
基于强化学习的知识智能体
我们提出了一套通过强化学习训练企业搜索智能体的系统,该系统在多种“难以验证”的代理式搜索任务中达到了最先进(SOTA)的性能。本研究包含四个核心贡献: 1. 引入 KARLBench:一个涵盖六种不同搜索模式的多能力评估套件,包括:约束驱动的实体搜索、跨文档报告综合、表格数值推理、详尽实体检索、技术文档程序化推理,以及内部企业笔记的事实聚合。 1. 异质行为泛化性:我们证明,在多种异质搜索行为上训练的模型,其泛化能力显著优于仅针对单一基准测试优化的模型。 1. 代理式合成流水线:开发了一种利用长程推理(Long-horizon reasoning)和工具调用来生成多样化、有依据(Grounded)且高质量训练数据的流水线,并结合了能力递增模型的迭代引导(Iterative bootstrapping)。 1. 新型后训练范式:提出了一种基于迭代式大批量离策(Off-policy)强化学习的新范式。该方法具备高样本效率,对训练器与推理引擎之间的差异具有鲁棒性,并能自然扩展至具有分布外(OOD)泛化能力的多任务训练。
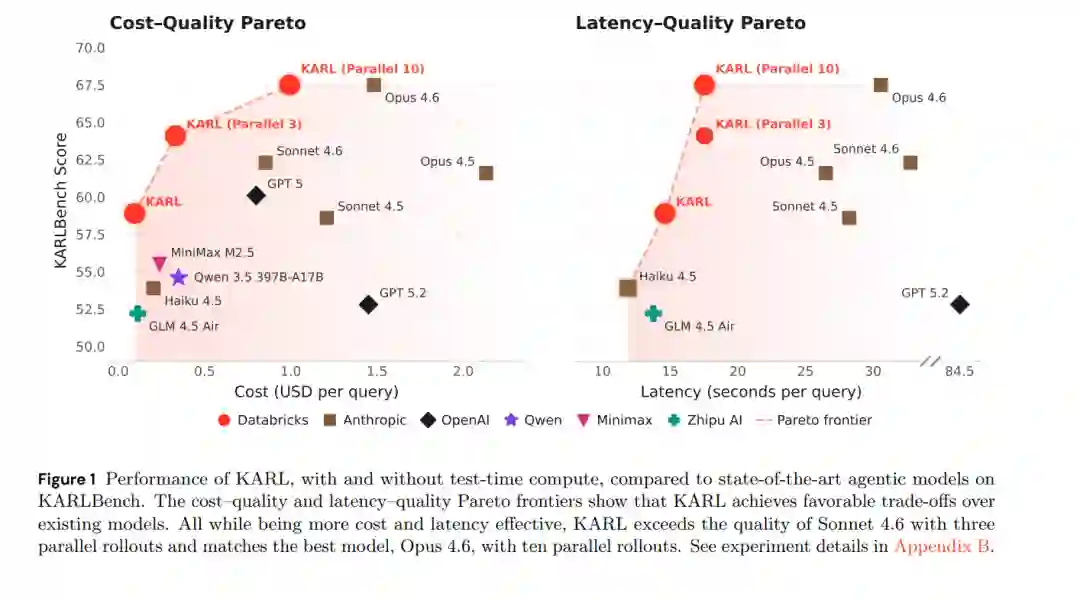
与 Claude 4.6 和 GPT 5.2 相比,KARL 在 KARLBench 的“成本-质量”和“延迟-质量”权衡中均达到了帕累托最优,即便是在训练期间处于分布外(OOD)的任务中亦是如此。在提供充足测试时计算资源的情况下,其表现超越了最强的闭源模型。这些结果表明,定制化合成数据结合多任务强化学习,能够为对齐推理(Grounded reasoning)构建高性价比且高性能的知识智能体。

1 引言(Introduction)
现代知识智能体(Knowledge Agents)的兴起——即能够对大规模数据集进行迭代查询、检索和推理的系统——推动了多类任务的快速进展。这些任务共同具备两种核心能力:(a) 多步信息采集,以及 (b) 基于采集证据的复杂推理。我们将此类任务称为“对齐推理”(Grounded Reasoning),即推理过程需要访问模型参数以外的外部知识。对齐推理任务不仅处于当前模型智能体能力的前沿,还具有极高的经济价值。在金融、法律、医学、制造业等领域,企业依赖于海量的私有数据,而模型在训练阶段并未接触过这些数据。 然而,相对于其他类型的推理任务(如常识推理、数学或编程),研究对齐推理前沿模型能力的工作相对匮乏。例如,虽然目前已提出多个“深度搜索”(Deep Research, OpenAI, 2025a)模型——即能够通过互联网进行多步调研并生成全面报告的智能体(Zheng et al., 2025; Li et al., 2025)。但深度搜索依赖的是公开、非私有的知识以及黑盒网络搜索工具。因此,目前尚不清楚报道中处于 SOTA(最先进)水平的深度搜索结果是否能真正泛化到其他对齐推理任务中。 对齐推理的实际应用要求模型掌握一系列技能和知识领域:将庞大的候选集缩小为满足多个约束条件的单一实体、将分散的医学发现综合为连贯报告、对金融表格数据进行数值推理、对技术文档进行程序化推理等。针对某一领域优化的系统并不能保证在其他领域同样胜任。现有的基准测试,如 HotpotQA (Yang et al., 2018)、BrowseComp-Plus (Chen et al., 2025) 或 FinanceBench (Islam et al., 2023),仅捕捉了知识智能体行为的有限片段。在本文中,我们研究如何构建并评估面向任意领域的对齐推理知识智能体。
