机器学习算法广泛应用于刑事司法、医疗、信贷和就业等高风险决策。研究界因此催生了两个主要但相互独立的研究领域:算法公平性(关注结果公平)和可解释人工智能(关注可解释推理)。本文指出并系统梳理了这两个领域交叉处的一个盲点:一个模型可能在其输出中满足所有标准公平性标准,但其推理过程却可能严重不公平。我们称此为程序性偏见,缓解它要求将解释公平性作为一个独立的研究对象。
本文首次为这一新兴领域提供了统一的理论和文献综述。核心贡献是条件不变性框架:将解释公平性形式化为解释分布不依赖于保护属性(给定所有任务相关特征)的要求。所有现有的解释公平性指标都可以被视为这一条件的部分操作化。我们提出了一个七维分类法,识别了三种解释不公平的生成机制(表征驱动、解释模型失配、可行动性驱动),并提出了一个规范的六步评估工作流,以在实际中操作化解释公平性审计。本文调查了2016-2025年间超过300篇出版物,并提供了一个关于这一新兴领域的结构化理论基础。
1 Introduction / 绪论
机器学习算法已深度融入日常决策,尤其是在影响个人生活的社会敏感领域:决定谁可以获得保释、哪些患者获得额外医疗干预、贷款申请是否获批、谁被列入应聘短名单,以及个人接触到哪些社交媒体内容。模型在展现强大预测能力的同时,也带来了深刻的黑箱问题:其内部计算往往过于复杂,无法被受影响的个人、部署模型的从业者乃至负责监管的机构所理解。 这一黑箱问题催生了两个研究密集型领域。第一个是算法公平性,研究自动系统是否在不同人口群体间产生公平的结果。第二个是可解释人工智能,致力于开发使模型行为可理解、透明和可问责的方法。 尽管这两个领域各自已相当成熟,但它们的交叉点——即解释本身的公平性作为一个独立的研究对象——受到的关注相对有限。当前XAI研究中的一个常见假设是解释方法能为所有群体提供统一的信息价值,而公平性研究中的一个常见假设是偏见存在于模型的预测结果中,而不是导致这些结果的推理过程中。这两个假设现在都受到了理论和经验的挑战。多项研究已证明,SHAP和LIME可以被故意欺骗,以在看似公平的解释背后隐藏歧视性行为,这种做法被正式化为洗白。 所有这些观察都指向一个更深层的问题:程序性偏见。当一个模型仅仅因为个体的保护属性不同而对其使用不同的推理过程时,就发生了程序性偏见。 图 1:程序不公平性的假想示例:两位假想贷款申请人获得相同结果,但他们的模型解释差异显著,这表明决策标准在受保护群体间不对称地应用。该图展示了程序性偏见的核心问题:满足结果公平的模型,其推理过程可能并不公平。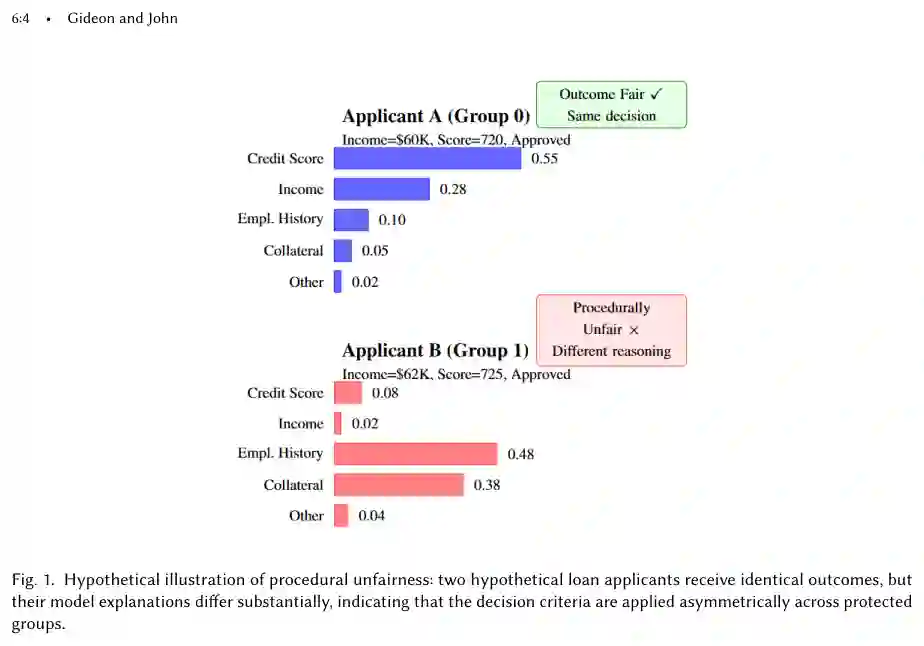
1.1 Scope and Contributions / 范围与贡献
本文的主要贡献包括:
- 条件不变性框架 提出一个正式的统一性原则,显示所有主要解释公平性指标都是单一条件不变性条件的部分操作化。
- 解释公平性五公理 从不变性条件和指标文献中提炼出五个设计公理,即过程一致性、反事实稳定性、分布平等、可行动性对称和认知可访问性。
- 可识别性障碍 将可识别性障碍正式化为命题1,并指出后验方法在结构上无法认证程序性公平。
- 生成机制分类 识别出三种解释不公平的生成路径:表征驱动的不平等、解释模型失配和可行动性驱动的不平等。
- 标准评估工作流 提出一个规范的六步审计协议。
- 明确限制 明确陈述了解释公平性无法保证的五点内容。
- 后验 vs. 内处理 vs. 本质可解释架构对比 将三种架构家族映射到五个公理。
- 研究要务 陈述了该领域必须构建的五项具体指令和七个优先级化的开放问题。
- 认知公平 引入认知公平概念,即所有群体平等地理解和依据解释采取行动的能力。
- 综合文献覆盖 调查了2016-2025年间超过300篇出版物。
1.2 Related Surveys / 相关综述
