
论文标题: When LLMs Develop Languages: Symbolic Communication for Efficient Multi-Agent Reasoning
论文作者: Zhengqi Pei, Qingming Huang, Shuhui Wang 作者单位: 中国科学院计算技术研究所,中国科学院大学 ICML官方链接: https://icml.cc/virtual/2026/poster/61557 论文链接: https://openreview.net/pdf?id=ovpL0ujD6j 代码与后续工作: https://github.com/pzqpzq/LSF_MDia 成果应用: https://github.com/pzqpzq/Principia
导读Chain-of-Thought 可以让大模型把思考写出来,这种操作在众多复杂任务上被证实有效。但如果中间推理的主要接收或处理对象并不是人类,而是另一个LLM,那么基于自然语言的长推理链未必是最合适的中间表示。受此启发,本论文提出的 CLSR (Communicative Language Symbolism Routing) 提出一个更底层的问题:**LLM 是否一定要用自然语言来组织推理?**CLSR 认为,多个 LLM agent 在正确性与推理成本的选择压力下,可以自主地生成、演化得到各式各样的机器语言符号体系,即 Language Symbolism Frameworks(LSFs)。CLSR 就是针对这些语言符号体系的管理机制。实验显示,在多类推理 benchmark 与多种开源 backbone 上,CLSR 通常可以把面向延迟的生成端 completion tokens 降低约 3–6 倍,同时基本维持 Raw CoT 的准确率水平,并在若干设置中获得更好的 accuracy–token Pareto frontier。更重要的是,它给出了一个值得进一步研究的范式:推理效率的关键,不只是让模型“少说话”,还要让模型使用更高信息密度、更可复用、更可路由的中间语言。
