

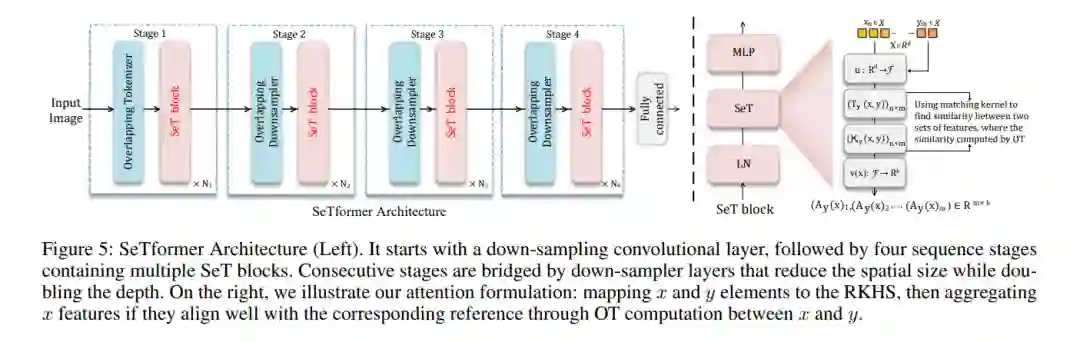
点积自注意力(DPSA)是变换器的一个基本组成部分。然而,将其扩展到长序列,如文档或高分辨率图像,由于softmax操作导致的二次时间和内存复杂度,变得代价昂贵。核方法被用来简化计算,通过近似softmax,但通常与softmax注意力相比会导致性能下降。我们提出SeTformer,一种新颖的变换器,其中DPSA完全被自优化传输(SeT)所取代,以实现更好的性能和计算效率。SeT基于两个基本的softmax属性:维持非负注意力矩阵和使用非线性加权机制来强调输入序列中重要的标记。通过引入用于最优传输的核成本函数,SeTformer有效地满足了这些属性。特别是,SeTformer在小型和基础型模型中在ImageNet-1K上实现了令人印象深刻的top-1准确率,分别为84.7%和86.2%。在对象检测中,SeTformer-base的性能超过了FocalNet对应模型+2.2 mAP,使用了38%更少的参数和29%更少的FLOPs。在语义分割中,我们的基础型模型超过了NAT +3.5 mIoU,参数减少了33%。SeTformer还在GLUE基准的语言建模中实现了最先进的结果。这些发现凸显了SeTformer在视觉和语言任务中的适用性。
成为VIP会员查看完整内容
相关内容
专知会员服务
15+阅读 · 2022年3月19日
Arxiv
0+阅读 · 2024年2月25日
Arxiv
232+阅读 · 2023年4月7日
最新内容
相关VIP内容
专知会员服务
15+阅读 · 2022年3月19日
相关资讯
相关论文
Arxiv
0+阅读 · 2024年2月25日
Arxiv
232+阅读 · 2023年4月7日