先前面向偏见的指南将解释仅视为诊断结果偏见的工具,从未将其视为偏见本身的来源。XAI综述则把公平性仅仅视为解释的一个期望属性,而非其评估维度。关于对抗性XAI的综述没有得出洗白不是一种病态攻击,而是所有后验解释固有的结构性风险的结论。这些综述的共同假设是解释公平性可被还原为结果公平性或解释质量。本文主张应将解释公平性视为一个独立的领域。
1.3 Survey Organization / 综述组织结构
第2节介绍公平性定义和XAI分类的背景。第3节介绍统一的条件不变性框架。第4节识别三种解释不公平的生成机制。第5至第11节分别调查各类方法的公平性问题。第12节介绍审计框架。第13节涵盖领域应用。第14节呈现研究议程。第15节总结。
2 Background / 背景
2.1 Fairness Definitions in Machine Learning / 机器学习中的公平性定义
公平性文献产生了广泛的定义,大致可分为群体公平性、个体公平性和因果公平性。群体公平性要求模型预测的统计属性在不同受保护群体间近似相等,如统计平等、等几率、机会均等等。个体公平性要求相似个体获得相似结果。因果公平性通过结构因果模型来模拟数据生成过程。
2.2 Explainable Artificial Intelligence: A Taxonomy / 可解释人工智能:一种分类法
XAI方法可按范围(局部 vs. 全局)、模型依赖性(模型无关 vs. 模型特定)、解释类型(特征重要性、反事实、规则、示例、概念)和时机(处理内 vs. 后验)进行分类。本文详细介绍了特征归因方法(SHAP、LIME、梯度方法)、反事实解释方法(DiCE、Wachter方法)、基于规则和示例的方法(ANCHOR、ProtoDash)以及基于概念和神经符号的方法。
3 A Unifying Framework: Explanation Fairness as Conditional Invariance / 一个统一框架:解释公平性作为条件不变性
本文调查的各种指标并非独立发明,而是对一个底层不变性条件的不同操作化。揭示这一结构将综述从文献综合提升为理论贡献。
3.1 The Core Invariance Principle / 核心不变性原则
定义1(解释公平性作为条件不变性):设 ( f: X \rightarrow Y ) 为一个模型,( E: X \rightarrow \mathcal{E} ) 为将输入映射到解释空间的解释函数。设 ( A ) 为取值于有限集 ( \mathcal{A} ) 的保护属性。设 ( X_{\text{rel}} \in \mathcal{X}{\text{rel}} \subseteq X \setminus {A} ) 为任务相关特征向量。一个解释函数 ( E ) 相对于 ( f ) 和 ( A ) 是公平的,当且仅当对所有 ( a, b \in \mathcal{A} ) 和所有 ( x{\text{rel}} \in \mathcal{X}{\text{rel}} ),有 ( P(E(X) \in \cdot \mid X{\text{rel}} = x_{\text{rel}}, A = a) = P(E(X) \in \cdot \mid X_{\text{rel}} = x_{\text{rel}}, A = b) )。 该等式意味着:在所有任务相关特征上相同的个体中,解释的分布不应取决于他们属于哪个受保护群体。
3.2 Existing Metrics as Partial operationalizations / 现有指标作为部分操作化
