来强化这一担忧,表明LLM作为评判者可能会高估那些后来未能转化为有影响力工作的新颖想法。这一发现表明,当前的评估协议可能奖励表面上的新颖性而非真正的研究潜力,强化了对执行锚定的和时间鲁棒评估的需求。
# 发现与观察
状态与进展: 想法生成是阶段1中工具最丰富的阶段之一,系统涵盖提示、检索、多代理协作、学习评分和测试时搜索。能力有明显的进展:提示→RAG→多代理→强化学习训练,每一代都解决了其前身的问题。外部锚定日益核心:基于检索和知识图谱的方法比仅使用LLM的提示更好地将生成的想法连接到研究前沿[211, 237]。 差距与局限: 实施前评分良好的想法在执行后可能显著退化(Δ=−1.98,而人类想法为Δ=−0.63[184]),暴露了表面新颖性与可执行实质之间的差距。新颖性-可行性权衡持续存在(>0.6对<0.5[59]),多样性崩溃是结构性的,无法通过扩展解决[79]。LLM作为评判者的评估可能奖励表面而非真正的创新,报告的新颖性判断与后来的实际影响力负相关(ρ=−0.29[78])。
文献综述
文献综述通过检索相关工作、综合证据并将现有发现组织成连贯的知识背景,将研究锚定在先前知识中。与想法生成相比,这个阶段更锚定且外部可验证,使其成为AI辅助研究中成熟最快的领域之一。现有系统已从语义论文检索发展到引用感知综合和长时程深度研究代理。然而,两个局限性仍然核心:系统可以越来越好地检索和总结单篇论文,但在忠实引用、覆盖完整性和多论文关系推理方面仍然困难。
# 文献检索
检索是AI辅助文献综述的基础:每个下游综合都取决于系统是否能从现在包含数千万条目的科学语料库中找出正确的论文。现有方法可以分为三种模式。语义检索形成了基线,使用密集表示和基于LLM的查询理解,超越了关键词匹配。LitLLM[2]将LLM与学术数据库集成用于密集检索,而PaperQA2[189]通过引用验证扩展了这一方向,并在科学文献搜索上报告了强性能。引用图增强检索在嵌入之外添加了结构信号。这些方法不将论文视为孤立文档,而是使用引用链接、论文关系和图遍历来改善上下文覆盖。OpenResearcher[264]将RAG与图遍历相结合用于加速文献探索。代理化多步检索进一步将检索从一次性排序问题转变为迭代搜索过程。PaSa[62]部署了一个发出后续查询并精炼候选集的LLM代理,近似人类研究者探索不熟悉主题的方式。伴随这些方法,出现了专门的基准来审计检索质量:LitSearch[4]针对检索精度,而CiteME[151]侧重于引用忠实性。
# 调研与相关工作生成
综合将检索到的论文转化为结构化叙述。这标志着从检索导向系统向生成导向系统的转变。该子领域通过几种日益结构化的设计得到了发展。单次通过系统建立了自动调研起草的可行性。AutoSurvey[214]证明了LLM可以端到端生成质量合理的调研,而SurveyX[110]改善了内容质量,并在选定维度上接近人类专家性能。结构感知系统随后将大纲规划从格式化步骤提升为核心综合制品。STORM[178]引入了多视角提问来构建全面的主题大纲,SurveyForge[229]从人类撰写的调研中学习大纲启发式,结合记忆驱动的内容生成,在大纲质量上优于AutoSurvey。多代理分解将检索、验证、组织和叙述写作分离为专门的子任务。LiRA[51]和Agentic AutoSurvey[119]为不同角色使用专用代理,而IterSurvey[250]将大纲生成视为带有稳定性检查的迭代规划问题。InteractiveSurvey[219]进一步引入了用户定制。引用和编辑器感知系统闭合了综合与写作环境之间的循环。SurveyG[137]构建了三层引用图,Citegeist[11]在arXiv语料库上构建了动态RAG管道,CiteLLM[65]在LaTeX编辑器内嵌入了无幻觉的参考发现。然而,引用忠实性仍然是一个瓶颈:ScholarCopilot[215]报告仅有40.1%的top-1引用准确率,表明生成看似合理的相关工作文本比将每个声明锚定在正确来源中仍然容易。
编码与实验
这个阶段将研究想法转化为可执行实现,运行实验,并分析由此产生的证据。与文献综述相比,编码和实验需要AI系统与外部环境交互:仓库、依赖、数据集、计算资源、测试套件和评估脚本。现有工作涵盖通用代码生成、论文到代码翻译、实验编排和结果分析。在这些方向上,核心挑战不是LLM是否能写出合理的代码,而是它们是否能生成语义正确的、可执行且可靠的科学实现。
