
ICML 2026 Spotlight | SmoothSMoE:从几何与随机过程理解稀疏 MoE 的路由不连续
论文标题:Geometric and Stochastic Analysis of Discontinuities in Sparse Mixture-of-Experts 论文链接:https://arxiv.org/abs/2606.19036 代码链接:https://github.com/thotranhuu99/Smooth_SMoE 作者机构:National University of Singapore;Ho Chi Minh City University of Technology, VNU-HCM

稀疏 MoE 已经成为大模型扩展的重要路线:模型可以拥有很多专家,但每个 token 只激活少数专家,从而在参数规模和计算成本之间取得折中。问题在于,最常见的 Top-k 路由本质上是一个硬选择:只要某个专家分数跨过第 k 个阈值,激活集合就会突变。
这篇 ICML 2026 Spotlight 论文关注的正是这个看似细小、但会影响稳定性的结构问题:Top-k Sparse Mixture-of-Experts 的输入输出映射天然不连续。作者不仅指出不连续存在,而是从几何测度和随机过程两个角度分析这些不连续边界的形状、规模和被扰动轨迹撞上的概率,并据此提出一个可直接套在现有 SMoE 上的局部平滑方法 SmoothSMoE。
导读
这篇论文的核心信息可以压缩成三句话。 第一,Top-k 路由把输入空间切成很多“专家组合固定”的区域,区域边界就是专家得分打平的位置;在边界附近,极小输入扰动可能让激活专家集合发生跳变。 第二,不同类型的不连续并不一样。两两专家在阈值附近打平的一阶不连续占主导,高阶多专家同时打平的区域在相对体积上快速变小;随机扰动轨迹第一次撞到边界时,几乎总是撞到一阶不连续。 第三,既然真正重要的是边界附近的一阶近邻,平滑不必全局替换 Top-k 路由。SmoothSMoE 只在接近阈值的专家上做局部软加入,在保持稀疏性的同时消除局部跳变,并在语言建模、GLUE、DomainBed 和大规模视觉语言模型实验中带来稳定收益。
1. 为什么 Top-k MoE 会有不连续性
标准 MoE 可以写成多个专家函数的加权组合。稀疏 MoE 的区别在于,路由器不会让所有专家都参与计算,而是根据 gating logits 选出得分最高的 k 个专家。这样做非常高效,也正是 Switch Transformer、DeepSeekMoE 等稀疏架构能够扩展的基础。 但 Top-k 有一个结构性代价:激活集合是离散变化的。设第 k 个专家和第 k+1 个专家的 gating score 非常接近,那么输入只要发生一点扰动,就可能让它们的排序互换。对于普通连续函数,这种微扰只会造成小幅输出变化;但对 Top-k SMoE 来说,路由集合可能直接从一组专家切到另一组专家,输出也可能发生非连续跳变。 作者把这种边界称为不连续集合。直观地说,输入空间被 Top-k 路由划分成许多 cell,在同一个 cell 内激活专家固定,函数相对稳定;跨过 cell 边界时,激活专家发生切换,SMoE 映射就可能出现跳跃。 这也是本文与多数“连续路由”工作的差别。已有方法往往通过全局软化路由、融合专家或重训 gating 来避免硬切换,但可能改变原有 Top-k 结构、增加训练成本,或不适合自回归生成。本文希望回答一个更基础的问题:这些不连续边界到底长什么样?随机扰动最可能碰到哪些边界?如果只在真正危险的位置平滑,是否足够?
