
如果说过去两年大模型竞争的关键词是“推理能力”,那么 DeepSeek-V4 这篇技术报告给出的新关键词,可能是:百万级上下文的高效推理。

DeepSeek-AI 在论文《DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence》中发布了 DeepSeek-V4 系列的预览版本,包括两个 MoE 语言模型:DeepSeek-V4-Pro和DeepSeek-V4-Flash。前者总参数规模为 1.6T、每 token 激活 49B 参数;后者总参数规模为 284B、每 token 激活 13B 参数。两者共同指向一个目标:在保持较强通用能力的同时,原生支持100 万 token 上下文窗口。这不是简单地把上下文窗口“拉长”。真正难的是:当上下文扩展到百万 token,注意力计算、KV Cache 存储、推理延迟、训练稳定性都会迅速成为瓶颈。DeepSeek-V4 的核心价值,就在于它试图把“能处理长文本”推进到“能高效、常规化地处理长文本”。
一、为什么百万 token 上下文重要?
过去的大模型长上下文能力,很多时候更像是一种“能力展示”:模型可以塞进很长的输入,但推理成本高、KV Cache 占用大、长文检索性能衰减明显,真正投入复杂业务流程并不容易。DeepSeek-V4 面向的场景更进一步:复杂 Agent 工作流;超长代码库理解与修改;跨文档、跨报告的系统分析;企业级知识库问答;长周期、多轮任务执行;未来可能出现的在线学习和持续记忆式系统。论文开篇指出,当前 test-time scaling 让推理模型能力提升明显,但传统注意力机制的二次复杂度限制了超长上下文和长推理链的发展。换句话说,如果推理越做越长、任务越做越复杂,模型就必须解决“长程信息处理的效率问题”。
二、DeepSeek-V4 的一句话概括
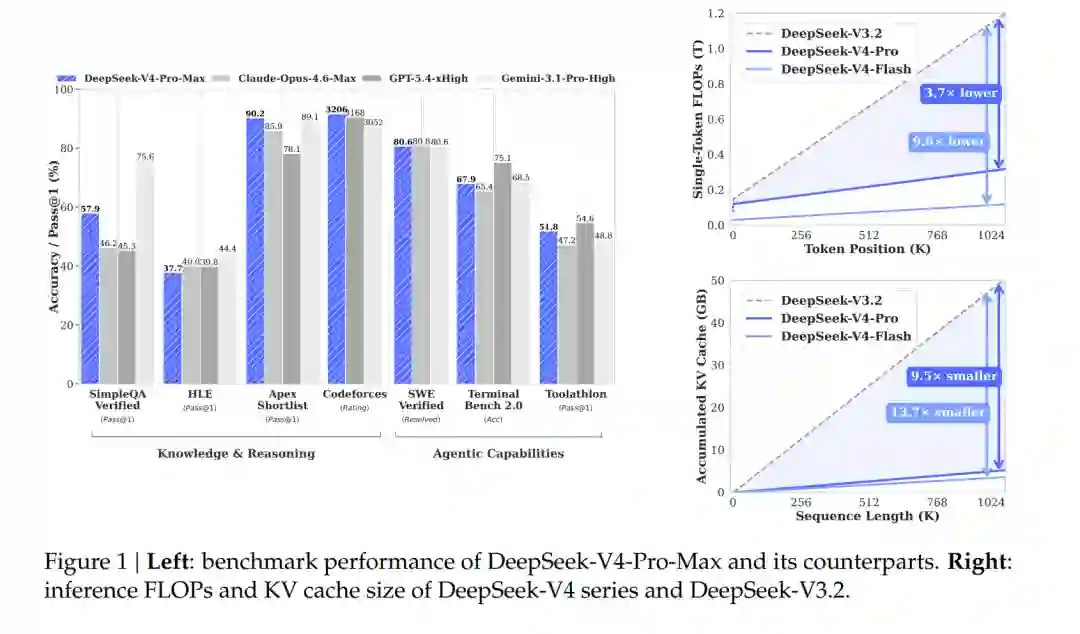
DeepSeek-V4 可以理解为一次围绕“长上下文效率”的系统级升级:用混合注意力降低长序列计算和 KV Cache 成本,用 mHC 提升深层信号传播稳定性,用 Muon 优化器改善大规模训练收敛,再配合 FP4、MoE 通信计算重叠、KV Cache 管理等系统优化,把百万 token 上下文推向可用。论文称,在 100 万 token 上下文场景下,DeepSeek-V4-Pro 相比 DeepSeek-V3.2 只需要约27% 的单 token 推理 FLOPs和10% 的 KV Cache;DeepSeek-V4-Flash 进一步降低到约10% 的单 token 推理 FLOPs和7% 的 KV Cache。这组数字是理解 DeepSeek-V4 的关键:它的重点不是“更大”,而是让长上下文变得更便宜。
三、架构核心:CSA + HCA,压缩注意力的两条路线
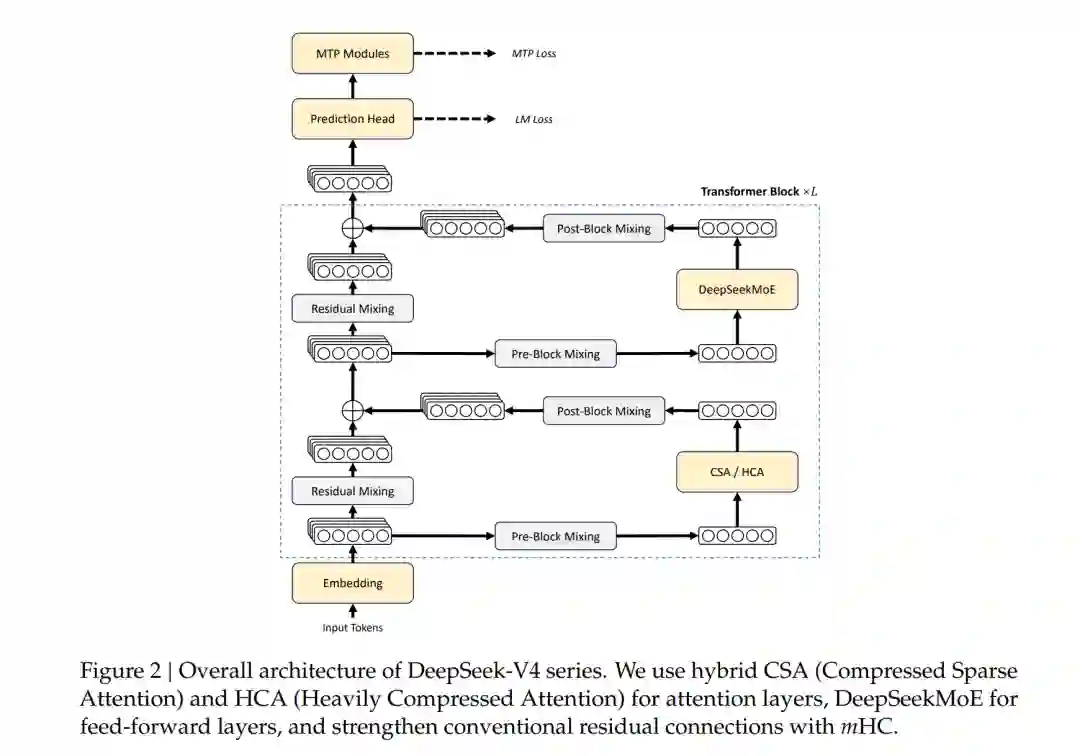
DeepSeek-V4 最重要的架构变化,是混合注意力机制:Compressed Sparse Attention,CSA与Heavily Compressed Attention,HCA。
1. CSA:先压缩,再稀疏选择
