人工智能与心理科学的交叉领域正经历显著增长,年发文量已从 2000 年的 859 篇跃升至 2025 年的 29,979 篇。然而,这种快速演进导致了方法论的“碎片化”现象,即相似的计算技术在彼此孤立的心理学领域中被重复独立开发。
本综述提出了首个系统性分类法,旨在根据计算处理模式而非应用领域对 AI 驱动的心理学任务进行重构,将其划分为四种基本类型:分类任务、回归任务、结构化关系任务以及生成交互式任务。通过对跨越预训练模型时代与大语言模型时代的 300 余项代表性研究进行分析,我们探讨了计算方法如何从特定任务的特征工程(feature engineering)演进为迁移学习(transfer learning)及少样本自适应(few-shot adaptation)。此外,本文系统梳理了相关数据集、评估指标与基准测试,并探讨了包括可解释性、标签不确定性、隐私限制及跨文化有效性在内的核心挑战。
这种计算视角的审视揭示了此前被“以领域为中心”的组织方式所掩盖的可迁移方法论模式,从而为计算心理学的系统性知识迁移与加速发展提供了可能。
1 引言 (Introduction)
人工智能已经从根本上改变了我们研究人类心理学的方式。最初仅为自动化心理评估的简单尝试,现已演变为一套涵盖心理健康诊断、人格分析、认知评估以及治疗干预的综合性计算方法。这种转型可从出版物数量的显著增长中得到证实:该领域的发文量从 2000 年的 859 篇扩张至 2025 年的 29,979 篇,实现了 35 倍的增长。这既反映了 AI 技术的成熟,也体现了学界日益增长的共识,即计算方法能够处理传统研究范式在以往尺度下难以企及的心理学问题。
这一增长轨迹揭示了三个截然不同的演进阶段,每个阶段均以不同的技术能力和研究方法论为特征,如图 1 所示。**基础增长阶段(2000 年至 2010 年)**通过包括支持向量机(SVM)、决策树和集成方法在内的传统机器学习方法,建立了心理数据分析的基本计算框架。年发文量从 859 篇稳步增长至 2,687 篇,平均每年增加 200 至 300 篇。**加速发展阶段(2010 年至 2018 年)**见证了深度学习架构的兴起,其表示学习(representation learning)能力实现了更复杂的模式识别。在此期间,发文量从 2,687 篇增至 7,556 篇,年产出达到 500 至 600 篇。**指数扩张阶段(2018 年至 2025 年)**始于 BERT 和 GPT-2 等预训练语言模型的出现,开启了超过 20% 的持续年增长率。2023 年大语言模型(LLMs)的引入进一步加速了这一进程,通过零样本学习(zero-shot learning)、少样本自适应(few-shot adaptation)和自然语言交互界面,从根本上改变了心理学任务的计算处理方式,最终在 2025 年达到 29,979 篇。