2. 问题建模:按“打平专家数”划分不连续阶数
论文首先把 Top-k SMoE 的不连续性形式化。给定 M 个专家和 Top-k 路由,当一个已激活专家与一个未激活专家在第 k 个阈值附近打平时,就会形成最简单的路由切换边界。作者称这种两两打平为一阶不连续。 如果同时有更多专家在阈值附近打平,就得到更高阶的不连续。例如三个专家同时处在切换临界位置,可以看作二阶不连续;更多专家同时打平则对应更高阶。这个“阶数”不是优化阶数,而是描述一次切换事件中有多少专家共同参与 tie。 这种定义很重要,因为它把“路由不稳定”从笼统现象变成了可以度量的几何对象:一阶边界像超平面,高阶边界像多个超平面的交集,维度更低,也更难被随机轨迹精确撞上。
3. 几何结论:一阶不连续占主导
从几何角度看,真正的问题不是“不连续集合是否有测度”。严格地说,这些边界本身通常是测度为零的集合;但模型输入不需要精确落在边界上,只要落在边界附近,就可能出现激活专家不稳定。 因此作者研究的是边界的 epsilon-thickening,也就是把不连续集合向外扩一层很薄的邻域,问这个邻域在输入空间中占多大体积。论文通过测度论切片论证,得到一个核心结论:阶数越高,其厚化邻域的相对体积衰减越快;当半径尺度变大或 epsilon 变小时,低阶不连续,尤其是一阶不连续,占据主导。 这给了一个非常直接的工程启发:如果要修复 Top-k 的不连续问题,不必把所有可能的高阶 tie 都同等对待。大多数“近边界风险”来自一阶或低阶区域,平滑机制只要围绕这些区域设计,就能覆盖主要不稳定来源。 论文进一步引入 l_infinity, epsilon-thickening,用 gating logit 间隔来判定输入是否靠近边界。相比在原始输入空间里计算到复杂边界的距离,logit 空间中的判定更可实现:如果某个未激活专家的分数距离第 k 个专家分数很近,就把它视为靠近切换边界。
4. 随机过程结论:扰动轨迹几乎先撞上一阶边界
几何分析回答了“哪里占体积”;随机过程分析回答“扰动路径会碰到哪里”。 论文把输入扰动建模为扩散过程。在这个模型下,输入从一个 Top-k cell 内部出发,随着随机扰动演化。作者证明,轨迹最终会在有限时间内撞到某个路由边界;更关键的是,第一次撞到的边界几乎必然是一阶不连续,而不是高阶不连续。 直觉上,这与几何维度一致。一阶边界像两个区域之间的墙,高阶边界像多面墙同时交汇的棱或角。随机路径撞墙很常见,但刚好撞到多面墙交汇处的概率极低。 