CSA 的思路是:先把 KV Cache 沿序列维度压缩,每 m 个 token 压缩成一个 KV entry;然后再通过稀疏选择,让每个 query token 只关注 top-k 个压缩后的 KV entry。可以把它理解成:面对一本百万字的书,模型不是每次都逐字查找,而是先把书压缩成一系列信息块,再根据当前问题挑选最相关的信息块阅读。论文第 9 页的图 3 展示了 CSA 的结构:隐藏状态先经过 token-level compressor 生成压缩 KV,再由 Lightning Indexer 计算索引分数,选择 top-k 压缩 KV,最后进入共享 Key-Value 的 Multi-Query Attention。
2. HCA:更激进地压缩,但保持 dense attention
HCA 的压缩更强:每 m′ 个 token 压缩成一个 KV entry,其中 m′ 远大于 CSA 中的 m。不同的是,HCA 不再做稀疏选择,而是在强压缩后的 KV 上保持 dense attention。这相当于用更粗粒度的“全局摘要”来维护长距离信息。论文第 11 页的图 4 展示了 HCA:它把更长片段的 KV 合并成少量 heavily compressed KV entries,并额外保留滑动窗口 KV,以补足局部细粒度依赖。
3. 滑动窗口分支:补上局部细节
压缩注意力有一个天然风险:压缩会损失局部精细信息。DeepSeek-V4 因此在 CSA 和 HCA 中都加入了滑动窗口注意力分支,让模型始终能够访问最近一段未压缩的 token。这体现了一种典型设计平衡:远距离信息靠压缩,近距离依赖靠原始窗口。
四、mHC:不只是“残差连接”,而是更稳定的深层信息通道
DeepSeek-V4 另一个结构升级是Manifold-Constrained Hyper-Connections,mHC。传统 Transformer 依赖残差连接在层间传递信息。mHC 的目标是加强这种连接,同时避免普通 Hyper-Connections 在深层堆叠时可能出现的数值不稳定。论文的做法是:将残差映射矩阵约束到双随机矩阵流形,也就是 Birkhoff polytope。这样可以让映射的谱范数不超过 1,使残差变换具备非扩张性,从而增强前向传播和反向传播的稳定性。这部分虽然比较数学,但它背后的工程意义很清楚:当模型规模大、层数深、训练序列长时,任何微小的不稳定都可能被放大。mHC 是在为更大规模、更长上下文训练提供稳定性支撑。
五、Muon 优化器:把训练稳定性也纳入架构设计
DeepSeek-V4 采用 Muon 优化器更新大部分模块,同时保留 AdamW 用于 embedding、prediction head、RMSNorm 等部分模块。Muon 的核心特征是对更新矩阵做近似正交化。论文中使用了 hybrid Newton-Schulz iterations,以提升收敛速度和训练稳定性。值得注意的是,DeepSeek-V4 并没有只从模型结构上解决长上下文,而是把优化器、训练策略、数值稳定性和系统实现全部纳入同一套设计中。这也是这篇论文更像“系统工程报告”而不仅是“模型结构论文”的原因。
六、训练数据与预训练:长文档成为重点资产
DeepSeek-V4 的预训练语料超过 32T token,包含数学、代码、网页、长文档等高质量数据。论文特别提到,DeepSeek-V4 更重视长文档数据构建,优先考虑科学论文、技术报告等具有学术价值的材料。具体训练规模上:DeepSeek-V4-Flash 训练 32T token;DeepSeek-V4-Pro 训练 33T token;训练序列长度从 4K 逐步扩展到 16K、64K,最终到 1M。这说明 DeepSeek-V4 的百万上下文不是后期简单外推,而是在训练过程中逐步引入长序列,使模型原生适应超长上下文处理。