这种数量上的扩张反映了心理学研究开展方式的根本性学科转型。图 2 显示,计算机科学类出版物经历了指数级增长,从 2000-2010 年期间的约 12,000 篇增加到 2018-2025 年期间的近 100,000 篇,实现了数量级的跨越。工程学、数学、神经科学和医学成像在传统心理学学科之外也获得了显著地位。相比之下,行为科学和精神病学等核心心理学领域仅表现出适度的线性增长。这种分歧表明,研究重心正发生根本性偏移——从“以心理学为中心”的方法转向利用先进 AI 技术、多模态数据处理和大尺度计算资源的“以计算为中心”的方法。理解心理计算与常规 AI 应用的本质区别,为组织这一不断扩张的领域提供了必要的背景。
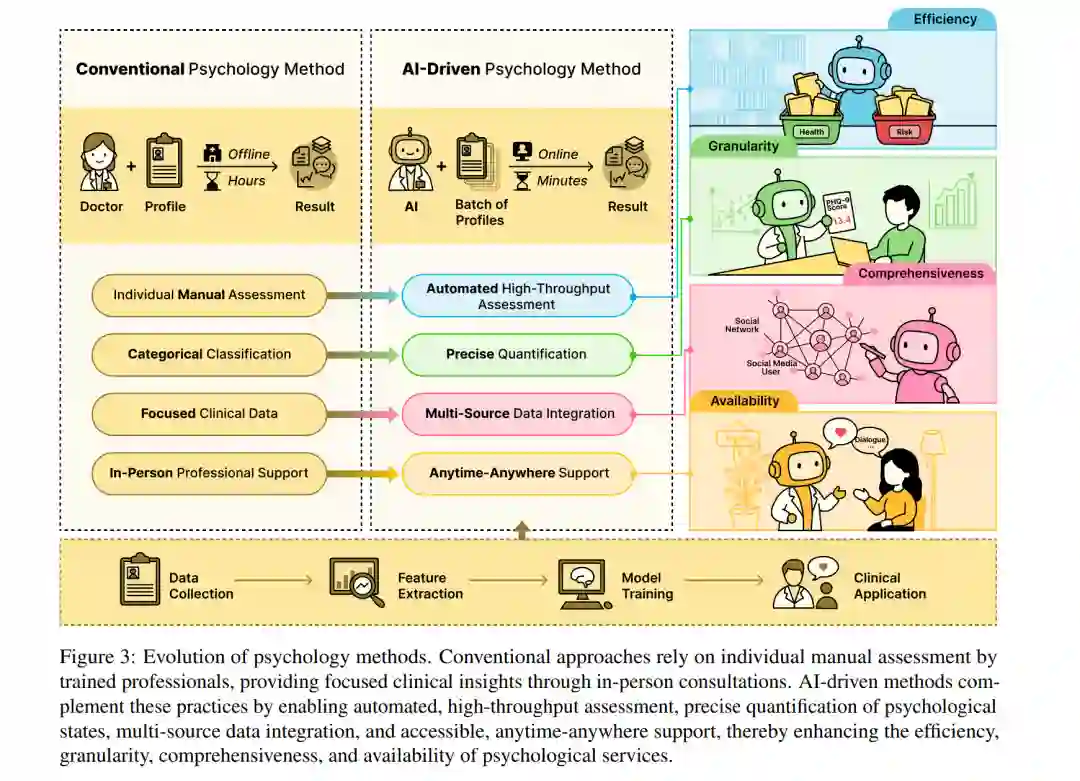
传统的心理评估方法通过数十年的专业实践建立了严谨的临床标准。受过训练的临床医生进行个性化的手动评估,通过面对面咨询捕捉细微的行为模式和情境因素,从而提供深度临床见解。这些传统方法擅长提供个性化护理并建立有效干预所需的治疗关系。然而,日益增长的心理服务需求和多样化数据源的涌现,为计算方法补充这些既有实践创造了机会。如图 3 所示,AI 驱动的方法从四个关键维度增强了传统方法: 1. 自动化高通量评估:能够同时对大规模人群进行评估,在几分钟而非几小时内处理批量档案,将心理服务的触达范围扩展到了一对一咨询的约束之外。 1. 精准量化:将类别分类转化为连续测量,例如将二元抑郁筛查转化为如 PHQ-9 评估般的细粒度(fine-grained)严重程度评分,以追踪症状随时间的演变。 1. 多源数据集成:在重点临床数据之外,综合来自社交网络、社交媒体活动和对话交互的信息,在自然情境下提供更全面的心理状态图景。 1. 随时随地的支持:通过在线平台提供可及的干预,补充定期的线下专业咨询,并在关键时刻提供持续监测和即时援助。
推动这一转型的技术创新浪潮引入了日益强大的能力。早期的机器学习方法证明了统计模型可以识别心理数据中的模式,超越了简单的基于规则的系统,从而捕捉行为指标与心理状态之间的复杂关系。BERT 和 GPT-2 等预训练模型的引入带来了迁移学习能力,使研究人员能够利用大规模数据集的知识,并将其应用于领域特定数据有限的专门心理学任务。最近,GPT-4 和 Claude 等大语言模型引入了仅需极少特定任务训练即可处理复杂心理学任务的能力。这些模型现在可以进行结构化临床访谈,生成个性化治疗内容,并分析心理健康状况中细微的语言标记。
然而,这种快速扩张造就了日益碎片化的研究格局。设想一位研究人员正开发一套基于 Transformer 的系统,用于从社交媒体帖子中检测抑郁症。他们使用标注数据对 BERT 进行微调,雇用注意力机制来识别相关的语言特征,并使用临床验证指标评估性能。与此同时,另一支团队正使用近乎相同的技术方法构建人格评估系统。他们使用相同的 BERT 架构、相似的微调策略和具有可比性的基于注意力的特征提取。尽管存在这些计算上的相似性,这两组研究者很可能在不同的会议/期刊发表论文,使用不同的术语,并且在很大程度上对彼此的方法论创新互不察觉。
这种方法论孤立的模式在整个领域不断重复。事实证明对治疗对话系统有效的提示工程(Prompt engineering)技术本可惠及教育心理学应用,但此类知识很少跨越领域边界进行迁移。为自杀风险预测开发的注意力可视化方法,与认知评估中应用的方法具有相同的底层机制,然而这些方法往往是被独立重新发现的。从事抑郁检测、人格评估和认知评估的研究人员频繁采用相似的神经架构和计算技术,但这些子领域之间的交叉引用却极其罕见。该领域一直围绕临床心理学、教育心理学和人格研究等“应用领域”而非“计算特征”进行组织。这种组织方式掩盖了能够加速进展的技术共性。