# 代码生成
通用代码生成已成为当前LLM最成熟的能力之一。在SWE-bench Verified[195]上,前沿系统现在超过76%。代理框架在这一进展中扮演了核心角色。SWE-agent[230]建立了代理-计算机接口范式,赋予LLM结构化访问文件、测试和工具调用的能力。OpenHands[212]将这一方向扩展为软件工程代理的通用开放平台。然而,在标准软件基准上的高性能并不直接意味着研究代码生成的准备就绪。更困难的变体暴露了更尖锐的局限性:性能在SWE-bench Pro[37]上降至23%,在SWE-EVO[201]上降至25%。这些结果表明,标准基准可能会高估当任务熟悉、有良好支架或可模式匹配时的鲁棒性。这种区别在研究环境中变得更加明显,因为目标不仅仅是修复现有软件,而是实现未完全指定的算法、再现隐含的设计选择并验证科学声明。
# 论文到代码
论文到代码翻译是研究特定的代码生成形式。它比传统软件工程更难,因为研究论文通常混合了自然语言描述、方程、伪代码、消融细节和领域约定,同时将关键的实现选择留给隐含。PaperCoder[174]通过一个用于规划、分析和代码生成的三阶段多代理框架来解决这一设置,将ML论文转化为可执行仓库。专门的基准量化了这一设置有多难。ResearchCodeBench[71]在212个新颖的ML实现任务上评估LLM,最佳报告模型仅达到37.3%的准确率;值得注意的是,58.6%的错误是语义错误,意味着生成的代码能运行但实现了错误的算法或行为。SciReplicate-Bench[224]报告了类似的天花板为39%。SciCode[203]将研究级编码评估扩展到数学、物理和化学,而PaperBench[192]将20篇ICML 2024论文分解为可单独评分的子任务。这些基准共同揭示了通用软件问题解决与忠实研究代码实现之间的巨大差距。
# 实验执行与编排
超越代码生成,一些系统现在编排完整的实验工作流。MLAgentBench[73]评估LLM代理的机器学习实验自动化,发现即使是强模型也需要多次尝试才能成功。MLGym[135]将AI研究框架化为一个通用强化学习环境。ARIS[232]通过迭代评审和修订运行实验、修剪声明并改进手稿,将草稿评分从5.0提升至7.5。R&D-Agent[233]引入了执行失败时的自动诊断和回滚机制。
# 发现与观察
状态与进展: 编码和实验取得了显著进展,在SWE-bench等标准软件基准上性能稳健,工具生态系统迅速成熟。出现了专门的论文到代码系统和实验编排框架。 差距与局限: 研究代码性能远落后于通用代码基准(约37%对76%),大约60%的错误是语义错误。实验编排仍然脆弱,真实世界研究环境的工具集成具有挑战性。
表格与图表
S4涵盖将原始结果和概念设计转化为结构化科学表示的过程:方法图、结果图、比较表、数学公式和算法插图。该阶段对阅读和交流都很重要,但在AI辅助研究中仍然是欠发展阶段之一。
# 科学图表生成
科学图表包括几种不同类型:方法图(架构图、框架图)、结果图(性能曲线、比较条形图)和概念图。MatPlotAgent[235]引入了一个编码代理框架,使用迭代执行和反馈循环通过Matplotlib生成图表。DeTikZify[13]将数学和科学图转换为TikZ代码,实现了LaTeX原生集成。AutoFigure[114]和AutoFigure-Edit[114]为科学图表提供双向论文到图表操作。
# 表格理解与生成
表格从聚合实验数据或结构化的方法比较中提取。大多数现有方法依赖于通用LLM能力进行表格创建或格式化。在科学背景下,表格生成提出了保真度挑战:生成的表格必须保留精确的数字、显著性值和引用标签,并提供清晰的科学比较。
# 数学公式与算法伪代码
数学公式和伪代码是研究论文中高度专业化的组件。TeXpert[85]针对科学排版任务中的LaTeX代码生成,提供了三种难度级别的测试。PaperBananaBench[267]在292个测试用例上评估科学插图质量。