七、后训练:从“多专家专训”到 On-Policy Distillation
DeepSeek-V4 的后训练采用两阶段范式:第一阶段,分别训练数学、代码、Agent、指令跟随等领域专家模型;第二阶段,通过On-Policy Distillation,OPD把多个专家能力整合到统一模型中。论文指出,基础模型先通过高质量领域数据做 SFT,再使用 GRPO 进行强化学习,形成多个领域专家;随后统一模型作为学生,在自身生成轨迹上学习教师模型的分布,以 reverse KL loss 进行多教师蒸馏。这点很关键。传统多能力融合经常面临“混合训练相互干扰”或“权重合并性能退化”的问题。DeepSeek-V4 选择用 logits-level 的 on-policy distillation,把不同专家能力压缩进一个统一参数空间。
八、评测结果:强项是长上下文、推理和开放模型竞争力
在基础模型评测中,DeepSeek-V4-Flash-Base 虽然激活参数少于 DeepSeek-V3.2-Base,但在多数 benchmark 上超过后者;DeepSeek-V4-Pro-Base 则在知识、推理、代码、长上下文等方面全面领先 DeepSeek 系列前代基础模型。论文表 1 显示,在 LongBench-V2 上,DeepSeek-V4-Pro-Base 得到 51.5,高于 DeepSeek-V4-Flash-Base 的 44.7 和 DeepSeek-V3.2-Base 的 40.2。在后训练模型方面,论文表 6 给出了 DeepSeek-V4-Pro-Max 与多个开源、闭源模型的对比。DeepSeek-V4-Pro-Max 在 SimpleQA-Verified 上为 57.9,HLE 为 37.7,Codeforces rating 为 3206,SWE Verified 为 80.6,Toolathlon 为 51.8。论文同时强调,它在知识评测上缩小了与领先闭源模型的差距,但并未在所有维度超过闭源前沿模型。这类表述需要谨慎:DeepSeek-V4 的确在开放模型中表现强劲,但论文自身也承认,在部分知识、Agent 和闭源前沿比较中仍存在差距。
九、百万上下文:不是“能塞进去”,而是能保持较强检索能力
长上下文模型最容易被质疑的问题是:窗口很长,但模型是否真的能用上?论文在 1M-token context 下使用 MRCR 和 CorpusQA 评估长上下文能力。结果显示,DeepSeek-V4-Pro 在 MRCR 上优于 Gemini-3.1-Pro,但低于 Claude Opus 4.6;在 CorpusQA 上也优于 Gemini-3.1-Pro。图 9 显示,在 128K 以内,DeepSeek-V4 系列检索表现比较稳定;超过 128K 后性能有所下降,但到 1M token 时仍保持较强能力。这比单纯宣传“百万上下文”更重要:论文承认长上下文性能会随长度下降,但试图证明下降幅度仍在可接受范围内。
十、真实任务:写作、搜索、办公、代码 Agent
论文还专门评估了真实世界任务,这部分对产业读者更有参考价值。
中文写作
DeepSeek-V4-Pro 在功能性中文写作任务中相对 Gemini-3.1-Pro 获得 62.7% 胜率;在创意写作中,指令跟随胜率为 60.0%,写作质量胜率为 77.5%。但在高复杂约束或多轮场景中,Claude Opus 4.5 仍有优势。
搜索问答