论文还给出 occupation time bounds,用来界定随机轨迹在不同阶数边界邻域中停留的时间。结论依然指向同一个事实:在小 epsilon 区域内,高阶不连续附近的停留时间随阶数快速衰减。 这些理论结果共同支撑了后面的设计选择:平滑应该是局部的、低阶优先的、围绕 Top-k 阈值附近专家展开,而不是把整个 MoE 改成全局 dense 或全局 soft mixture。
5. SmoothSMoE:只在边界附近软加入专家
基于上述分析,作者提出 SmoothSMoE。它的思想很简单:保留 Top-k 主路由,但在输入位于边界邻域时,让那些“几乎进入 Top-k”的专家以平滑方式参与输出。 具体来说,若某个未激活专家的 logit 与第 k 个专家的 logit 差距小于 epsilon,就认为它处在 l_infinity, epsilon 邻域内。SmoothSMoE 会对这类近阈值专家施加一个平滑 margin,使其以连续方式被纳入计算。这样,输入穿过边界时,输出不会突然跳变,而是平滑过渡。
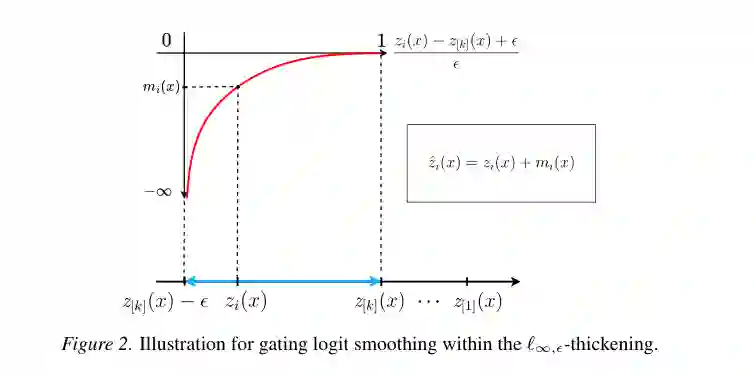
一个关键点是,SmoothSMoE 没有全局改变 Top-k 的稀疏结构。远离边界时,路由仍然保持原样;只有当专家分数接近切换阈值时,才会临时引入额外专家。因此理论上,额外计算只发生在低体积的近边界区域,而不是把所有 token 都变成 dense mixture。 论文还引入 boundary loss 控制平均激活专家数 K。若局部平滑导致额外专家过多,boundary loss 会推动 epsilon 变小;若额外专家不足,则允许更大平滑范围。这样模型可以在连续性和计算预算之间自动平衡。
6. 直观效果:跳变被消除,输出变连续
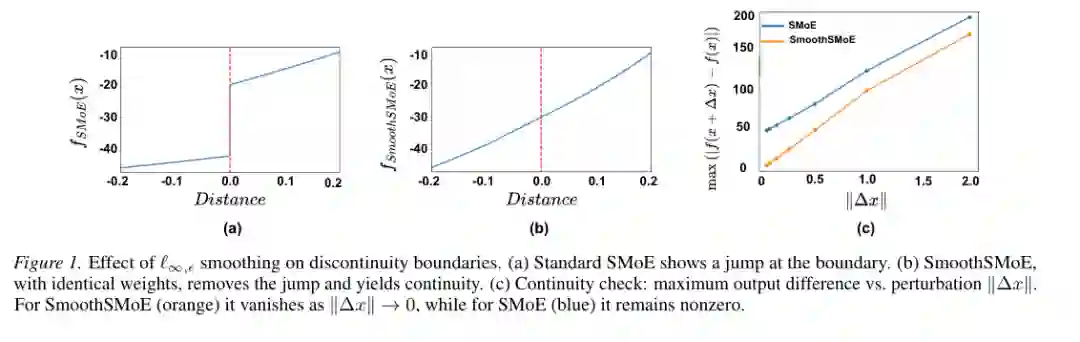
论文用一个小规模可视化实验展示 SmoothSMoE 的作用。标准 SMoE 在穿过不连续边界时,输出曲线出现明显跳变;SmoothSMoE 在使用相同权重的情况下,将这条曲线变成连续曲线。右侧扰动实验也显示,当扰动幅度趋近于 0 时,SmoothSMoE 的输出差异趋近于 0,而标准 SMoE 仍保留非零跳跃。
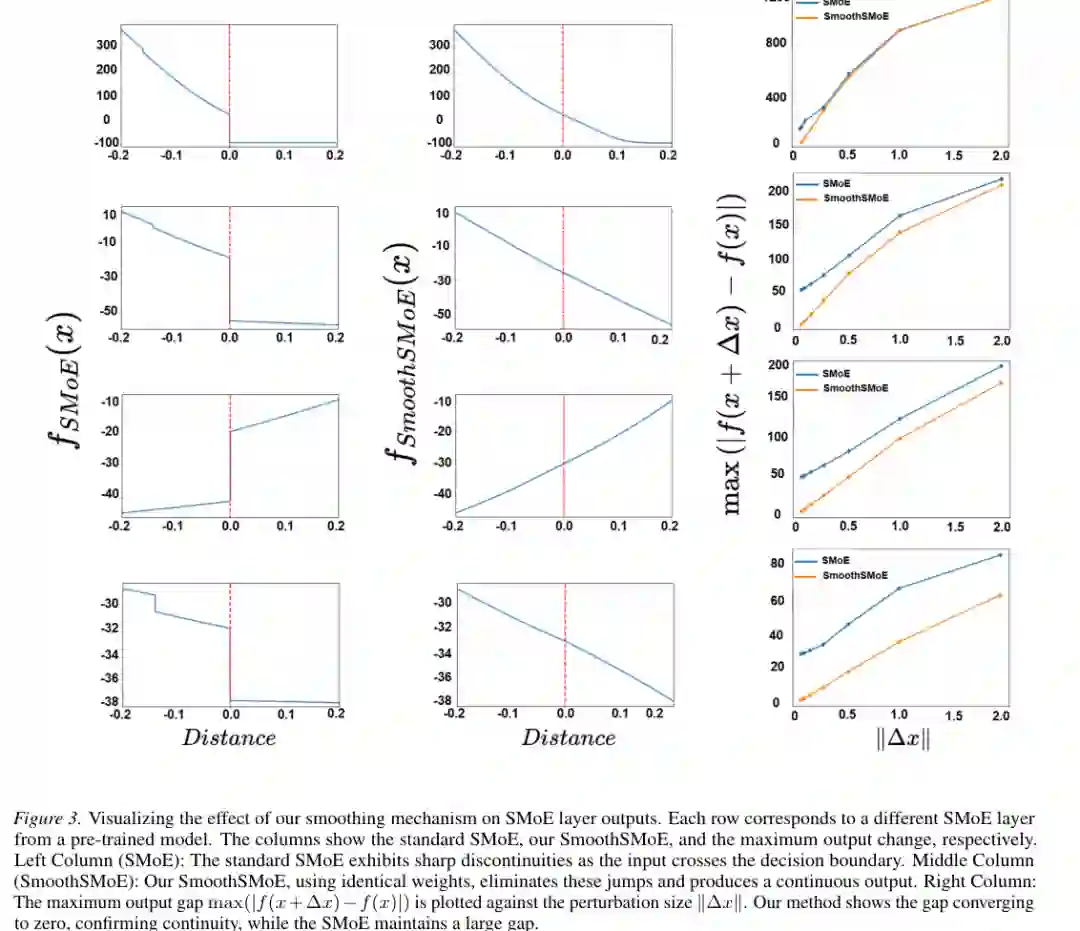