文献中的每个指标都在不同假设和权衡下近似了条件不变性。例如,ΔVEF 测量解释质量差异,GPFFAE 通过最大均值差异比较匹配的解释分布,EDiff 使用反事实对,GCIG 在学习过程中强制实现不变性,GESD 从稳定性角度进行测量,而 MESD 将其扩展到交叉群体。
3.3 Axioms of a Fair Explanation System / 公平解释系统的公理
我们从条件不变性原理和指标文献中提炼出五个设计公理,构成了高风险领域公平解释系统的最小要求:
- 公理1(过程一致性) 解释函数必须对相似的个体应用相同的决策标准。
- 公理2(反事实稳定性) 解释必须在保护属性反事实下保持稳定。
- 公理3(分布平等) 解释的群体水平分布不应因受保护群体而异。
- 公理4(可行动性对称) 依据解释采取行动的成本不应因群体而异。
- 公理5(认知可访问性) 解释必须对实际接收者是可解释和可行动的。
备注1:公理1-4可由现有指标测量;公理5目前尚无定量指标测量,这定义了认知公平的研究前沿。
3.4 The Identifiability Barrier / 可识别性障碍
命题1(解释公平性的可识别性):设 ( E: X \rightarrow \mathcal{E} ) 为任何仅通过输入输出行为访问模型 ( f ) 的后验解释方法。那么存在模型 ( f_{\text{fair}} ) 和 ( f_{\text{unfair}} ),使得:(a) ( f_{\text{fair}} ) 满足条件不变性;(b) ( f_{\text{unfair}} ) 违反条件不变性;但 (c) ( E ) 为两者分配相同的解释分布。证明概要采用了洗白文献中的构造方法。 备注2(后验解释的硬限):后验解释方法在结构上无法认证程序性公平。这不是一个可以通过更好的算法来解决的工程局限;它是模型无关访问的必然结果。一个通过所有后验解释公平性审计的系统,仍可能深具解释不公平性。 从因果视角看,解释不公平性是一种干预量,但仅能观察到观测分布。这指向一个更深层的因果结构:后验解释方法无法访问模型的内部因果结构,导致代理泄漏、替代不匹配和分布不对称。
4 Mechanisms of Explanation Inequity / 解释不平等的生成机制
在探讨解释不公平性在不同方法家族中的具体表现之前,本节先回答一个前置问题:解释不平等作为系统现象是如何产生的?理解生成机制至关重要,因为适当的补救措施完全取决于所针对的因果路径。 图 2:解释公平性的概念流程:偏差在多个阶段引入:训练数据中的历史偏差、模型学习中的代理泄漏、事后解释中的替代不匹配,以及人工解释中的认知差距。结果公平性和解释公平性都在模型表示的下游,但部分独立:一个模型可以满足其中一个而违反另一个。该图定位了三种生成机制在从数据到人类决策的管道中的位置。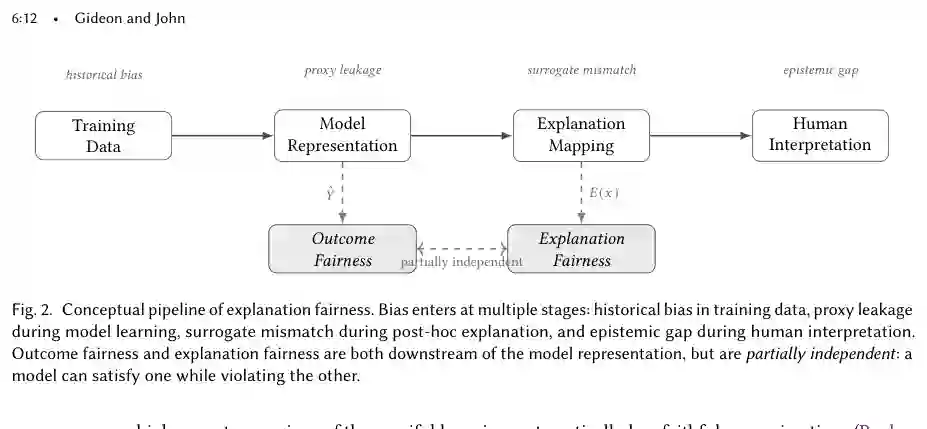
4.1 Pathway 1: Representation-Driven Inequity / 路径1:表征驱动的不平等
该路径源于模型学到的表征。当训练数据通过排斥、低代表性或代理相关性编码了历史歧视时,模型会为不同人口群体学习到系统性不同的表征。这些表征差异随后传播到解释中。其因果链条是可追溯的:数据不平衡 → 潜在嵌入偏斜 → 决策边界不对称 → 归因失真 → 补救途径不平等。
4.2 Pathway 2: Explanation-Model Mismatch / 路径2:解释模型失配
该路径源于后验解释方法本身的认知局限性。由于只能通过查询访问模型,后验解释器与模型实际推理之间存在不可消除的信息差距,表现为局部线性失败、对相关特征的边缘化以及对抗性利用。
4.3 Pathway 3: Actionability-Driven Inequity / 路径3:可行动性驱动的不平等
