
ICML 2026 | CFPO:用反事实策略优化提升多模态推理的视觉忠实性
论文标题:CFPO: Counterfactual Policy Optimization for Multimodal Reasoning 作者:Zhangyuan Yu、Wanran Sun、Guangjing Yang、Xiaohu Wu、Qicheng Lao 论文链接:https://arxiv.org/abs/2606.23206 会议:ICML 2026

图1:论文首页。CFPO 关注多模态推理中视觉证据被语言先验覆盖的问题,并提出反事实策略优化框架。
1. 研究背景:多模态推理为什么还会“看不见图”
大视觉语言模型在视觉问答、多模态数学推理和复杂指令跟随上已经取得显著进展,但它们在强化学习优化后仍然容易出现一个尴尬问题:回答看似有推理链,实际却没有真正利用图像证据。 论文将这种现象归结为当前 RL 训练范式的目标缺陷。PPO、GRPO、DAPO 等方法主要根据最终答案正确性给奖励,优化器只关心“答对没有”,却无法区分答案是来自真实跨模态理解,还是来自语言先验、数据偏置和偶然相关。结果是,模型可能学会一种投机式推理:在图像证据不足或复杂时,优先调用语言常识或模板化推理。 作者总结了三类典型跨模态因果不一致问题。第一是显著性不足,模型忽略关键视觉线索,转而根据语言先验猜答案。第二是显著性错配,注意力被显眼但无关的视觉区域吸走。第三是显著性惯性,即视觉锚点已经被正确注意到,但模型无法根据假设性问题进行逻辑干预,仍沿用静态视觉事实。 CFPO 的核心问题意识很清楚:多模态 RL 不能只奖励最终答案,还要让模型知道哪些视觉证据对推理是因果必要的。
2. 相关思路:为什么已有反事实方法不够
已有工作也尝试用反事实思想缓解多模态幻觉。推理时方法如 VCD、M3ID、ICD 会构造视觉噪声或误导性指令作为反事实基线,用输出分布差异校准解码。但这类方法通常需要额外前向计算,推理成本高,而且不能真正改变模型参数中的因果偏差。 训练侧方法如 DeFacto、CF-VLM 借助构造好的反事实数据进行对齐,但依赖人工或 AI 生成数据,监督成本较高。PAPO 尝试在 RL 中加入感知约束,通过随机输入遮蔽增强视觉感知,但这种像素级粗粒度干预很难精确定位高层推理真正依赖的细粒度视觉语义。 CFPO 的思路是把反事实干预放进 RL 训练环,并且干预位置不是原始像素,而是 LVLM 语言解码器的多头注意力输出。这样可以直接检验“当关键跨模态注意力被抑制后,模型对当前回答的置信度是否下降”。