# 发现与观察
状态与进展: 表格和图表研究正在增长,出现了专门用于科学可视化的基准和系统。 差距与局限: 标准化评估有限,视觉保真度检查很少用于验证。复杂图表和公式的忠实生成仍然困难。
总结与过渡:创造
阶段1建立了AI自动研究在制品生成和验证之间的核心张力。AI擅长产生想法、检索文献、编写代码和创建可视化,但始终难以保证其输出的科学性。想法在实现后退化,研究代码落后于通用基准,生成的图形缺乏系统验证。这一思维差距定义了整个生命周期的一个反复出现的问题。
4 Phase 2: Writing / 阶段2:写作
阶段2将从阶段1产生的论点和证据组织成一个正式的、可审查的手稿。
论文写作
论文写作将来自阶段的输出组织成连贯的学术手稿,包括引言、背景、方法、结果、讨论和结论等元素。AI辅助写作通常分为两类。
# 半自动写作辅助
最常见的形式包括LLM辅助的编辑、语法校正、句子重写和段落构建。Overleaf的LaTeX感知工具和GPT Researcher等工具提供主题级建议。CiteLLM[65]嵌入了LaTeX编辑器中的引用发现。
# 全自动论文生成
全自动论文生成系统从阶段1的输出中生成完整手稿。AI Scientist[122]生成了完整论文,AI Scientist v2[228]增强了多阶段方法。CycleResearcher[220]引入了自杀式攻击和对抗性检测。FARS[14]是最大规模的系统,生成100篇论文。
# 评估:写作质量与AI检测
评估包括表面指标(语法、流利度)和科学维度(论据、结构、对支持的忠实性)。PaperWritingBench[191]提供了200篇评估AI论文写作质量的论文。
# 发现与观察
状态与进展: 文本流畅度迅速改善,全自动论文生成成为可能,AI检测接受度增长,但不同阶段之间出现提交差异。 差距与局限: 引用忠实性仍然是问题。检测难以与训练数据泄露分离。下游科学验证稀缺。
总结与过渡:写作
阶段2表明,可读手稿可以快速产生,但可验证产品仍然难以实现。没有结构化验证,生成的论文可能看起来很完美但包含未发现的错误。
5 Phase 3: Validation / 阶段3:验证
阶段3引入外部审查和修订,以评估手稿的质量和科学完整性。
同行评审
同行评审是研究验证的关键步骤,AI系统被用于生成评审、为手稿匹配评审人或撰写元评审。
# 自动评审生成
DeepReviewer[268]和MARG[35]使用上下文挖掘、多代理辩论和多阶段模板生成结构化评审。ReviewAgents[43]将评审分解为关键方面。
# 元评审生成
元评审综合多个评审人的反馈,以提供编辑决策建议。
# 评审人匹配
AI系统用于基于主题建模或引用网络将手稿与合适的评审人进行匹配。
# 发现与观察
状态与进展: 自动评审可以在规模上生成结构化反馈。元评审综合表现合理。出现训练数据集。 差距与局限: 评审噪声和偏见仍然存在。自动评审比人类更宽容,更容易受到对抗性攻击。评审深度和实质性不足。
反驳与修订
# 评审人评论分析
分析评审人反馈以提取关键问题、识别需要额外证据的领域。
# 自动反驳生成
RebuttalAgent[63]和Paper2Rebuttal[129]自动起草反驳。
# 发现与观察
状态与进展: 反驳起草成为新的研究阶段。系统从单轮回复发展到全自动反驳。 差距与局限: 生成的反驳可能做出空洞的承诺。反驳质量评估仍然不充分。
总结与过渡:验证
阶段3表明,自动验证可以快速扩大审查规模,但不够深入,容易出错,并且缺乏科学专业知识的深度。
6 Phase 4: Dissemination / 阶段4:传播
阶段4将手稿转化为更广泛受众的可访问格式。
研究传播 (Paper2X)
# 论文到海报
自动海报生成通过提取摘要、数值结果和可视化创建结构化的海报布局。系统通常使用基于LLM的摘要和模板布局。
# 论文到幻灯片
PPTAgent[261]和SlideGen[111]将论文分解为幻灯片,提取关键点并创建带注释的幻灯片组。
# 论文到视频与演讲
PresentQuiz[270]评估基于论文的视频生成。
# 论文到社交媒体
简单的提示链用于创建社交媒体帖子摘要。
# 论文到代理与工具
交互式论文代理允许用户与论文进行问答。
总结与过渡:传播