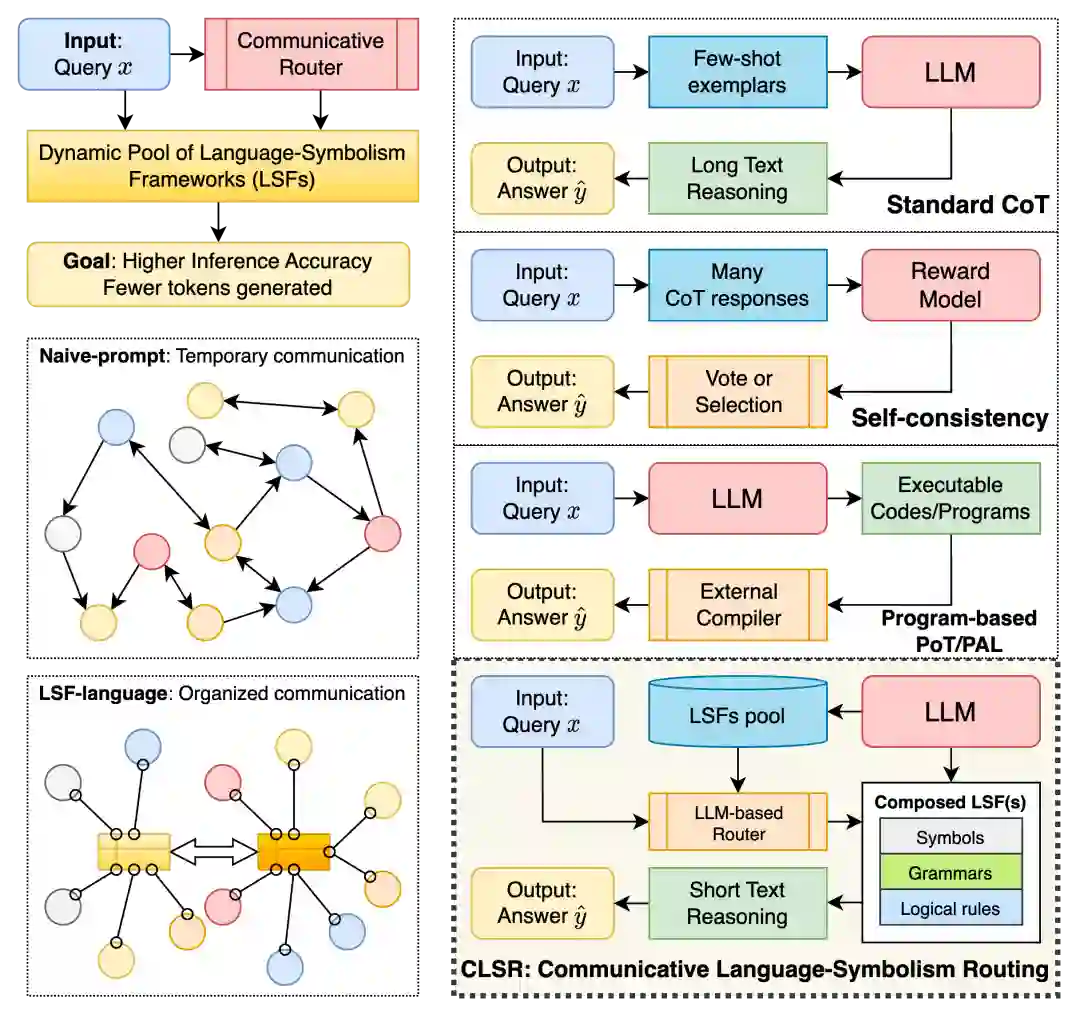
0. 概要
CLSR 所说的语言,并非人类专属的自然语言,也不是声称 LLM 获得了人类式的语言能力。它指的是操作意义上的离散符号通信协议,简写为 LSF (Language Symbolism Framework)。CLSR 可以让大模型多智能体系统在推理能力和能效的双重压力下,大批量产生各式各样的 LSF 协议。具体来讲,给定任务、模型族、token预算、目标准确率,CLSR 可以让大模型多智能体系统生成、复用、自主演化若干套包含符号、语法、推理操作、有效性约束和经验 profile 的中间表示(即 LSF)。这些 LSF 协议可以被 CLSR 灵活调用、比较、路由、组合、淘汰,也可以在后续任务上继续使用。 因此,CLSR 要解决的是一个更具体、更可实验化的问题:在 black-box LLM 设定下,能否自动发现一类离散、可存档、可复用的中间推理协议,使其比自然语言 CoT 更接近 accuracy–token frontier?
该问题的重要性体现在,当前的主流推理系统已经不再是单个模型一次性输出答案,它们常常涉及到多个角色(solver、router、critic、verifier、tool user、aggregator)之间的交互与协作,这种协作过程涉及到的中间状态往往非常繁冗复杂,既然这些消息的主要处理者是机器,那么自然语言的可读性、修辞连贯性和解释性冗余,就可能变成额外带宽成本。 CLSR 则把“推理链”从一段文本重新定义为一种带宽受限的状态传输机制。
1. 问题背景:Chain-of-Thought难以兼顾推理精度和推理成本
CoT 的成功来自一个非常朴素但强大的事实:对复杂问题显式生成中间步骤,通常比直接给出答案更稳定。无论是数学推导、科学问答、逻辑选择还是多跳检索,外化中间状态都能降低一次性解码的难度。 但 CoT 同时带来一个结构性成本:它默认中间状态必须以自然语言 prose 的形式展开。 对于人类来看,自然语言是合理的沟通接口,但对于模型来说,却不一定是最合理的交互接口。