3. 方法概览:Counterfactual Policy Optimization
CFPO 的全称是 CounterFactual Policy Optimization。它的目标是在多模态 RL 中显式加入跨模态因果一致性约束,使模型必须把正确回答建立在有效视觉证据上。
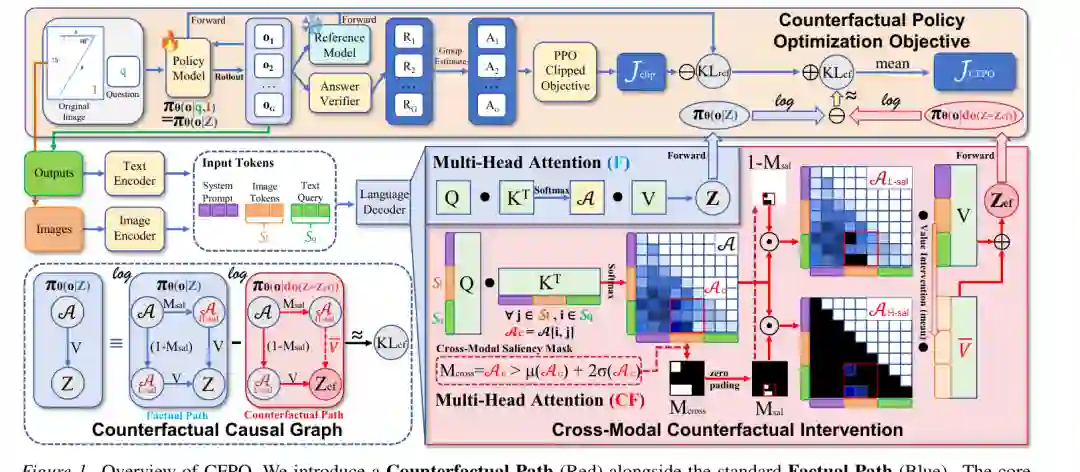
图2:CFPO 总体框架。蓝色路径是事实路径,红色路径是反事实路径;模型在注意力输出层抑制高显著视觉线索,并通过两条路径的预测差异约束策略学习。
语言解码器视角
论文首先从 LVLM 的语言解码器出发建模。输入由图像和文本问题组成,图像经过视觉编码器得到 image tokens,文本经过文本编码器得到 query tokens。二者共同进入语言解码器,在多头注意力中形成注意力矩阵,并产生注意力输出表示。 在 CFPO 中,注意力输出记为 Z。模型的输出概率可以写成依赖 Z 的策略分布。这个记号的意义在于,作者把 Z 视为连接跨模态证据和语言生成的“因果中介变量”:如果对 Z 中关键视觉贡献做干预,输出分布发生明显变化,说明原答案确实依赖视觉证据。
反事实因果图
CFPO 构建了一个简化因果图:多模态输入产生注意力矩阵,注意力矩阵和 value 表示共同形成 Z,Z 再影响生成策略。事实路径使用原始注意力输出 Z;反事实路径则执行 do 干预,得到抑制关键视觉线索后的反事实表示 Zcf。 这个设计的关键在于“动态因果必要性测试”。如果模型真正依赖图像中某个关键证据,那么抑制该证据后,原回答概率应该下降;反之,如果抑制关键视觉线索后模型仍高度自信地输出同一答案,说明它很可能是在依赖语言先验或伪相关。
4. 跨模态反事实干预
跨模态显著性掩码
CFPO 首先从完整注意力矩阵中抽取跨模态注意力子矩阵,即文本 query tokens 对图像 tokens 的注意力区域。这个子矩阵刻画了当前生成步骤中,文本推理对不同视觉 token 的依赖程度。 作者使用统计异常值检测来识别高显著视觉区域。直观地说,如果某些图像 token 的注意力显著高于均值和标准差定义的阈值,它们就被认为是当前推理中的高显著视觉线索。随后 CFPO 构造显著性掩码 Msal,用来在反事实路径中抑制这些区域。
value 层干预
