
ICML 2026 | 边界嵌入塑形:用自适应对比学习破解图结构纠缠
论文标题:Boundary Embedding Shaping with Adaptive Contrastive Learning for Graph Structural Disentanglement 作者:Jiaqing Chen、Zidu Yin、Yichao Cai、Yuhang Liu、Zhen Zhang、Dong Gong、Javen Qinfeng Shi 论文链接:https://arxiv.org/abs/2606.20283 代码链接:https://github.com/codest/BES
这篇 ICML 2026 论文关注图神经网络中一个长期存在但经常被“平均化处理”的问题:图结构纠缠。GNN 通过邻域聚合学习节点表示,但真实图的邻域往往混杂、异质且带有噪声。语义无关的邻居会把错误结构信号带入节点嵌入,使不同类别在嵌入空间中相互靠近,最终模糊分类边界。 作者的关键判断是:结构纠缠并不是均匀地伤害所有节点,真正的瓶颈集中在决策边界附近。也就是说,远离边界的节点即便受到一些噪声干扰,分类仍然比较稳定;而边界节点本来就处于类别交界处,少量伪相关结构信号就可能改变预测。基于这一观察,论文提出 Boundary Embedding Shaping,简称 BES:它不是重新设计一个庞大的 GNN,而是作为插件模块接在已有 GNN 编码器之后,专门对边界节点进行自适应对比学习式的嵌入塑形。

图1:论文首页与摘要信息。
1. 研究背景:图结构纠缠为何难处理
图数据天然不同于图像或文本等规则结构数据。一个节点的表示不仅由自身特征决定,还受到邻居节点、边类型、局部拓扑模式以及消息传递路径的影响。GNN 的优势在于聚合邻域信息,问题也恰恰来自这里:如果邻域中混入大量语义无关甚至类别相反的节点,聚合操作就会把这些噪声一起写进节点表示。 论文将这种现象称为 graph structural entanglement,即图结构纠缠。直观地说,节点嵌入中混合了两类信号:一类是决定类别的稳定结构语义,另一类是由局部邻域变化带来的非本质结构噪声。传统 GCN、GAT、GraphSAGE 等方法通常通过统一的消息传递参数处理所有节点,很难区分这两类信号;一些鲁棒 GNN 或对比学习方法虽然能改善整体表示,但往往没有明确回答“应该重点修正哪些节点”。 论文给出的例子来自 WikiCS 数据集。与 Internet protocols 和 Computer security 相关的文章在主题上天然交叉:协议保障通信,安全保障保密,两类文章常常共享术语和连接关系。GNN 在这种场景下容易把边界节点拉向错误簇,导致分类混淆。
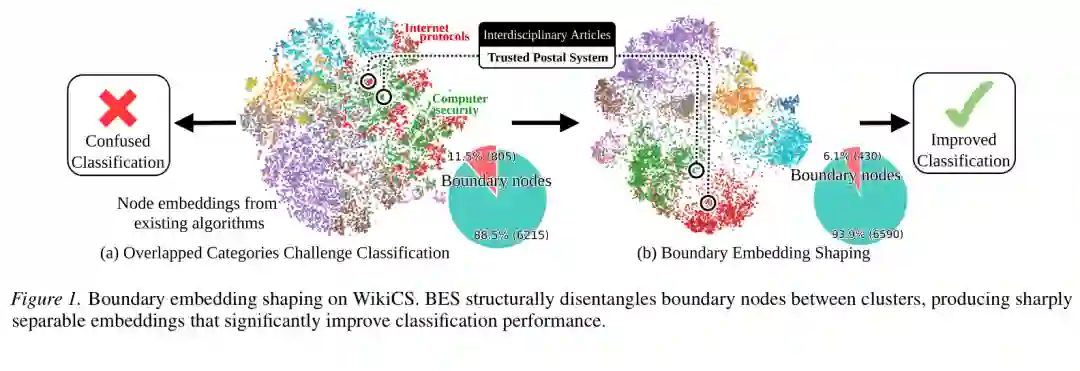