标准 CoT 中常见的大量内容,例如,“首先我们考虑……”、“因此可以看出……”、“为了验证答案,我们再检查……”,这虽然对人类读者很友好,但对模型继续推理所需的最小状态而言,可能只是信息密度较低的形态。尤其在 autoregressive decoding 中,生成端 token 不仅影响成本,还会直接影响延迟和吞吐。 已有方法大致沿着以下几条路线缓解这一问题。 第一类是 prompt optimization。它优化自然语言指令的表面形式,希望找到更好的提示词。这类方法很有价值,但它优化的对象主要还是临时的“指令字符串”,而不是一个持久可用的符号协议。 第二类是 short reasoning prompting,例如 Chain-of-Draft、Sketch-of-Thought、Compressed CoT 等。它们让模型少写或写草稿式推理。问题是,短并不等于有效:如果压缩删掉了变量绑定、候选排除、证据链接或验证状态,准确率会随之下降。 第三类是 program-aided reasoning,例如 PoT、PAL 等。它们把推理转成程序,由外部解释器执行。这条路线在可程序化任务上非常强,但它依赖人类预设的程序语言和外部 executor,也不直接回答“LLM 自身能否发现适合自己的中间符号系统”。 CLSR 的切入点与上述方法都不同。它并不把 CoT 当作一段需要压缩的自然语言文本,而是把推理过程视为机器之间的通信问题:如果 token 是带宽,那么推理效率的本质就是:每个 token 能携带多少对答案有用的状态。
这使得研究目标从“减少字数”转向“提高单位 token 的有效信息密度”。
2. 理论视角
CLSR 论文中一个关键思想是把测试时推理形式化为一个 constrained stochastic control problem。

CLSR 主要是针对第二类操作。它的目标是让模型发展出更紧凑、更结构化、更适合自身解码习惯的符号协议。 这个视角也解释了为什么“永远更短”不是正确目标。题目越难,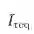