KARLBench:多能力评估套件。为了评估对齐推理能力,我们将现有的和新增的搜索基准测试整合为名为 KARLBench 的套件,涵盖六种不同的搜索模式:约束驱动的实体搜索、跨文档报告综合、表格数值推理、详尽实体检索、程序化技术推理,以及内部企业笔记的事实聚合。值得注意的是,该套件还包括一个新的私有基准测试 PMBench,用于评估我们的生产级智能体。我们证明,在异质搜索行为上训练的模型比针对单一基准测试优化的模型具有更好的泛化性。
代理式合成(Agentic Synthesis)。训练数据必须具备多样性、对齐性和挑战性,而这些特质仅靠提示词(Prompting)或静态合成智能体难以实现。我们开发了一种代理式流水线,智能体通过向量搜索动态探索语料库以创建训练数据,生成锚定于检索证据的问答对。我们展示了该方案在两种需要不同搜索行为的基准测试(即 TREC-Biogen 和 BrowseComp-Plus)上均具有泛化性。随着我们训练出更强大的搜索智能体,我们利用改进后的智能体迭代引导(Bootstrap)合成数据用于后续训练,实现了迭代式的自我提升。
迭代式大批量离策强化学习(Iterative Large-batch Off-policy RL)。我们同步开发了 OAPL (Ritter et al. 2026),这是一种基于迭代式大批量离策 RL 的新型后训练范式。通过在目标函数设计中接纳“离策性”(Off-policyness),我们的方法对训练器与推理引擎(如 vLLM)之间的差异具有鲁棒性,无需使用截断重要性采样(Clipped importance weighting)、数据删除或路由回放(Router replay)等启发式策略——而这些策略此前被认为是稳定大规模混合专家模型(MoE, Dai et al., 2024)在线 GRPO (Shao et al., 2024) 训练所必需的。这降低了基础设施的设计复杂性,并能通过简单合并 BrowseComp-Plus 和 TREC-Biogen 的损失函数扩展至多任务训练,在两个任务上同时获得持续提升,并在 KARLBench 的四个保留(Held-out)任务上展现出分布外(OOD)泛化能力。 * 总体结果。以 GLM 4.5 Air (Zeng et al., 2025) 为起点,通过不同程度的测试时缩放(Test-time scaling),KARL 在与 Claude 4.6 和 GPT 5.2 的对比中,在 KARLBench 上达到了帕累托最优,展现了跨对齐推理任务的泛化能力。在各种预算下,它始终能以更低的成本和延迟实现同等质量;在充足的测试时计算资源下,其质量甚至超过了最强的闭源模型(见 Figure 1, Table 4)。这些结果表明,通过专门的合成数据创建、针对难以验证任务的多任务强化学习以及测试时计算缩放,可以催生出能够胜任多样化任务的高性价比对齐推理知识智能体。