和直接遮蔽像素不同,CFPO 在注意力输出层进行干预。具体来说,事实路径保留原始高显著视觉贡献;反事实路径将对应 value 表示替换或平均化,使模型无法继续使用这些关键视觉线索。 论文比较了几种 value 干预策略,包括 image token average、text token average 和 noise addition。结果表明,用图像 token 的平均表示替换高显著区域效果最好,因为它既能抹去具体语义细节,又能保持整体特征分布相对稳定。相比之下,噪声会引入分布外扰动,文本 token 平均则可能破坏跨模态空间对齐。
5. 反事实策略优化目标
CFPO 的优化目标建立在事实路径与反事实路径的差异之上。作者定义反事实比例,用来衡量当前策略对原始视觉证据的依赖程度。如果事实路径下某回答概率高,而反事实路径中抑制关键视觉线索后概率明显下降,那么这个回答更可能是视觉证据驱动的。 CFPO 将这一差异作为反事实正则项加入 GRPO 或 DAPO。最终目标包含标准 RL 奖励最大化、参考模型 KL 约束、反事实 KL 项,以及可选的熵损失。这样模型不仅要答对,还要使正确答案对关键视觉证据敏感。 论文给出两个版本:CFPOG 表示与 GRPO 集成,CFPOD 表示与 DAPO 集成。重要的是,CFPO 不需要额外奖励模型,也不需要额外监督数据,可以直接作为标准多模态 RL 的训练增强项。
6. 实验设置
训练数据使用 ViRL39K,这是一个包含 38,870 个可验证多模态推理问答对的集合。模型基于 Qwen2.5-VL-3B 进行直接 RL 训练,没有额外 SFT。训练使用 2 张 NVIDIA A800 80G GPU,rollout batch size 为 384,每个 prompt 生成 5 个响应。 评测覆盖两类任务。第一类是真实世界中心推理,包括 C-VQA-Real、MARS-Bench、POPE、TextVQA 和 MMMU-Pro 的视觉子集,用来评估细粒度视觉识别、对象幻觉和真实场景理解。第二类是数学中心推理,包括 Geo3k、We-Math、MMk12、MathVerse 和 LogicVista,用来检验几何、数学、逻辑与视觉证据结合的能力。 对比方法包括标准 GRPO、DAPO,以及感知增强基线 PAPO。指标为 8 次 rollout 的平均准确率。
7. 主要结果:CFPO 稳定提升推理忠实性
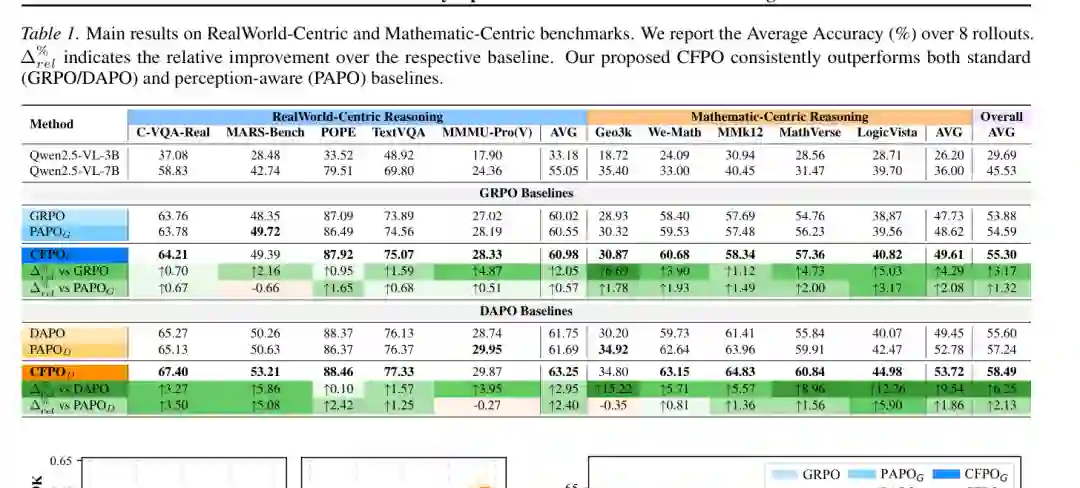