该路径在模型和解释器的下游运作,即从解释到行动的转化过程。即使解释准确报告了驱动决策的特征,不同人口群体依据解释采取行动的能力也存在系统性差异,表现为结构性补救障碍、时间过时和认知不对称。
4.4 How the Pathways Interact / 各路径如何相互作用
三条路径并非独立。表征驱动的不平等会放大解释模型失配;解释模型失配使得对可行动性不对称的对抗性利用成为可能;时间过时与所有三条路径相互作用。这意味着仅审计一条路径可能会导致遗漏。
5 Fairness of Feature Attribution Methods / 特征归因方法的公平性
特征归因方法是部署ML系统中后验解释的主导范式,但其本身并不固有地公平。
5.1 Disparate Explanation Quality Across Groups / 不同群体间的不同解释质量
模型可能在某些人口群体上产生系统性更低的解释质量(如保真度、稳定性、简洁性)。例如,Begley等人发现SHAP和LIME在少数族裔患者上的解释保真度和稳定性显著更低,这导致“双重困境”:最受潜在歧视性医疗预测影响的群体,得到了最不可靠的解释。
5.2 Adversarial Manipulation of Explanations and Fairwashing / 解释的对抗性操纵与洗白
后验方法对故意操纵的脆弱性是该领域最重大的发现之一。Slack等人展示了具体的攻击:有偏分类器配以检测机制,在被审计时用一个无害的分类器替换自身。Aivodji等人将洗白形式化。Anders等人证明,在自然的公理化条件下,解释方法无法区分公平和不公平的模型。
5.3 Bias in SHAP and LIME Attributions / SHAP和LIME归因中的偏见
SHAP对特征相关性的处理是其公平性应用的一个根本问题。当与保护属性相关的代理特征存在时,归因权责会在它们之间以在技术上正确但在社会上误导的方式分配。
5.4 Equalized Explainability and Mitigation / 均衡可解释性与缓解措施
Wang和Wu提出“均衡可解释性”作为目标,要求解释向量的分布在不同人口群体间相同。他们通过数据重构方法实现该目标。
5.5 Synthesis: Mechanisms of Attribution Fairness Failure / 归因公平性失败的机制综合
跨文献发现,特征归因方法在公平性维度上失效的四个重复出现的机制:表征差异源于训练数据不平衡导致的少数群体特征空间稀疏;对抗性操纵源于模型无关后验方法的固有脆弱性;代理相关性导致的归因混淆;以及时间稳定性问题导致的补救途径过时。 图 3:从论文PDF第4页提取的配图,展示了与公平性相关的另一个假想场景或框架示意图。来源:原论文PDF第4页。
6 Procedural Fairness and Explanation Difference Metrics / 程序公平性与解释差异指标
本节审视旨在直接量化和缓解程序性偏见的方法。
6.1 Philosophical Foundations of Procedural Fairness / 程序公平性的哲学基础
程序公平性植根于社会心理学(Thibaut & Walker)和政治哲学(Rawls),要求评估过程本身公平,而不仅仅是结果公平。
6.2 Ratio-Based and Value-Based Explanation Fairness (REF, VEF) / 基于比率和基于价值的解释公平性(ΔREF,ΔVEF)
ΔREF衡量群体间解释质量比值的差异,ΔVEF衡量期望价值的差异。它们提供了对条件不变性条件(公式4)的简单度量,但仅捕捉分布的一阶矩。