3. LSF:可复用的机器推理协议
CLSR 的基本单元是 Language Symbolism Framework,简称 LSF。论文中把一个 LSF 表示为:
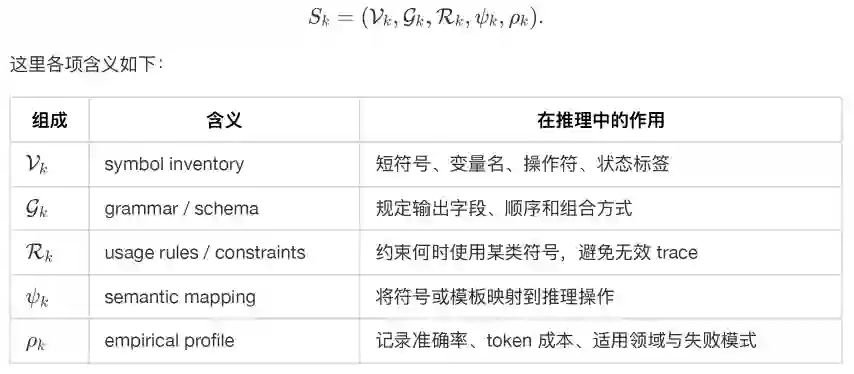
这个定义使 LSF 与普通 prompt 区分开来。Prompt 通常是一次性自然语言指令,而 LSF 则更像一张协议卡。它可以被多次调用,可以在样例分布上评估,可以由 router 选择或组合,也可以在演化过程中被继承、变异和淘汰。 更直观地说,一个数学类 LSF 可能会倾向于保留变量绑定、子目标、变形操作、校验标签和最终答案字段;一个科学问答类 LSF 可能更强调证据等级、候选排除、概念约束和短验证;一个多跳检索类 LSF 则可能保留证据桥、null guard、support status 和 answer contract。 下面是一个概念示意,反映了 LSF 所追求的中间状态形态: [bind] x=..., y=... [sub] need: eliminate distractor B/C [op] evidence(A) > evidence(D); constraint: mechanism match [chk] no contradiction with condition-2 [ans] A 这类表达并不追求文学性,也不追求对人类完全自解释。它追求的是:在尽可能少的 token 中,保留足以让模型继续推理、验证或输出答案的结构化状态。
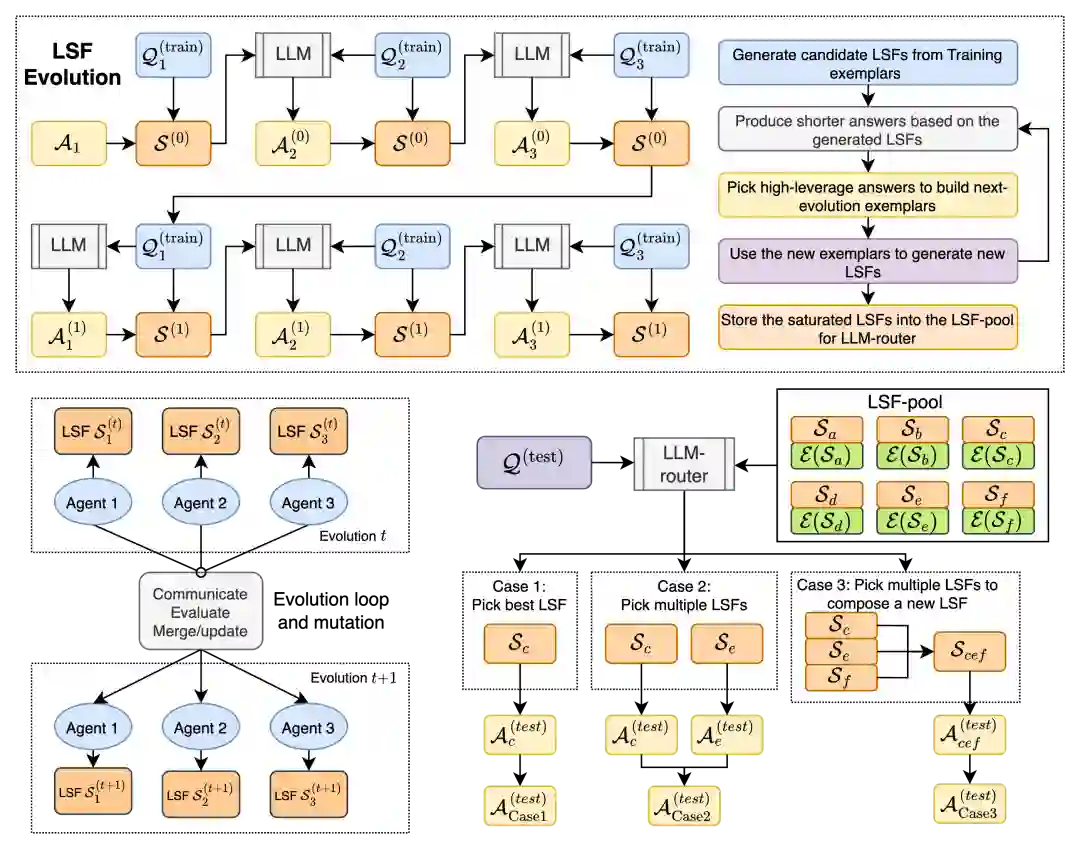
4. CLSR 如何工作:生成、演化、路由
CLSR 可以分为三个阶段:LSF synthesis、LSF evolution、test-time routing。
4.1 从样例中生成初始 LSF