图3:主实验结果。CFPO 在真实世界中心与数学中心基准上均超过 GRPO、DAPO 和 PAPO。 整体结果显示,CFPO 在两类推理任务上都带来稳定增益。相对标准 RL 基线,CFPO 的提升达到 3.17%-6.25%;相对感知增强方法 PAPO,仍有 1.32%-2.13% 的提升。 在 GRPO 分支中,CFPOG 将整体平均准确率从 53.88 提升到 55.30。真实世界中心任务平均从 60.02 提升到 60.98,数学中心任务平均从 47.73 提升到 49.61。数学任务提升更明显,说明反事实视觉证据约束对几何、数学、逻辑类多步推理尤其有帮助。 在 DAPO 分支中,CFPOD 将整体平均准确率从 55.60 提升到 58.49,数学中心任务平均从 49.45 提升到 53.72。尤其在 Geo3k、MathVerse、LogicVista 等任务上,提升幅度较大,表明 CFPO 能缓解模型在长链推理中漂向语言先验的问题。
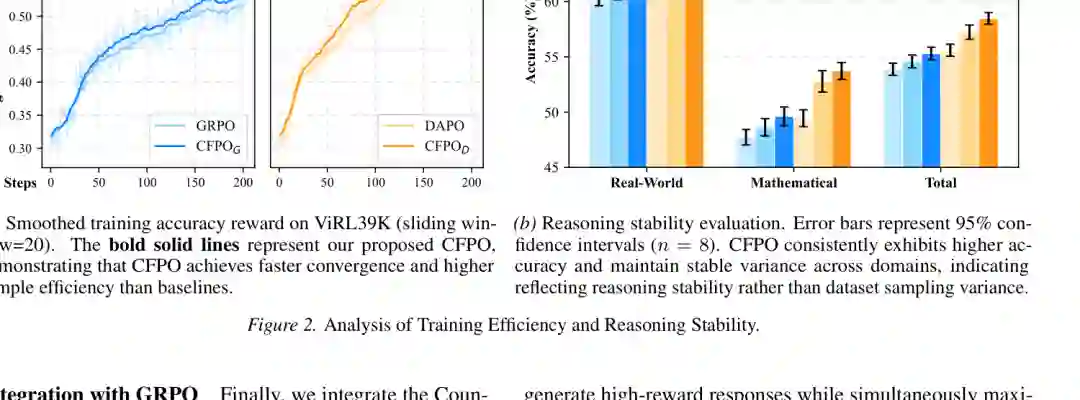
图4:训练效率与推理稳定性。CFPO 相比基线收敛更快,并在不同任务域上表现出更稳定的准确率。 训练曲线显示,CFPO 在 ViRL39K 上获得更快收敛和更高样本效率。稳定性分析中,CFPO 在真实世界、数学和总体设置下均具有更高平均准确率,并保持较低方差。这说明性能提升不是由随机采样波动造成,而是来自更稳健的因果一致性约束。
8. 定性案例:反事实约束如何改变推理链
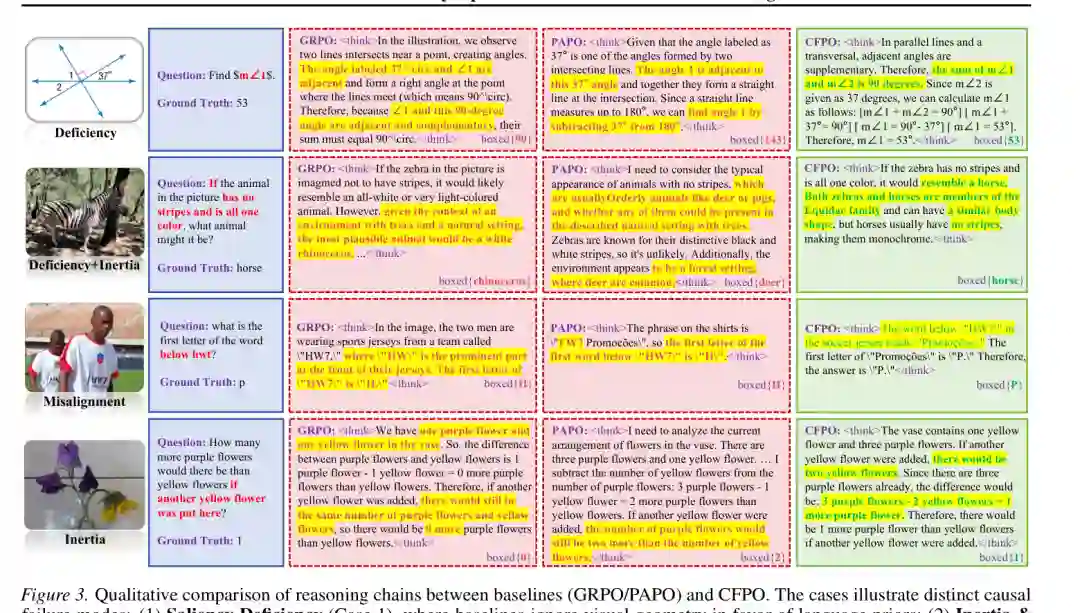
图5:GRPO、PAPO 与 CFPO 的推理链对比。CFPO 能更好地利用几何、物体属性、文字位置和假设干预中的关键视觉证据。 论文展示了四类典型失败模式。第一个几何案例中,基线模型忽视图中的平行线与横截线关系,错误使用语言模板;CFPO 能结合视觉结构得出正确角度。第二个斑马案例中,问题假设“没有条纹且全为一种颜色”,基线被自然场景和常识诱导,猜成白犀牛或鹿,CFPO 则正确保留体型证据并推断为马。 第三个运动员案例中,基线注意到醒目的球衣文字 HW7,却没有读出问题要求的 “below hwt” 中下方文字;CFPO 能定位到球衣下方单词并回答首字母。第四个花朵案例中,基线被当前静态数量锚定,无法正确执行“再加入一朵黄色花”的假设变化;CFPO 能在反事实条件下更新数量关系。 这些案例说明,CFPO 并不是简单提高输出格式或奖励答案,而是改变了模型对视觉证据的依赖方式:当关键视觉线索被反事实抑制后,模型必须让策略分布发生足够变化,从而在训练中学会真正绑定视觉证据与文本推理。
9. 消融实验:哪些设计最关键
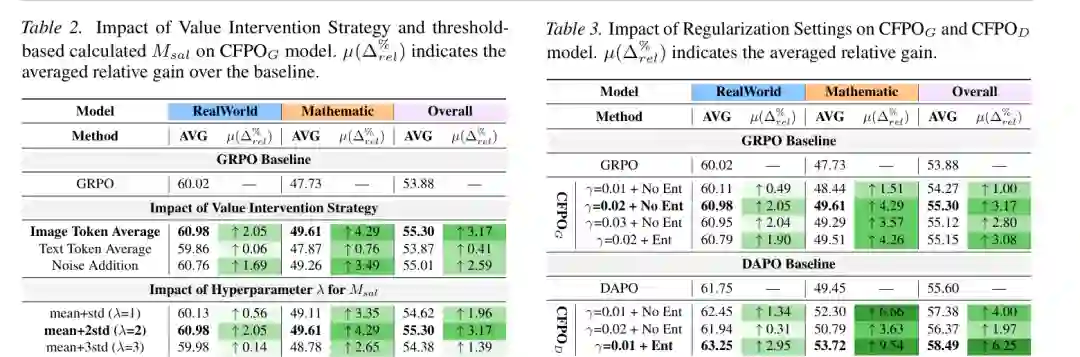