附录中更详细的多层可视化进一步说明,这不是单个层的偶然现象。在多个 SMoE 层中,标准 Top-k 曲线都可能在边界处形成突变;SmoothSMoE 则能把突变替换为平滑过渡,同时降低小扰动下的最大输出差异。
7. 语言建模实验:在干净与扰动数据上都降低困惑度
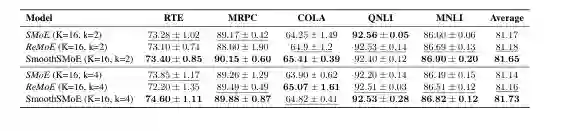
作者首先在 WikiText-103 和 EnWiki-8 上测试语言建模。表 1 显示,在 WikiText-103 上,SmoothSMoE 的验证和测试 PPL 都低于标准 SMoE 和 ReMoE;在 attacked WikiText-103 上,SmoothSMoE 也保持更低 PPL。
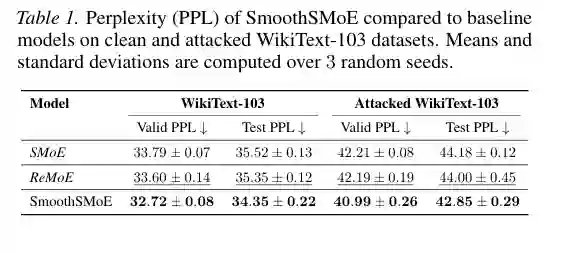
这个结果说明,局部平滑不仅是数学上让函数连续,也能转化为实际训练和鲁棒性收益。对于语言模型,路由边界处的突变可能放大 token 表示的小扰动;SmoothSMoE 通过降低边界敏感性,使模型在标准数据和扰动数据上都更稳。 在 GLUE 任务上,SmoothSMoE 在 k=2 和 k=4 两种设置下都取得最佳平均分。尤其在 MRPC、QNLI 等任务上,平滑路由带来稳定提升。
8. 视觉任务与大规模视觉语言模型
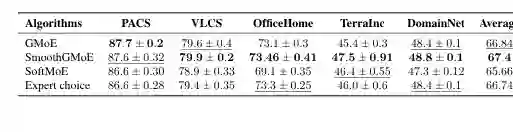
论文也在视觉域泛化任务上验证了 SmoothSMoE。作者将局部平滑加入基于 ViT-S/16 的 GMoE,并在 DomainBed benchmark 上比较 GMoE、SmoothGMoE、SoftMoE 和 Expert Choice 等方法。结果显示,SmoothGMoE 平均准确率最高,在 TerraIncognita 上提升尤其明显。
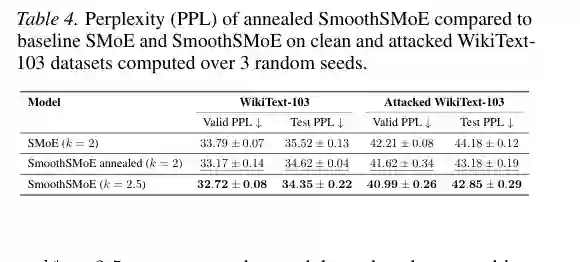
作者还研究了 boundary smoothing 的退火策略:训练早期允许更多近边界专家参与,使优化更平滑;训练后期逐步收回到硬 Top-k,从而消除训练和推理之间的结构差异。表 4 显示,退火版本在 WikiText-103 上能够进一步改善测试 PPL,说明边界平滑也可以作为训练阶段的优化辅助。
在更大规模的视觉语言模型实验中,作者将方法应用到 5.6B 参数的 ViT-based VLM,上采样自预训练 backbone,并在 LLaVA-665K 的 50% 数据上微调。SmoothSMoE 在多个 benchmark 上取得更高平均分,说明该方法不仅适用于小规模可视化或语言建模,也能迁移到更复杂的多模态场景。