6.3 Group Procedural Fairness via Feature Attribution (GPFFAE) / 基于特征归因的群体程序公平性
GPFFAE通过最大均值差异(MMD)比较匹配的解释分布,捕捉分布形状差异,比均值比较更强,但需要匹配步骤。
6.4 Explanation Difference (EDiff) / 解释差异度量
EDiff使用反事实对直接操作化条件不变性。通过比较同一个体在不同保护属性下的解释差异,消除混淆。该度量与FastSHAP结合实现训练时计算。
6.5 Group-Level Explanation Stability Disparity (GESD) and FEU / 群体级解释稳定性差异与公平性进化优化
GESD从稳定性角度操作化不变性:测量每个群体解释在输入扰动下的变化程度。FEU(公平性进化优化)框架使用多目标进化算法联合优化GESD与其他公平性目标。
6.6 Group Counterfactual Integrated Gradients (GCIG) and FairX / 群体反事实积分梯度与FairX
GCIG在学习过程中强制实现不变性:计算相对于分组条件基线的积分梯度,并将其差异作为可微正则化损失进行惩罚。FairX是该框架的全称,是首个在训练时强制解释公平性的方法。
6.7 Procedural Bias: Sources and Implications / 程序性偏见:来源与启示
程序性偏见源于模型对不同群体使用不同的推理过程,其影响包括:误导性解释、补救途径不平等、以及不可审计的歧视。
7 Multi-Objective Optimization for Joint Fairness / 联合公平性的多目标优化
将结果公平性、解释公平性和预测准确性视为必须通过多目标优化来权衡的冲突目标。
7.1 The Multi-Objective Perspective on Algorithmic Fairness / 算法公平性的多目标视角
传统的公平性研究通常处理单一目标(如统计平等),但实际部署需要同时满足多个公平性标准,这些标准之间可能冲突。
7.2 Pareto Fronts and Scalarization in Fairness / 帕累托前沿与公平性中的标量化
多目标优化通过帕累托前沿描述不可同时最优的目标之间的权衡。标量化方法将多个目标组合为单目标。
7.3 AnyLoss: Differentiable Fairness Metric Optimization / AnyLoss:可微公平性指标优化
AnyLoss框架提供了一种将任何公平性指标转化为可微损失函数的方法,使其可以用于梯度下降优化。
7.4 Joint Fairness and Explanation Algorithms / 联合公平性与解释算法
同时考虑结果公平性和解释公平性的算法,例如FairMOE(多目标解释)中的联合优化。
7.5 Fairness Optimization / 公平性优化
统称所有旨在调整模型参数或训练过程以提升公平性的方法,包括预处理、处理中和后处理策略。
7.6 The Fairness-Accuracy-Explainability Trilemma / 公平-准确-可解释三难困境
关键内容(从Section6移至此):EDiff的作者证明了这一困境,它反映了深层结构张力,而非工程权衡。同时实现高预测准确性、结果公平性(如等几率)和程序公平性是固有的难解问题。现有方法只能在三者之间寻找合理折衷。
8 Fairness of Counterfactual Explanations and Algorithmic Recourse / 反事实解释与算法补救的公平性
反事实解释旨在回答“需要对输入做怎样的最小改变才能翻转预测?”