图2:结构纠缠会使不同类别在嵌入空间中重叠;BES 重点塑形边界节点,使类别簇更加清晰可分。
2. 核心思想:把主要修正预算放在边界节点上
BES 的出发点很明确:如果一个节点已经远离类别边界,对它做大幅修正收益有限,甚至可能扰动原有稳定表示;如果一个节点位于边界区域,并且其近邻来自多个类别,那么它更可能受到结构噪声污染,应该优先被修正。 因此,BES 将问题拆成三步。第一步,用已有 GNN 编码器得到初始节点嵌入。第二步,在嵌入空间中定位类别簇之间的边界区域,并计算边界节点的结构变异程度。第三步,只对这些高风险节点进行对比学习式的嵌入塑形,让同类节点靠近、异类节点远离,同时控制参数更新幅度,避免对全局表示造成不必要扰动。 这种设计的价值在于“有选择地去噪”。它并不假设所有节点都同样脆弱,而是把学习资源集中在最容易被噪声影响、也最可能带来性能提升的区域。对公众号读者来说,可以把它理解为:BES 不是给整张图做一次粗粒度清洗,而是在分类边界附近做精细化修边。
3. 理论建模:把节点信息拆成不变因素与变化因素
为了形式化结构纠缠,论文引入潜变量视角。作者将潜在空间分成两个部分:不变潜变量和变化潜变量。 不变潜变量表示与类别相关、在不同局部结构下保持稳定的信息,例如某类节点的代表性语义或核心结构属性。变化潜变量则表示随局部邻域变化而波动的信息,例如临时连接、跨类别邻居、局部拓扑噪声等。这部分信号可能和类别无关,却会在消息传递中污染表示。 在这个框架下,结构解耦的目标不是简单压缩表示,而是恢复与类别相关的不变因素,并抑制由邻域变化带来的伪相关因素。论文进一步从可识别性角度分析:如果对比学习中的相似性函数能够正确约束同类与异类关系,那么模型可以从观测特征中更稳定地分离出不变结构因素。 这部分理论为后续方法提供了依据:BES 选择边界节点并不是经验技巧,而是因为这些节点包含更丰富的结构变化观测,也更能暴露不变因素与噪声因素之间的纠缠。
4. 方法框架:Boundary Embedding Shaping
BES 是一个面向已有 GNN 的插件模块。它不替代原始图编码器,而是在多个 GNN 编码器产生的初始嵌入基础上,增加边界嵌入塑形层。整体框架包括三个关键组件:成对对比目标、中心近似目标、自适应更新机制。
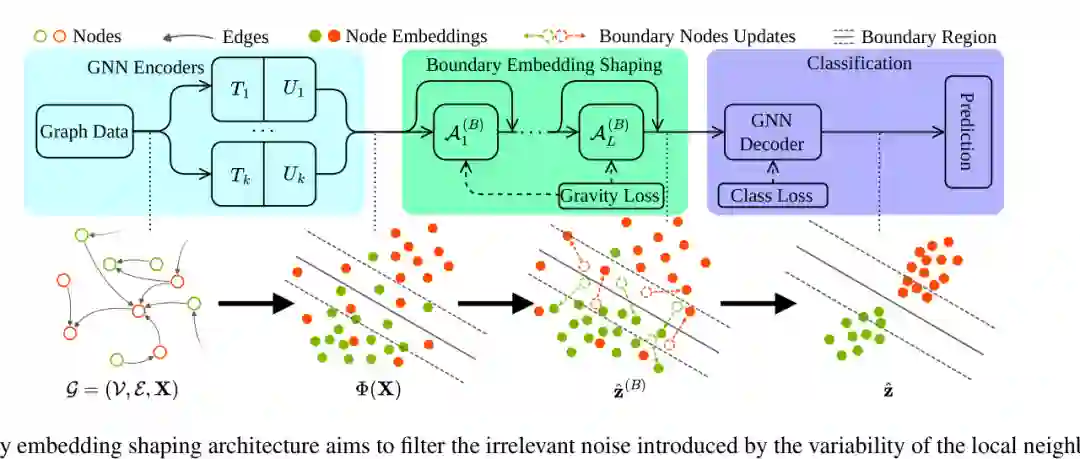
图3:BES 框架由 GNN 编码器、边界嵌入塑形模块和下游分类器组成,通过重力损失过滤局部邻域变化引入的无关噪声。
4.1 边界节点识别