9. 这篇论文的意义
这篇论文值得关注的地方,不只是提出了一个 SmoothSMoE 模块,而是把稀疏 MoE 的一个长期存在但常被工程化绕开的现象,变成了可以分析、可以度量、可以针对性修复的问题。 第一,它把 Top-k 不连续性按阶数分类,并证明近边界体积主要由低阶不连续贡献。这让“只在边界附近平滑”有了理论依据。 第二,它用扩散过程分析输入扰动,证明随机轨迹几乎会先撞上一阶边界。这说明一阶边界不是数学上的边角料,而是实际扰动中最可能触发路由不稳定的位置。 第三,SmoothSMoE 没有要求完全重训路由,也没有把模型改成全局 dense mixture,而是在接近阈值的位置软加入少量专家。这种设计更接近现有 SMoE 系统的可插拔增强。 第四,论文同时给出了理论、可视化和多任务实验。对 ICML Spotlight 论文而言,这种“理论解释-机制设计-跨任务验证”的闭环比较完整。
10. 局限与后续方向
论文也指出了一个重要局限:真实模型中的扰动可能并不完全符合随机扩散假设。训练过程中的梯度噪声、数据分布偏移、对抗扰动和表示空间变化都可能具有更强结构性。因此,本文理论更像是一个可分析的基准模型,而不是对所有实际扰动的完整刻画。 另一个值得继续研究的问题是计算预算。SmoothSMoE 虽然理论上只在近边界区域增加专家,但在实际大模型中,不同层、不同 token、不同任务的近边界比例可能差异很大。如何自适应地控制 epsilon、额外专家数和吞吐开销,是部署时需要关注的工程问题。 此外,本文主要围绕 Top-k 路由展开。未来如果 MoE 路由机制进一步多样化,例如分层路由、任务条件路由、检索增强路由或多模态专家路由,那么类似的不连续性分析也需要扩展到更复杂的结构。
11. 小结
本文对稀疏 MoE 的 Top-k 路由不连续性进行了系统分析:几何上,低阶不连续邻域占主导;随机过程中,扰动轨迹几乎首先命中一阶边界;方法上,SmoothSMoE 只在接近路由阈值的位置做局部平滑,以较小额外开销恢复连续性。 从大模型系统角度看,这篇论文提醒我们:稀疏化带来的效率,并不是免费的。Top-k 的硬选择会在表示空间中制造切换边界,而这些边界可能影响训练稳定性、鲁棒性和泛化。SmoothSMoE 的价值在于,它没有否定稀疏 MoE 的核心优势,而是用更细致的理论分析告诉我们,应该在哪里、以多大范围、用什么方式去修补这些边界。