传播仍然是生命周期中评估最少的阶段。关于保真度、受众适配和采用的开放问题。
7 Cross-Cutting Analysis / 跨领域分析
端到端研究系统
# 顺序与管道系统
AI Scientist[122]提出了一个顺序管道:想法、实验、写作、评审。FARS[14]以更大规模实现了类似管道。
# 基于搜索与自我改进系统
这些系统通过搜索和迭代精炼进行优化。
# 基于技能与工具集成系统
这些系统将技能库、工具和验证器集成到统一架构中。
# 多代理与社区规模系统
多代理系统协调专门代理进行想法、实验、写作和评审。
# 发现与观察
状态与进展: 端到端管道已被证明是可行的,覆盖了生命周期的多个阶段。 差距与局限: 跨阶段推理有限,阶段边界检查不足。
跨研究生命周期的评估
# 阶段特定基准
跨生命周期出现了基准(表2)。
# 评估方法论
常见的评估方法包括人类评估、LLM-as-Judge、基准指标和用户研究。
# 新兴评估范式
新兴范式包括基于过程的评估、基于影响力的评估和交互评估。
# 评估差距
关键差距包括科学判断的评估、对科学意义的评估、跨阶段评估。
跨领域洞察
# 制品生成超越科学验证
在所有阶段,AI生成制品的速度超过了验证其正确性的能力。
# 人机协作仍然是最可靠的部署模式
最可靠的模式是研究人员保留判断、解释和问责权。
# 开放式研究任务中出现能力边界
AI在局限性任务中表现出色,在需要真正新颖性、隐含领域知识或科学判断的任务中失败。
# 有效系统收敛于分层架构
最成功的系统结合了探索、基于工具的执行和验证层。
# AI使用已成为治理问题,而非检测问题
关键挑战转向了披露、归属和责任。
开放挑战与未来方向
# 跨阶段边界忠实性
错误在阶段之间传播。
# 科学判断与新颖性评估
评估科学意义仍然困难。
# 验证、可复现性与问责
端到端自主系统尚未稳定达到主要会议接受标准。
# 引用、版本与来源溯源
引用忠实性有限,ScholarCopilot仅40.1% top-1准确率[215]。
# 治理、披露与研究诚信
AI使用成为治理问题。
# 跨领域泛化与基础设施访问
几乎所有基准和系统都针对ML/NLP文献。
# 人类专业知识与认知所有权
自动化可能削弱研究者对工作的认知所有权。
# 迈向可靠的AI辅助研究
需要以诚信为中心的设计、健壮的验证和治理框架。
8 Conclusion / 结论
本文对AI自动研究进行了第一次端到端分析。我们通过四个认识论阶段:创造、写作、验证和传播,组织了该领域。我们的分析揭示了在结构化、检索锚定任务中能力最强、在开放式研究任务中能力脆弱的阶段依赖边界。始终存在的差距是制品生成超越科学验证:AI可以速度更快地输出,但无法证明其科学有效性。更大的自动化可能掩盖故障模式,使人机协作成为最可信的模式。该领域正从检测问题转向治理问题,人工智能使用的关键挑战是披露、归属和科学诚信。我们提供了分类、基准、工具清单、设计原则和操作手册,以支持向更可靠的AI辅助研究发展。
原文信息
英文题目: AI for Auto-Research: Roadmap & User Guide 作者: Lingdong Kong, Xian Sun, Wei Chow, Linfeng Li, Kevin Qinghong Lin, Xuan Billy Zhang, Song Wang, Rong Li, Qing Wu, Wei Gao, Yingshuo Wang, Shaoyuan Xie, Jiachen Liu, Leigang Qu, Shijie Li, Lai Xing Ng, Benoit R. Cottereau, Ziwei Liu, Tat-Seng Chua, Wei Tsang Ooi arXiv ID: 2605.18661 类别: cs.AI Comments/项目信息: Project Page at https://worldbench.github.io/awesome-ai-auto-research GitHub Repo at https://github.com/worldbench/awesome-ai-auto-research 原文链接: https://arxiv.org/abs/2605.18661