这种碎片化对研究效率和科学进步带来了实质性的后果。当方法论进展本可以惠及更广泛的领域时,却被局限在狭窄的应用区域内。研究人员浪费精力去重新发现相邻领域已经建立的技术。或许最关键的是,缺乏统一的计算框架使得难以识别哪些技术方法在不同心理学任务中表现良好,哪些从根本上局限于特定应用。如果没有系统的方法来组织和比较计算方法,随着新 AI 技术的出现,该领域面临着持续“巴尔干化”(balkanization,指割据碎片化)的风险。
1.1 心理学任务的计算视角 (A Computational Perspective on Psychological Tasks)
本综述通过计算特征而非应用领域来组织 AI 驱动的心理学,从而应对上述挑战。我们提出,心理学 AI 应用可以通过四种基本的计算范式来理解。每种范式均由其处理信息和生成输出的方式定义。
**分类任务(Classification tasks)**通过判别式模式识别鉴定离散的心理状态。这些任务确定某人是否表现出抑郁、识别性格类型或分类认知状态。其计算挑战在于学习能够在高维特征空间中分离心理构念(psychological constructs)的决策边界。抑郁检测分类器和人格类型识别器可能服务于不同的临床目的,但它们面临着相同的计算挑战,包括处理类别不平衡、确保稳健的特征提取以及在不同人口统计群体间保持性能。
**回归任务(Regression tasks)**通过预测分级量表上的数值来量化连续的心理测量。这些任务不是分配类别,而是估计抑郁严重程度评分、预测认知能力水平或测量情感强度。计算重心转向学习能够将输入准确映射到连续输出空间、同时保持临床可解释性的函数。预测抑郁严重程度的系统与评估认知下降的系统共享相同的技术需求,包括处理测量不确定性以及确保预测与既定的临床量表一致。
**结构化关系任务(Structured relational tasks)**通过结构化元组提取并建模心理构念之间的复杂关系。这些任务从非结构化数据中提取实体-关系对、事件-论元结构或时间序列。输出形式为元组,可用于构建症状网络、社会支持图谱或发展时间轴。计算挑战涉及学习能够捕捉关系结构和时间动态、同时反映心理学理论的表示。无论是从临床叙述中提取症状交互,还是在教育环境中建模发展轨迹,这些系统都采用相似的基于图的架构(graph-based architectures)和信息提取技术。
**生成交互式任务(Generative interactive tasks)**通过与用户的动态参与创建个性化的心理内容。此类范畴涵盖了解释心理机制、生成治疗干预、提供心理健康支持或交付自适应教育指令的系统。我们将这些视为统一的计算范式,因为它们共享一个基本机制:合成适应于不断演变的用户状态的上下文相关响应。无论是生成单个治疗建议还是维持多轮咨询对话,这些系统都执行相同的核心操作,即上下文响应合成。治疗对话系统和教育辅导智能体可能针对不同的应用,但两者都必须解决相同的技术问题,包括维持交互上下文、生成合适的响应以及适应用户反馈。
这种计算分类法揭示了从以领域为中心的视角无法察觉的模式。通过围绕计算共性而非应用领域组织任务,我们实现了在传统孤立的研究社区之间进行系统性的知识迁移。为一种任务类型开发的注意力机制可以被改编用于具有相同计算结构的其他任务。解决临床应用中数据稀缺的训练策略,可以迁移到面临类似约束的教育背景中。为某一领域设计的评估框架可以被改编,用于评估具有类似需求的关联领域的系统。