论文区分了 RAG 和 agentic search。DeepSeek-V4-Pro 相比 DeepSeek-V3.2 在搜索问答中明显提升;agentic search 相比普通 RAG 在复杂任务上表现更好,但成本只略高于标准 RAG。
白领任务
DeepSeek 构建了 30 个高级中文专业任务,覆盖金融、教育、法律、科技等 13 个行业。评估显示,DeepSeek-V4-Pro-Max 相对 Opus-4.6-Max 的整体 non-loss rate 为 63%,优势主要体现在任务完成度和内容质量,但在格式审美、极简摘要和部分格式约束上仍有改进空间。
代码 Agent
论文从 50 多位内部工程师收集约 200 个复杂研发任务,经过筛选保留 30 个任务作为评测集。结果显示,DeepSeek-V4-Pro-Max 的通过率为 67%,高于 Claude Sonnet 4.5 的 47%,接近 Claude Opus 4.5 的 70%,但低于 Opus 4.6 Thinking 的 80%。
十一、系统工程:百万上下文不是模型单点创新,而是全栈优化
DeepSeek-V4 的论文中很大篇幅用于基础设施,包括:MoE 专家并行中的通信计算重叠;TileLang 内核开发;batch-invariant 和 deterministic kernel;FP4 量化感知训练;长上下文 attention 的上下文并行;异构 KV Cache 管理;on-disk KV Cache 存储;面向 Agent 的沙箱基础设施 DSec。这些内容说明,百万 token 上下文不是靠单一算法实现的,而是模型架构、训练框架、推理系统、存储策略、工具调用基础设施共同协作的结果。尤其是 KV Cache 管理,论文指出 DeepSeek-V4 的混合注意力会产生不同类型、不同尺寸、不同更新规则的 KV entries,因此传统 PagedAttention 假设不再完全适用,需要定制化 KV cache layout。
十二、局限性:论文自己也承认,架构还不够“优雅”
DeepSeek-V4 的结论部分并没有只做乐观总结。论文明确提到,为追求极致长上下文效率,DeepSeek-V4 采用了较大胆的架构设计;为了降低风险,保留了许多初步验证有效的组件和技巧,这也使得架构相对复杂。未来需要更系统地研究,提炼出更本质、更简洁的设计。此外,论文还提到 Anticipatory Routing 和 SwiGLU Clamping 虽然能缓解训练不稳定,但其底层机理仍不充分清楚。未来方向包括进一步研究训练稳定性、探索新的稀疏维度、降低长上下文延迟、加强长程多轮 Agent 任务,以及加入多模态能力。这部分值得重视:DeepSeek-V4 不是一个“完美终点”,而更像是一次面向百万上下文时代的系统性预演。
结语:大模型的下一步,可能不是更会答题,而是更能“长期工作”
DeepSeek-V4 最值得关注的地方,不只是 benchmark 分数,而是它提出了一个方向:大模型正在从短轮次问答系统,转向能够处理长文档、长任务、长推理链和长周期 Agent 工作流的系统。过去,模型像是一个聪明的答题者;未来,模型可能更像一个可以持续阅读、持续规划、持续执行的智能工作单元。而百万 token 上下文,正是这条路上的关键基础设施之一。DeepSeek-V4 的意义也在这里:它没有简单地把模型做大,而是试图把长上下文推理的成本降下来,让“长程智能”不再只是实验室里的演示能力,而更接近真实产品和真实工作流中的常规能力。