BES 首先在嵌入空间中粗略确定类别簇之间的边界区域。论文采用一种基于间隔的 slab 区域定义:对两个类别簇,用类中心之间的分离方向和协方差信息刻画边界带。落在该区域内的节点,被视为候选边界节点。 随后,模型计算节点的结构变异分数。简化理解就是:在嵌入空间近邻中,如果一个节点周围有较多不同类别的节点,它的局部结构就更不稳定,也更可能处在纠缠区域。论文以阈值方式筛选出高结构变异节点作为真正的边界节点。 这里有两个细节值得注意。第一,BES 使用的是嵌入空间近邻,而不是原始图上的直接邻居,因为前者更直接反映当前表示对分类目标的影响。第二,边界节点识别只使用训练节点标签,避免把验证集或测试集标签泄露到训练过程。
4.2 成对对比目标与重力损失
对选出的边界节点,BES 构造一种类似“重力”的对比目标。对同类样本,模型希望边界节点向正样本靠近;对异类样本,模型希望边界节点远离负样本。论文用平方欧氏距离定义正向相似度和负向相似度,从而让边界嵌入在局部空间中变得更清晰。 这个目标服务于两个目的:一是将被结构噪声拉混的边界节点重新推回正确语义区域;二是让不同类别之间的决策边界更锋利。与普通监督对比学习相比,BES 的对比约束不是平均作用于所有节点,而是集中作用于边界区域,这也是它区别于常规图对比学习的关键。
4.3 中心近似:降低成对计算复杂度
直接计算所有边界节点与同类、异类节点之间的成对相似度,复杂度很高,不适合大规模图。为此,论文提出中心化近似:用类别中心来近似同类分布,把成对相似度聚合转化为节点到类中心的距离优化。 论文指出,在一定条件下,这种中心近似与原始成对目标在梯度上等价或高度一致。它既保留了结构解耦所需的优化方向,又显著降低了计算开销。这一点对实际使用很重要,因为图学习任务常常面对成千上万甚至更大规模的节点和边。
4.4 自适应更新:只在必要时调整参数
边界塑形不能简单地“越强越好”。如果更新过大,模型可能破坏已有 GNN 编码器学到的稳定表示;如果更新过小,又无法有效清除边界噪声。BES 因此设计了自适应学习机制,根据边界节点的状态控制参数更新,让模型在增强边界可分性和保持整体稳定之间取得平衡。 论文强调,BES 的目标是以最小参数扰动实现最大边界收益。这也是它适合作为插件模块的原因:研究者可以把 BES 接到 GCN、GAT、GraphSAGE 等不同编码器之后,而不必完全推倒原有模型结构。
5. 实验设置:覆盖同质图、异质图、异配图和 OGB 图
论文在多个类型的数据集上评估 BES。经典同质图包括 Cora、CiteSeer、Pubmed、WikiCS;异质或异配图包括 Chameleon、Cornell、Texas、Roman-empire;大规模工业图则包括 ogbn-arxiv 和 ogbl-collab。 对比方法覆盖传统 GNN、异配图方法、结构解耦方法和图对比学习方法,包括 GCN、GAT、GraphSAGE、GATv2、H2GCN、SGNN、MPNN 系列、NodeImport 系列、GraphECL、MotifRGC、IGCL 等。评价任务包括节点分类和链路预测,非 OGB 数据集采用随机 60%/20%/20% 的训练、验证、测试划分,结果取 5 次运行平均。
