随着大语言模型(LLMs)的持续演进,仅依靠人类监督来提升模型性能的成本日益高昂,且在可扩展性方面存在局限。当模型在特定领域接近人类水平时,人类反馈可能无法再为进一步的提升提供足够的信息增益。与此同时,模型自主决策和执行复杂任务能力的增强,使得模型开发流程中各个组件的逐步自动化成为可能。在挑战与机遇的共同驱动下,“自我改进”(Self-improvement)引起了学术界日益增长的关注,即模型自主生成数据、评估输出并迭代优化自身能力。
本文从系统级视角审视了具备自我改进能力的语言模型,并提出了一套整合现有技术的统一框架。我们将自我改进系统概念化为一个闭环生命周期,由四个紧密耦合的过程组成:数据获取、数据筛选、模型优化和推理细化,并辅以一个自主评估层。在该框架中,模型自身在驱动各个阶段中发挥着核心作用:收集或生成数据、筛选信息信号、更新参数以及细化输出;同时,自主评估层持续监控进展并引导跨阶段的改进循环。基于这一生命周期视角,我们从技术角度系统地评述并分析了各组件的代表性方法。此外,我们进一步讨论了当前的局限性,并对通往完全自我改进 LLM 的未来研究方向进行了展望。

1 引言 (Introduction)
通过扩展模型规模、训练数据和计算量,大语言模型(LLMs)已实现快速且持续的性能增益(Brown et al., 2020; Ouyang et al., 2022; Hoffmann et al., 2022; OpenAI et al., 2024)。支撑这一进展的普遍假设是:更大规模、更高质量的数据集,特别是专家标注的人类监督,是催生更强模型的关键。在实践中,诸如 RLHF(Ouyang et al., 2022)等方法高度依赖精心策划的高质量监督信号,以对预训练模型进行对齐和细化。 然而,随着模型的不断演进,主要依靠人类监督来改进模型的范式暴露出了几项结构性局限: 1. 人类数据的稀缺性日益凸显:高质量的专家标注数据成本高昂且难以规模化(Gilardi et al., 2023; Villalobos et al., 2024)。构建大型监督数据集的边际成本迅速增长,而专家劳动力资源却始终有限。 1. 更深层的局限在于人类认知的边界:如果模型监督始终受限于人类智能,模型是否能真正超越人类水平?当模型在某些领域接近或超过人类水平时,人类反馈可能不再能提供足够的信息梯度(Informative Gradients)以支持进一步提升(Bowman, 2023; Burns et al., 2023)。这提出了一个根本性问题:当模型与其监督者(人类)水平持平时,如何持续进化?
上述局限共同促使学术界探索模型自我改进(Model Self-improvement)这一极具前景的方向。模型不再完全依赖外部的人类信号,而是利用自身能力来生成数据、评估输出并迭代优化其策略。 从自动化的角度来看,这一方向不仅是理想的,而且是必然的。随着 LLMs 的进阶,它们展现出了解决复杂工程任务和参与高层决策的能力。鉴于 LLMs 的开发过程(包括数据获取、筛选和模型训练)本身就是一项高度复杂的工程任务,将这些职责委派给模型自身是一个自然的演进过程。通过将 LLMs 作为智能体(Agents)来编排自身的开发生命周期,一个“系统侧”的自我改进闭环得以建立。如图 1 所示,我们的愿景是从人类驱动的模型开发转向自主自我改进系统范式,使 LLM 通过自主导向的迭代和反馈不断增强其能力。 我们将 LLM 的自我改进定义为:**一种在没有持续人工干预(Human-in-the-loop)的情况下,模型迭代增强自身能力的学习范式。