1.2 综述范围与贡献 (Survey Scope and Contributions)
我们的分析跨越了两个重塑心理学研究方法论的变革性技术时代。**预训练模型时代(2018 年至 2022 年)**通过 BERT 和 GPT-2 等架构引入了迁移学习,使得利用有限的领域特定数据进行复杂分析成为可能。**大语言模型时代(始于 2023 年)**带来的能力通过零样本学习和自然语言接口,显著降低了心理学应用的部署门槛。我们考察了计算方法在这些时代中是如何演进的,追踪了从特定任务的特征工程到迁移学习范式,再到最终仅需极少领域特定训练的自适应能力的演变过程。这一历史视角不仅阐明了发生了什么变化,还阐明了为什么某些方法取得了成功,而其他方法则面临根本性局限。
我们还探讨了整合文本、语音、视觉和生理信号的**多模态方法(multimodal approaches)**日益增长的重要性。人类心理状态同时通过多个交流渠道表现出来,当代评估系统越来越多地利用人类表达的这种多维特性。我们的分析考察了计算机视觉、语音处理和传感器技术的进步如何补充基于语言的模型,以创建更全面的心理评估系统。
本综述对计算心理学文献做出了四个主要贡献: * 计算分类法:我们在第 3 节中引入了一个综合分类法,按基本计算处理模式而非应用领域组织 AI 驱动的心理学任务。该分类法揭示了可迁移的方法论模式,并实现了传统孤立子领域间的系统知识迁移。 * 跨时代技术分析:通过对 300 多项代表性工作的分析,我们在第 5 节追踪了计算方法如何从预训练模型演进到 LLMs。我们考察了单模态和多模态方法,探讨了文本、语音、视觉和生理信号的集成如何创建更全面的评估系统。 * 系统性资源调查:我们在第 4 节提供了跨不同心理学领域的数据集、评估指标和基准测试的全面覆盖。我们的调查有助于研究人员识别合适的资源并理解不同评估方法之间的权衡。 * 挑战分析与未来方向:我们在第 6 节系统分析了心理计算中的基本挑战,包括可解释性、隐私保护、文化有效性和临床效用。针对每项挑战,我们在第 7 节考察了具体的技术方法和具有前景的研究方向。
本综述的其余部分安排如下。第 2 节建立理论和技术基础,考察心理数据的独特特征和正式的任务形式化。第 3 节介绍我们的计算分类法,并对每类任务的代表性应用和技术需求进行全面分析。第 4 节调查了不同心理学领域可用的数据集和评估指标。第 5 节对跨越两个技术时代的方法进行了详细的技术分析,涵盖架构、训练策略和自适应技术。第 6 节识别了基本的技术挑战及应对策略。第 7 节讨论了具有前景的研究方向和新兴机会。第 8 节综合了关键见解,并为研究人员和从业者提供了建议。我们在 GitHub 上维护了一个公共仓库,并持续更新相关工作和资源。