

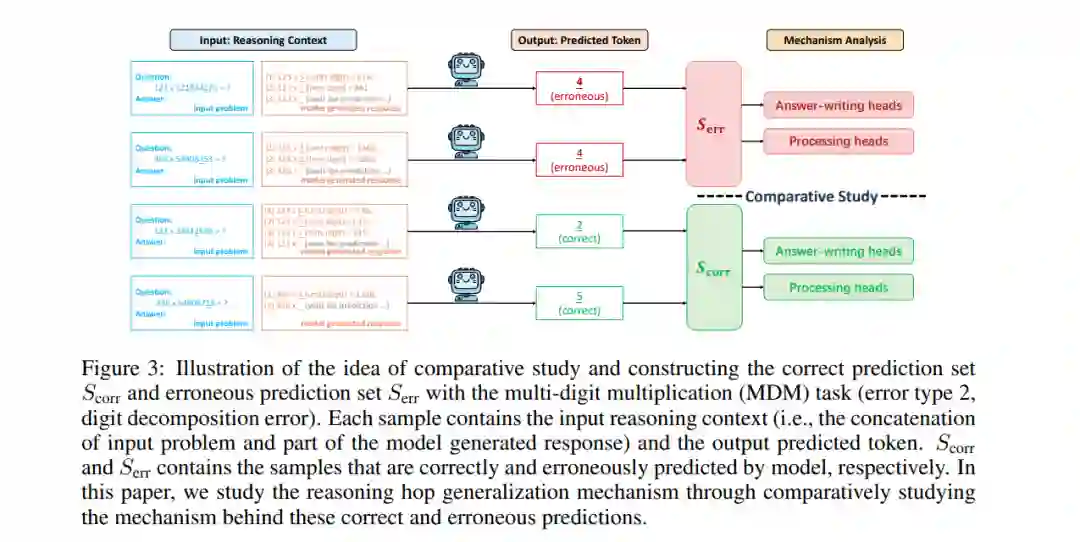
思维链(Chain-of-thought, CoT)推理已成为大语言模型(LLMs)解决复杂问题的标准范式。然而,近期研究表明,在推理步数泛化(Reasoning hop generalization)场景下——即底层算法保持不变,但所需推理步数超出训练分布时——模型性能会出现剧烈下降。导致这一失效的内部机制尚不明确。 本研究对多领域的任务进行了系统性实验,发现错误并非均匀分布,而是集中在少数关键错误类型的 Token 位置上。进一步观察显示,这些 Token 级别的错误预测源于内部竞争机制(Internal competition mechanisms):某些特定的注意力头,即错误处理头(Erroneous processing heads, ep heads),通过放大错误的推理轨迹并抑制正确的轨迹,打破了表征的平衡。值得注意的是,在推理阶段移除单个 ep head 往往就能恢复正确的预测。
受此启发,我们提出了测试时推理修正(Test-time correction of reasoning)。这是一种轻量级的干预方法,能够在推理过程中动态识别并停用 ep heads。在不同任务和多种 LLM 上的广泛实验表明,该方法显著提升了推理步数的泛化能力,彰显了其有效性与应用潜力。
成为VIP会员查看完整内容
相关内容

最新内容
相关VIP内容
相关资讯