**该范式具有两个核心属性: * 自主性(Autonomy):改进过程无需持续的人工标注或手动校正。“自我”并不排斥外部组件;系统仍可使用教师模型、验证器(Verifiers)、评论家(Critics)、奖励模型或自动评估器等辅助模块。关键要求是:学习环节一旦部署,必须是完全自动化的。 * 持续性(Continuity):自我改进并非一次性的细化,而是一个迭代的、自我强化的过程。前期阶段的输出或经验被重新利用,为后续更新产生更强的监督信号。每一轮改进都依赖并放大先前的成果,从而实现随时间推移的累积式进展。
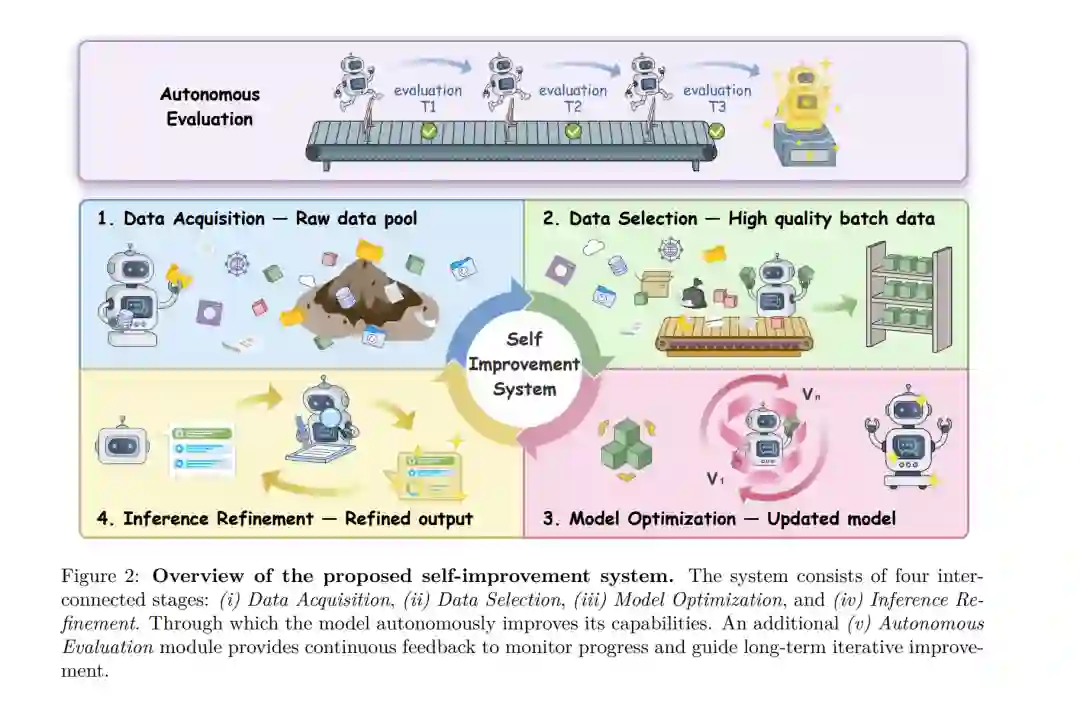
在此定义下,自我改进不仅仅是提升任务指标的技术,更是一种实现持续、自主增长的结构性能力。从 AI 长期发展的视角看,这种能力被广泛认为是构建能够超越初始训练范畴、实现持续学习与适应的系统的核心。 受此愿景启发,如图 2 所示,我们提出了一个由五个互连组件组成的生命周期自我改进系统。其中四个组件——数据获取、数据筛选、模型优化和推理细化——共同解决了一个核心问题:为了构建端到端的自我改进系统,如何在不同阶段利用模型自身来驱动持续且自主的贡献?具体而言: * 数据获取(Data Acquisition):模型自主收集或生成训练数据。 * 数据筛选(Data Selection):模型独立评估并过滤出质量更高、更适合自身学习的数据点。 * 模型优化(Model Optimization):模型自主学习,有效地将数据转化为其参数内部的增强能力。 * 推理细化(Inference Refinement):模型在推理过程中提升性能,而无需更改底层参数。
除了这四个阶段,系统还需要一种长期衡量与引导机制,以确保自我改进的稳定性和可持续性。为此,我们引入了第五个组件:自主评估(Autonomous Evaluation)。它为模型表现提供持续反馈,并引导其未来的发展方向。由于静态基准测试(Benchmarks)会迅速过时,且人工评估无法随系统规模同步增长,这种机制至关重要。通过自主评估,模型可以保持及时、自适应的反馈,支撑长期的持续改进。 这五个组件共同将模型置于自动化迭代闭环的核心地位。该统一系统确保了改进信号能够被一致地生成、筛选、应用、细化和评估,为实现更广泛的系统级 LLM 自我改进铺平了道路。 近期已有一些综述从不同角度探讨了自我改进。例如,Tao et al. (2024) 关注通过自我训练和强化学习实现的策略级自我演化;Dong et al. (2024) 评述了提示词(Prompting)和解码细化等推理侧改进技术;Fang et al. (2025a) 和 Gao et al. (2026) 则强调智能体系统,突出记忆、反思和工具增强交互。尽管如此,现有研究大多集中在特定阶段(如训练或推理)的局部机制。相比之下,我们采用了系统级视角,将自我改进概念化为一个统一的、闭环的生命周期,将模型开发的所有阶段整合进一个连贯的、用于可扩展自主演化的端到端框架中。 本文余下部分分为两个主要部分。首先,从技术角度系统研究自我改进系统中的每个组件(§2 至 §6),并将其分类(如图 3 所示)。其次,我们将讨论更宏观的自我改进系统(§7 至 §9),涵盖挑战、局限、应用及未来展望(结构如图 9 所示)。此外,尽管本文以模型为中心,但也纳入了关于**自我演化智能体(Self-evolving agents)**的研究。我们认为,从单一阶段向统一自我改进系统的转变,与从独立模型向智能体系统的转变相呼应,反映了向更自主、交互式学习系统范式发展的共同趋势。