图6:value 干预策略、显著性阈值和正则设置的消融结果。 消融实验显示,value 干预策略中 image token average 效果最好,整体平均达到 55.30。text token average 几乎没有带来整体收益,说明把视觉区域替换成文本平均表示会破坏跨模态空间。noise addition 虽有提升,但不如 image token average 稳定。 显著性阈值方面,mean+2std 是最佳平衡。阈值过低会过度遮蔽视觉背景,损害有效信息;阈值过高又过于保守,无法形成足够明确的反事实路径。 正则设置方面,CFPOG 在 γ=0.02 且不加熵损失时表现最好;CFPOD 则在 γ=0.01 且加入熵损失时表现最佳。论文解释说,DAPO 移除了参考 KL 惩罚,策略更容易受伪相关影响,因此需要较小的反事实强度和熵约束共同稳定训练。
10. 成本与局限
CFPO 的主要代价来自训练计算。论文报告,CFPOG 相比 GRPO 每步时间从 650.20 秒增加到 1001.58 秒,峰值显存从 31.03GB 增加到 40.66GB;CFPOD 相比 DAPO 每步时间从 735.15 秒增加到 1098.71 秒,显存从 36.21GB 增加到 46.20GB。 作者认为,显存增加在 10GB 以内相对可控,吞吐下降主要是工程瓶颈:在 self-attention 内部进行细粒度 latent 级因果干预,会打断 Flash-Attention 等融合 kernel 的连续计算流,导致算子 fallback。未来通过自定义 CUDA kernel 有望显著降低开销。 此外,论文主要在 Qwen2.5-VL-3B 上验证,并在附录扩展到更新架构和更大尺度。未来仍需继续评估 CFPO 在更大模型、更多模态、更多真实机器人或复杂交互场景中的泛化能力。
11. 总结
CFPO 提出了一种面向多模态推理的反事实策略优化框架。它的核心贡献不是再设计一个更强奖励模型,而是在 RL 训练中加入跨模态因果一致性约束:当高显著视觉证据被抑制时,正确回答的概率应当下降。 这种机制让模型不仅追求答案正确,还要让答案对关键视觉证据保持因果敏感。实验表明,CFPO 可以无缝集成到 GRPO 和 DAPO,在真实世界中心与数学中心多模态推理基准上取得稳定提升,并改善训练稳定性和推理链质量。 从更广的角度看,这篇论文给多模态 RL 提供了一个重要方向:仅优化最终答案会放大语言先验和伪相关,而未来的多模态推理训练需要更细粒度地约束“模型为什么答对”。CFPO 用反事实路径把这个问题变成可训练目标,是一条很有启发性的路线。