8.1 Recourse Burden Disparities / 补救负担差异
不同群体实现相同结果所需的行动成本(如收入提升、居住地变化)存在系统性差异,这构成了结构性的补救障碍。
8.2 Individual Fairness in Counterfactual Explanations / 反事实解释中的个体公平性
要求反事实解释本身对相似个体保持公平,即相似的个体应获得相似的反事实建议。
8.3 Multi-Dimensional Fairness in Recourse / 补救中的多维公平性
不仅考虑成本,还考虑可行性、可访问性、时间敏感度等多维因素。
8.4 Causal Recourse and Causal Graph Constraints / 因果补救与因果图约束
利用结构因果模型确保反事实建议在因果上可行且有效,避免产生误导性的补救路径。
9 Fairness in Graph-Structured Explanation Methods / 图结构解释方法的公平性
图神经网络(GNN)中的偏见放大是一个关键关注点。
9.1 Bias Amplification in Graph Neural Networks / 图神经网络中的偏见放大
同质性泄露导致邻域聚合将受保护属性信息传播到节点表示中,即使该属性已被显式排除,从而放大偏见。
9.2 GNN Explanation Methods / GNN解释方法
针对图结构的解释方法包括子图归因(如GNNExplainer)、节点归因(如集成梯度)等。
9.3 Structural Explanation of Bias in GNNs / GNN中偏见的结构性解释
通过结构分析揭示偏见如何在图拓扑中传播,识别不公平的局部模式。
9.4 Fairness Explanation in GNN-Based Recommendation / 基于GNN的推荐中的公平性解释
在推荐系统中,GNN解释的公平性直接影响消费者的信任和满意度。
9.5 Fairness Metrics for GNN Explanations / GNN解释的公平性度量
针对图结构数据设计的公平性指标,如REFEREE、BIND等,衡量子图解释在不同群体间的公平性。
10 Intersectional Fairness and Fairness Gerrymandering / 交叉公平性与公平性选区划分
公平性选区划分:一个系统可能在所有边缘群体上满足公平性,但在其交叉处(例如,黑人女性)严重违反公平性。
10.1 Crenshaw's Intersectionality and its ML Translation / Crenshaw的交叉性及其在ML中的翻译
交叉性理论(Crenshaw)强调社会分类(如种族、性别)相互叠加产生独特的歧视模式,在ML中需要同时考虑多个受保护属性。
10.2 Fairness Gerrymandering / 公平性选区划分
当公平性指标仅在边缘群体上满足,但未在交叉子群体上进行测试时,系统可能通过“选区划分”规避公平性约束。
10.3 Intersectional Fairness of Explanations / 解释的交叉公平性
要求解释方法在所有交叉子群体上满足条件不变性,而不仅仅是边缘群体。
10.4 Survey of Intersectional Fairness Methods / 交叉公平性方法综述
包括Kearns等人的子群方法、Foulds等人的差分公平性、Hébert-Johnson等人的多校准等。
10.5 Multi-Category Explanation Stability Disparity (MESD) and UEF / 多类别解释稳定性差异与统一公平性框架
MESD指标明确为交叉子群体设计,通过笛卡尔积构建子群、经验贝叶斯收缩处理稀疏细胞、CVaR尾权重加权,防止解释层面的公平性选区划分。UEF是统一公平性框架。
11 Beyond Attributions: Rule, Example, Concept, and Neurosymbolic Methods / 超越归因:规则、示例、概念和神经符号方法
11.1 Rule-Based Explanations and Fairness / 基于规则的解释与公平性
ANCHOR等规则方法提供可理解的条件逻辑,但其公平性取决于规则是否在各群体间一致适用。片面规则可能导致隐性偏见。
11.2 Example-Based Methods and Fairness / 基于示例的方法与公平性
原型和批评方法(ProtoDash)通过代表性示例解释决策,但示例选择可能偏袒多数群体,导致少数群体缺乏代表性解释。
11.3 Concept-Based Explanations and Fairness / 基于概念的解释与公平性
TCAV和概念瓶颈模型使用高级概念进行解释,但概念定义本身可能带有文化偏见,从而影响公平性。
11.4 Epistemic Fairness: Explanation as the Ability to Act / 认知公平:解释作为行动能力
