强化学习(Reinforcement Learning, RL)在游戏、机器人、在线广告、公共健康及自然语言处理等多个领域的决策任务中取得了卓越成就。然而,尽管进展显著,RL 研究与实际场景部署之间仍存在巨大鸿沟。该鸿沟主要源于两大挑战:其一,受限于实际约束,智能体往往难以在目标环境中进行充分交互;其二,目标环境常发生动态演变(例如,科技进步会改变医疗服务的交付模式),迫使 RL 系统必须进行重新设计与部署。要应对上述挑战并弥合基础研究与应用之间的断层,亟需一套能够直接指导现实环境下 RL 系统设计、实施及持续优化的理论与方法论。 本文将 RL 的实际应用过程解构为三个核心环节:(i) 部署期间的在线学习与优化;(ii) 部署后期或部署间期的离线分析;(iii) 旨在实现系统持续改进的“部署-重部署”迭代循环。以此框架为基础,本文对统计强化学习(Statistical RL)的最新进展进行了叙述性综述,重点涵盖了提升部署间期推断的数据效用、增强部署内在线学习的样本效率,以及优化持续改进的序贯部署设计等方法。此外,本文还提出了若干应用驱动型(Use-inspired)的统计 RL 未来研究方向,旨在推动强化学习在实际应用中产生深远影响。 关键词: 强化学习;自适应实验;自适应干预;在线学习;统计推断;序贯部署
1. 引言
近年来,强化学习(Reinforcement Learning, RL)因其在游戏、自动驾驶和机器人等领域展现出的超越人类或尖端的性能表现,受到了学术界与工业界的广泛关注 [Mnih et al., 2015, Silver et al., 2017, Wurman et al., 2022, Tang et al., 2025, Kaufmann et al., 2023]。这些现实世界成功案例背后的核心因素之一,是深度学习技术的普及,使得从大数据中进行灵活学习成为可能。深度强化学习取得成功的应用场景通常具备以下共同特征:(1) RL 算法能够与目标环境或高保真模拟器进行大规模交互;(2) 环境的关键变量和动态特性变化极小,因此在未来的部署中,通常不需要或仅需极少量的在线 RL 重学习及算法重新设计。 例如,最近一个备受瞩目的现实世界成功案例是利用深度 RL 在《跑车浪漫旅》(Gran Turismo)中击败人类顶级赛车手 [Wurman et al., 2022]。在该研究中,作者完全在模拟器中通过离线方式训练深度 RL 智能体——采用基于种群的训练(Population-based training)而非纯粹的自我博弈,以增强对多样化对手行为的鲁棒性——并随后将学到的策略作为固定控制器进行部署,无需在线学习或算法更新。这一成功部分归功于高保真模拟器的可用性,它允许智能体与目标环境进行密集交互和大规模探索,而无需承担现实世界中如赛车碰撞等风险。此外,尽管对手行为等外生因素可能随比赛而异,但决策问题的核心组成部分(如状态表示、动作空间、奖励定义和支配动力学)在不同部署之间并未发生实质性变化。因此,训练后的策略无需持续重学习或算法修正即可保持有效。 当上述两个特征不适用时,RL 在现实世界中的应用将面临严峻挑战 [Dulac-Arnold et al., 2021a]。通过文献综述我们发现,在 RL 算法与人类交互的场景中,情况尤其如此。这主要受两大挑战驱动:(1) 无法与目标环境或高保真模拟器进行充分交互以获取海量数据;(2) 环境存在显著变化,要求 RL 算法在下次部署期间重新优化决策策略,和/或更新算法以备后续使用。