6. 主要结果:BES 在边界判别上带来稳定增益
主结果显示,BES 在多个同质图数据集上取得最优或接近最优表现。尤其在 WikiCS 上,BES 对 GCN 的节点分类平均提升达到 3.3%,最高提升达到 5.0%。在链路预测任务中,BES 也表现出优势,说明边界结构噪声不仅影响节点级分类,也会通过节点表示传递到边级预测。
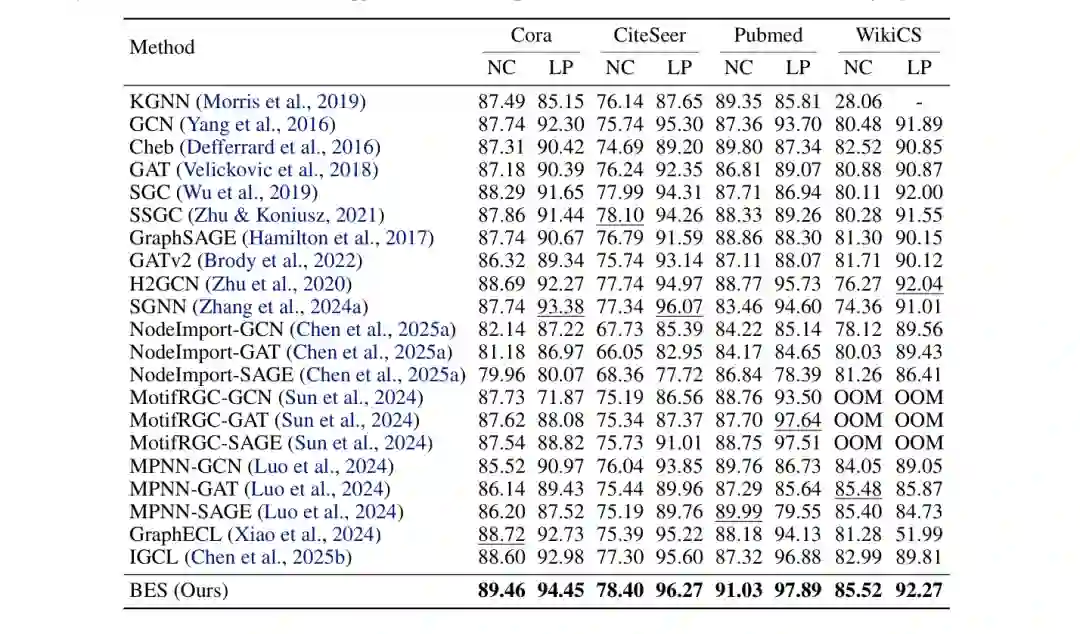
图4:节点分类和链路预测主结果。BES 在 Cora、CiteSeer、Pubmed、WikiCS 等数据集上整体表现领先。 从表格可以看到,BES 在 Cora 上节点分类达到 89.46,链路预测达到 94.45;在 CiteSeer 上分别达到 78.40 和 96.27;在 Pubmed 上分别达到 91.03 和 97.89;在 WikiCS 上分别达到 85.52 和 92.27。相比一些强基线,BES 的优势并不只体现在单一数据集,而是跨数据集、跨任务较为一致。 论文对这一结果的解释是:传统 GNN 将任务相关信号与结构噪声混合进同一套参数和消息传递流程,而 BES 把初始语义编码与边界噪声过滤分开处理。GNN 编码器负责提取基础表示,BES 负责在边界区域做针对性解耦,这种分工让模型更容易获得清晰决策边界。
7. 可视化分析:边界节点被推离混淆区域
论文进一步通过可视化展示 BES 的塑形过程。Figure 3 中,BES 首先定位特征和结构相似但类别不同的边界节点,然后通过注意力层更新嵌入,使原本混杂的节点在嵌入空间中逐步分离。可视化还显示,随着 BES 注意力层数增加,初始纠缠节点的分类和链路预测表现都有提升,但收益主要集中在早期塑形阶段,后续层数的边际收益变小。
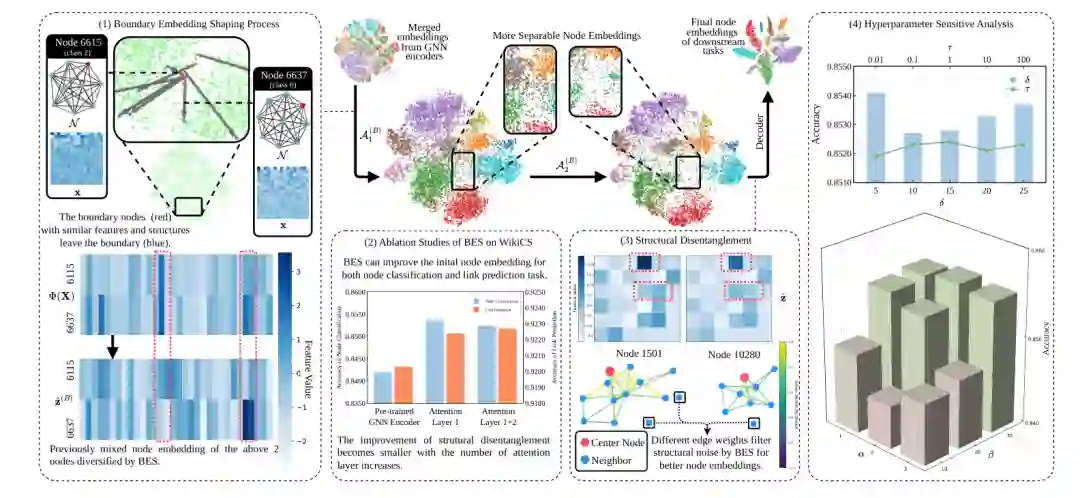
图5:边界嵌入塑形分析。BES 使边界节点离开混淆区域,并通过不同边权过滤结构噪声,得到更可分的最终嵌入。 这一分析支持了论文的核心假设:如果结构纠缠的主要破坏发生在边界附近,那么只要能够识别这些节点并对其进行精细塑形,就可以显著提升整体分类性能,而不必对所有节点做同等强度的表示调整。
8. 与相关工作的区别
