随着多模态信息的飞速增长,视觉文档检索 (Visual Document Retrieval, VDR) 已成为弥合非结构化视觉丰富数据与精确信息获取之间鸿沟的关键前沿领域。与传统的自然图像检索不同,视觉文档具有由高密度文本内容、复杂的版式布局以及细粒度的语义依赖所定义的独特特征。
本文首次对 VDR 领域进行了全面的综述,特别聚焦于多模态大语言模型 (MLLM) 时代的视角。我们首先考察了当前的基准测试格局,随后深入探讨了方法论的演进,将现有方法归纳为三个主要方面:多模态嵌入模型、多模态重排序模型,以及面向复杂文档智能的检索增强生成 (RAG) 与智能体 (Agentic) 系统的集成。最后,我们识别了当前持续存在的挑战并概述了具有前景的未来研究方向,旨在为未来的多模态文档智能研究提供清晰的路线图。

1 引言 (Introduction)
多模态检索旨在利用跨越文本与视觉等多种模态的查询,从大规模集合中检索相关的多模态信息。该任务已成为现代信息检索的基石 (Mei et al., 2025; Zheng et al., 2025a)。从历史上看,该领域的研究主要集中在自然图像检索,针对照片和网络图像数据集,其主要目标是匹配物体、场景或整体视觉概念 (Wu et al., 2024a; Arslan et al., 2024)。然而,学术界和工业界都开始将注意力转向一种截然不同且无处不在的数据类型:视觉文档。这些文档涵盖了从扫描版 PDF、商业报告到发票和学术论文的广泛范畴,其特点是文本内容、复杂布局与图形元素之间的深度交织 (Tang et al., 2023; Li et al., 2024d)。 向视觉文档检索 (Visual Document Retrieval, VDR) 的转向是由视觉文档与自然图像之间的三个根本区别驱动的(如图 1 所示): * ❶ 信息模态与密度:不同于通过整体场景传达语义的自然图像,视觉文档是混合实体,其含义由丰富的文本信息和结构化的空间布局共同决定。其信息本质上具有高密度、层次化和多模态的特征。 * ❷ 语义粒度:自然图像检索通常针对高层概念(如“一只坐在沙发上的猫”),而 VDR 则要求更细粒度的理解。用户可能会查询嵌入在表格中的特定事实、段落中的特定句子,或取决于其在文档级位置的信息(如“论文的方法论部分”)。 * ❸ 用户意图与任务复杂度:VDR 通常面向精确的信息寻求、问答及基于证据的推理,而非概念性或审美性的匹配。
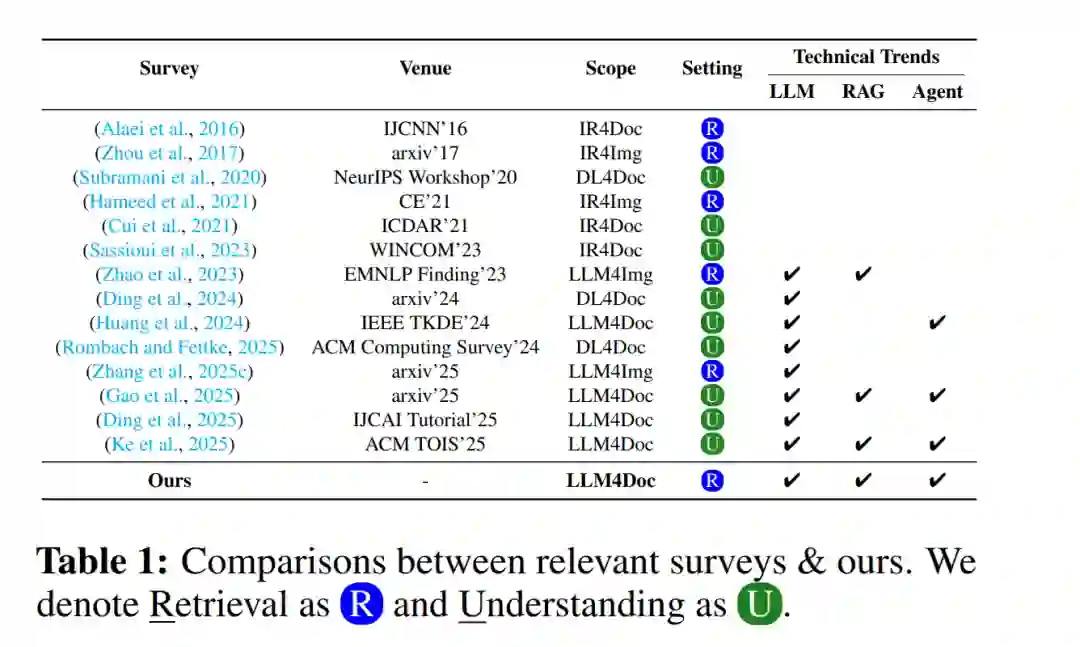
此外,随着多模态大语言模型 (MLLMs) 通用能力的提升 (Song et al., 2025; Yan et al., 2025b,a),VDR 领域正日益关注两者的集成。这包括开发基于 MLLM 的嵌入 (Embedding) 和重排序 (Reranker) 模型以增强语义匹配 (Tao et al., 2024; Zhang et al., 2024b; Wang et al., 2025d)。除此之外,目前也在积极探索在更复杂的框架中利用这些模型,例如检索增强生成 (RAG) 流水线 (Gao et al., 2023; Cheng et al., 2025; Gan et al., 2025a) 和智能体 (Agentic) 系统 (Singh et al., 2025),以应对复杂的文档智能场景。 研究范围 (Scope)。尽管已有一些综述涉及相关领域(如表 1 所示),但在大模型 (LLM) 时代,针对 VDR 的专门且全面的分析仍然缺失。以往的综述大多集中在传统信息检索 (Alaei et al., 2016)、用于文档理解的通用深度学习 (Subramani et al., 2020; Sassioui et al., 2023; Ding et al., 2024),或自然图像检索 (Zhou et al., 2017; Hameed et al., 2021)。即便最近一些关注 MLLM 兴起的综述也延续了这一趋势,侧重于通用文档理解 (Huang et al., 2024; Rombach and Fettke, 2025) 或将 MLLM 应用于自然图像检索 (Zhao et al., 2023; Zhang et al., 2025c)。据我们所知,目前尚无现有工作从以检索为中心的方法论视角,系统性地概述 LLM 时代的 VDR 版图,特别是涵盖新兴的 RAG 和基于智能体的范式。本综述旨在弥合这一关键空白,首次对 VDR 进行全面论述,将基础技术与 (M)LLM 驱动的最新突破进行整合。 论文结构 (Structure)。我们首先从基准测试 (Benchmark) 的视角出发,通过考察任务定义、基础设置以及数据集特征(如多语言支持和对推理密集型查询日益增长的重视)来系统地组织该领域。随后,我们转向以方法论为中心的分析,将现有方法归纳为三类主要范式: * ❶ 作为检索基础的嵌入模型; * ❷ 旨在优化初始检索结果的重排序模型; * ❸ 日益显要的 RAG 流水线与智能体系统。
最后,我们通过讨论挑战并概述未来前沿进行总结,旨在为多模态文档智能社区提供有价值的见解并激发后续研究。