一个典型的例子是 RL 算法与人类的交互:虽然在某些领域(如临床试验中的数字干预)取得了一定的现实成功,但仍需大量的研发投入,即利用 RL 实现**即时自适应干预(Just-in-Time Adaptive Interventions, JITAIs)**的个性化 [Gazi et al., 2025a]。JITAIs 在日常生活中做出序列决策以支持个人健康。RL 作为一种在线学习和优化方法,在 JITAIs 个性化方面备受青睐。算法可根据从个体处感测和调查的状态信息(如心率),选择干预选项(如是否向手机发送推送通知)。随后,RL 算法观察个体的反应,并利用这些数据进行在线学习,以优化未来的决策。尽管 RL 在近期的数字干预临床试验中展现了前景 [Aguilera et al., 2024, Lee et al., 2025 等],但仍存在限制其进一步转化的挑战。对应前述挑战 (1) 和 (2),每个个体和每次部署均具有差异性,因此即使存在大量历史数据,新旧部署之间的个体匹配度可能依然较低。此外,社会和数字健康技术在短短几年内会发生剧变,导致动作、奖励或状态变量之间的关系以及变量本身发生改变 [Abernethy et al., 2022]。在线学习虽有助于应对这些失配,但探索受限于与个体的交互次数——不当的干预交付可能导致个体完全脱离(如卸载 JITAI 应用)[Nahum-Shani et al., 2018]。
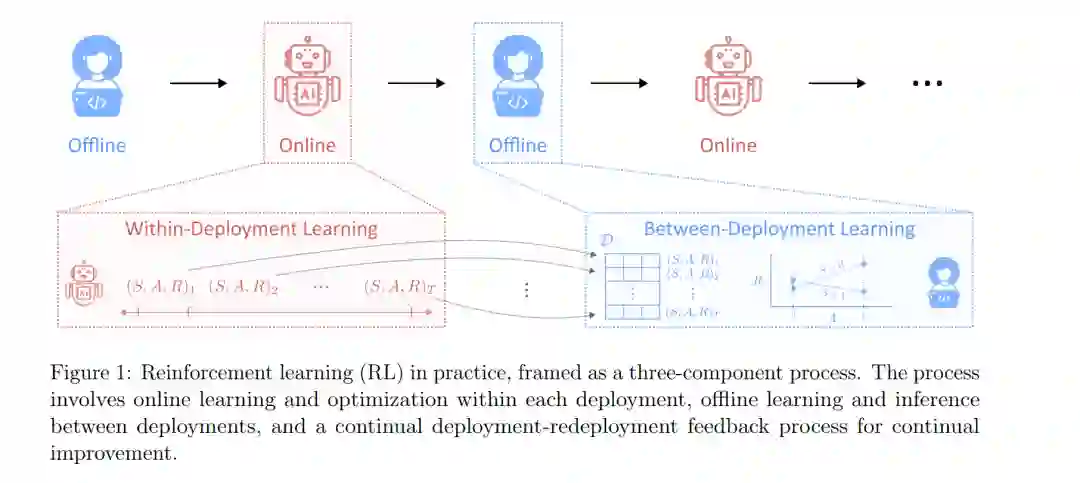
为了使 RL 在上述现实应用中产生重大影响,必须解决挑战 (1) 和 (2)。图 1 提供了一个在现实系统中实施 RL 的前瞻性框架,这是一个包含三个组件的过程:部署期间的在线自主学习与优化、部署间期的离线学习与统计推断,以及在系统生命周期内实现持续改进的部署-重部署循环。这种持续的迭代过程与“离线到在线强化学习”(Offline-to-Online RL)相关 [Guo et al., 2024a],即通过在线 RL 微调离线学到的策略;但本文框架更为宽泛,不仅包含离线到在线的转换(即为下次部署提供“热启动”),还包含在线到离线的知识迁移(即从每次部署中提炼可推广的知识),以及“离线-在线-离线...”的持续改进过程。统计方法对于增强从离线到在线过渡时的样本效率,以及确保在线到离线过渡时序列随机化数据的科学效用至关重要。
本文旨在对强化学习的进展进行综述(即叙述性评论),重点关注与未来现实应用机会最相关的领域。虽然已存在多篇关于 RL [Kaelbling et al., 1996a] 或特定子领域(如深度 RL)的综述,且近期文献也涵盖了离线 RL [Levine et al., 2020] 或探索与在线 RL [Ladosz et al., 2022],但据我们所知,尚无综述重点探讨持续优化现实系统所需的“离线-在线-再离线”循环过程。因此,本文的综述章节依图 1 所示框架组织:部署内(在线自主)学习与优化、部署间(离线)学习与优化,以及持续改进。我们将始终强调应对挑战 (1) 和 (2) 的潜在大方向。在进入综述章节前,我们在第 2 节介绍基本概念和符号,在第 3 节展示突出图 1 流程的现实应用案例。需要说明的是,本文并非系统性综述(Systematic Review),而是一篇概论(Survey),我们的文献筛选标准包括:与未来机会的相关性、对前述两大挑战的应对能力,以及对应用驱动型(而非纯理论驱动)统计方法论的关注。