与经典 GNN 相比,BES 并不是改造消息传递主干,而是补充一个边界后处理式的塑形模块。GCN、GAT 等模型擅长聚合邻域信息,但在噪声邻域和异配结构下容易过平滑或过度混合;BES 则关注如何在已有表示基础上过滤边界噪声。 与鲁棒图学习或图对比学习方法相比,BES 的差异在于边界选择机制。许多方法试图对全局表示进行统一增强,或者通过原型、子图、增强视图构造对比目标;BES 则明确提出“边界区域是结构纠缠的关键瓶颈”,并围绕边界节点设计对比目标和自适应更新。 与结构解耦方法相比,BES 的优势是把理论分解、不变因素识别和可部署插件结合起来。它既讨论了不变潜变量与变化潜变量,也给出了可在不同 GNN 编码器之后使用的实现路径。
9. 价值与启发
这篇论文的第一点价值,是把图结构纠缠从一个全局鲁棒性问题,重新定位为一个边界敏感问题。它提醒我们:模型错误并不总是均匀分布,很多性能瓶颈集中在少量高风险样本上。对这些样本进行有针对性的表示修正,可能比盲目增加模型复杂度更有效。 第二点价值,是把图对比学习从“构造全局表示增强”推进到“服务于决策边界塑形”。BES 的对比目标不是为了泛化地拉近所有同类节点,而是为了让边界附近的类别分离更稳定,这使得对比学习目标和下游分类目标更加一致。 第三点价值,是插件化设计。很多图学习系统已经有成熟的编码器和训练管线,如果一个方法必须完全替换主干模型,落地成本会很高。BES 作为后接模块,可以与多种 GNN 编码器结合,这增强了它的实用性。
10. 局限与未来方向
论文也留下了一些值得进一步探索的问题。首先,BES 需要训练标签来识别边界节点,在低标签、弱监督或开放集场景下,如何可靠估计边界区域仍然是挑战。作者在结论中也提到,将 BES 扩展到少标签和自监督设置是有前景的方向。 其次,边界区域的定义依赖嵌入空间质量。如果初始 GNN 编码器已经严重失真,边界估计可能受到影响。未来可以考虑把边界发现和嵌入塑形做成更紧密的联合优化,或者引入不确定性估计来提高边界节点选择的鲁棒性。 最后,BES 主要面向节点分类和链路预测任务。对于图级分类、动态图、时序图或大规模异构知识图谱,边界节点的定义和结构噪声来源可能更复杂,如何迁移这一思想仍有扩展空间。
11. 总结
Boundary Embedding Shaping with Adaptive Contrastive Learning for Graph Structural Disentanglement 提出了一种针对图结构纠缠的边界塑形方法。它的核心观点是:GNN 表示中的结构噪声最容易在决策边界处造成伤害,因此应优先识别并修正边界节点。 BES 通过边界节点挖掘、重力式对比学习、中心近似和自适应更新,在不大幅扰动原始模型参数的前提下改善节点嵌入可分性。实验表明,BES 在节点分类和链路预测上均取得稳定提升,尤其在 WikiCS 等存在明显类别重叠的数据集上效果突出。 整体来看,这篇论文不仅给出了一个有效的 GNN 插件模块,也提供了一个重要视角:在复杂图学习中,解决噪声问题不一定要从全局入手,抓住决策边界附近的关键样本,往往能带来更高效、更稳定的结构解耦。