认知公平的核心论断是:归因平等不足以实现认知公平。一个群体获得与另一个群体相同的特征归因向量,并不意味着他们能以平等的成本理解该解释并据此采取行动。公理5(认知可访问性)是唯一未被现有指标测量的公理,定义了研究前沿。
11.5 Neurosymbolic Methods and Fairness / 神经符号方法与公平性
神经符号方法(如逻辑张量网络)允许将公平性公理编码为逻辑子句,在训练中强制满足,提供内在公平性保证。
12 Auditing Frameworks for Explanation Fairness / 解释公平性审计框架
12.1 Post-Hoc Measurement Frameworks / 后验测量框架
基于审计公差的度量框架,如ΔVEF、GPFFAE等,可在模型部署后计算,但受可识别性障碍限制,无法提供绝对的公平性保证。
12.2 Recommended Evaluation Workflow / 推荐的评估工作流
我们提出了一个规范化的六步审计工作流,旨在探测试图2中的三条生成路径:
- 指标参数化:明确定义保护属性、任务相关特征及代理变量。
- 自动化度量计算:计算条件不变性(第3.2节)的公开指标,如ΔVEF、GPFFAE等。
- 稳定性评估:对解释进行扰动分析,以检测GESD捕捉到的脆弱性。
- 补救途径检查:评估群体间补救成本的差异(第4.3节)。
- 认知公平评估:需要进行人为主体研究,以评估公理5(认知可访问性)。
- 交叉分析:跨交叉群体重新运行前五个步骤,以检测公平性选区划分。
12.3 Failure Taxonomy and Remediation Map / 失败分类与补救地图
一个结构化失败分类(见表10),将每类失败映射到具体的补救策略,帮助从业者诊断问题并选择干预方法。
12.4 Practitioner Decision Guide: Choosing an Explanation Fairness Method / 从业者决策指南:选择解释公平性方法
一个决策表(见表11),根据部署约束(如模型可解释性需求、计算预算、领域要求)指导选择最合适的解释公平性方法。
12.5 What Explanation Fairness Cannot Guarantee / 解释公平性无法保证的内容
- 后验方法无法认证公平性。
- 解释公平性 ≠ 模型公平性。
- 后验方法无法确保因果中立性。
- 认知不平等对统计指标不可见。
- 可识别性障碍是永久的。
12.6 Regulatory Context / 监管背景
解释公平性越来越受到监管关注(如欧盟AI法案、美国AI问责框架),要求模型提供者证明公平性,但现有审计方法无法完全满足监管需求,亟需新的理论指导和标准化审计协议。
13 Domain Applications / 领域应用
13.1 Criminal Justice and Recidivism Prediction / 刑事司法与再犯预测
再犯预测模型(如COMPAS)在种族间存在解释不公平性,即使结果公平度拉平,解释(SHAP)仍显示系统性差异。
13.2 Healthcare and Clinical Decision Support / 医疗与临床决策支持
医疗模型对少数族裔患者的解释质量更低,导致临床医生难以信任或纠正偏见。时间过时在动态流行病学中尤为突出。
13.3 Credit and Lending / 信贷与借贷
信贷评分模型中的代理特征(如地区邮编)导致解释偏袒多数群体,且反事实补救成本对少数群体更高。
13.4 Employment and Hiring / 就业与招聘
招聘模型在简历筛选中产生解释性不公平,例如不同性别或种族的候选人在“关键技能”上获得不一致的解释权重。
13.5 Cross-Domain Synthesis: Structural Features of High-Stakes Explanation Fairness / 跨域综合:高风险解释公平性的结构特征
四个领域的共同特征:代理相关性无处不在、数据分布偏移影响各群体不均、补救成本存在结构性障碍、认知公平需求普遍存在。这些特征要求解释公平性审计必须包含交叉分析和时间鲁棒性检查。
14 Research Agenda: Imperatives and Open Problems / 研究议程:要务与开放问题
14.1 Research Imperatives / 研究要务
- 可证明公平的固有可解释架构。
- 可扩展的认知公平方法。
- 跨域审计协议。
- 时间鲁棒性约束。
- 交叉性和反事实方法。
14.2 Open Problems, Prioritized by Urgency and Tractability / 紧急性和可操作性排序的开放问题
- 如何设计满足所有公理的内处理解释系统?
- 何时可以绕过可识别性障碍?
- 什么是鲁棒且可扩展的认知公平度量?
- 如何设计同时考虑结果和解释交叉公平性的训练算法?
- 如何设计在长期部署中保持公平性保证的解释?
15 Conclusion / 结论
本文提供了首个关于人工智能解释公平性的统一综述,建立了条件不变性作为统一定义,并强调了其作为积极可设计目标的地位。