给定 benchmark 的训练样例,CLSR 首先采样一批 exemplars,将它们作为上下文提供给 LLM。模型被要求设计一种能在保持推理能力的同时减少 token 的 LSF。默认流程中不对符号表、语法或规则进行人工编辑;人类只给出高层目标,即“正确且 token-efficient”。 这一步主要是为了得到一个多样化的初始语言池。较高采样温度会产生从 strict LSF 到 soft LSF 的一系列候选:前者更接近机器式压缩协议,后者仍保留较多自然语言结构。
4.2 通过选择压力演化 LSF
随后,CLSR 使用一个迭代 bootstrapping 过程逐代改进 LSF pool:
- 用当前 LSF 回答新的训练/验证问题;
- 记录答案正确性与 completion token 成本;
- 选择同时正确且短的 high-leverage traces;
- 将这些 trace、父代 LSF 和失败信息反馈给 LLM;
- 生成下一代 LSF,并重复评估、选择、变异。
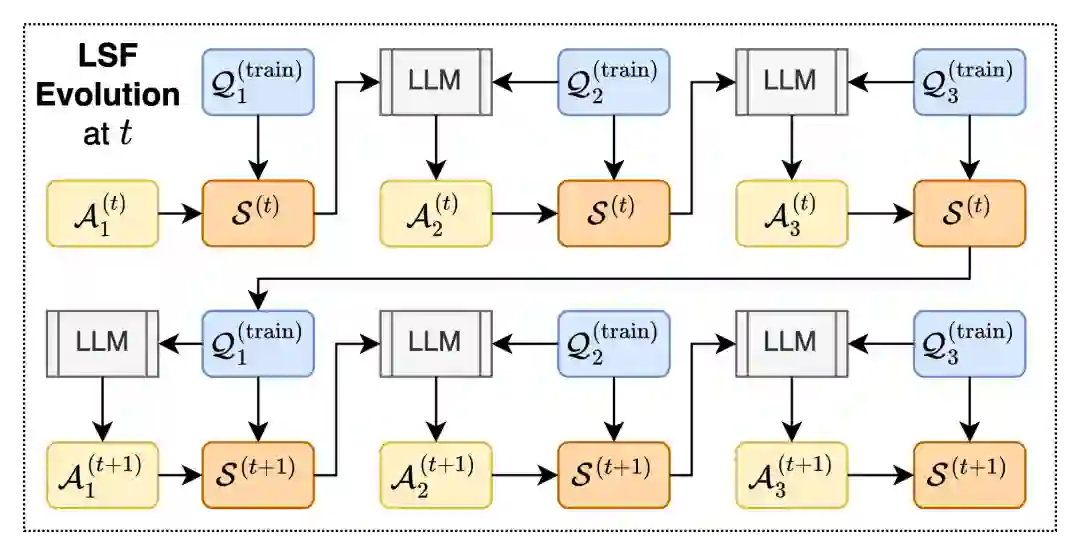
这里的“agent”并不是训练出的独立神经模块,它们其实是由 backbone、随机种子、样例子集和生成上下文定义的 black-box LLM proposal/critique/mutation worker。增加 agent 数量,本质上是在扩展符号协议搜索空间。 这一过程类似一个小型的机器语言体系演化过程:正确性是 communicative success,token 长度是 production cost,能反复被采用的符号与格式会被保留,不能稳定支持答案的压缩方式会被淘汰。 这也解释了为什么 CLSR 不等同于 prompt engineering。Prompt engineering 优化的是“如何提问模型”;CLSR 优化的是“模型之间应该用什么协议传递推理状态”。
4.3 测试时路由:让不同问题使用不同方言
演化得到 LSF pool 后,CLSR 在测试时不固定使用某一个 LSF,而是由 LLM-router 根据问题和 LSF profile 实时生成协议计划。 主要有三类推理模式: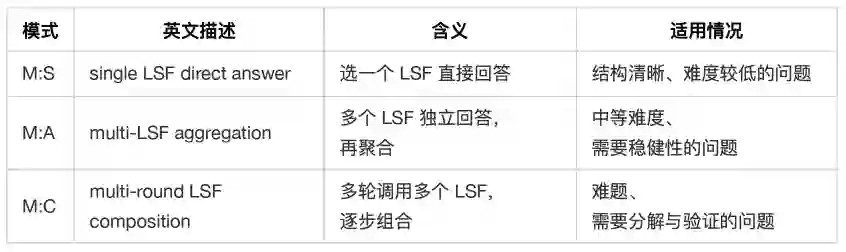
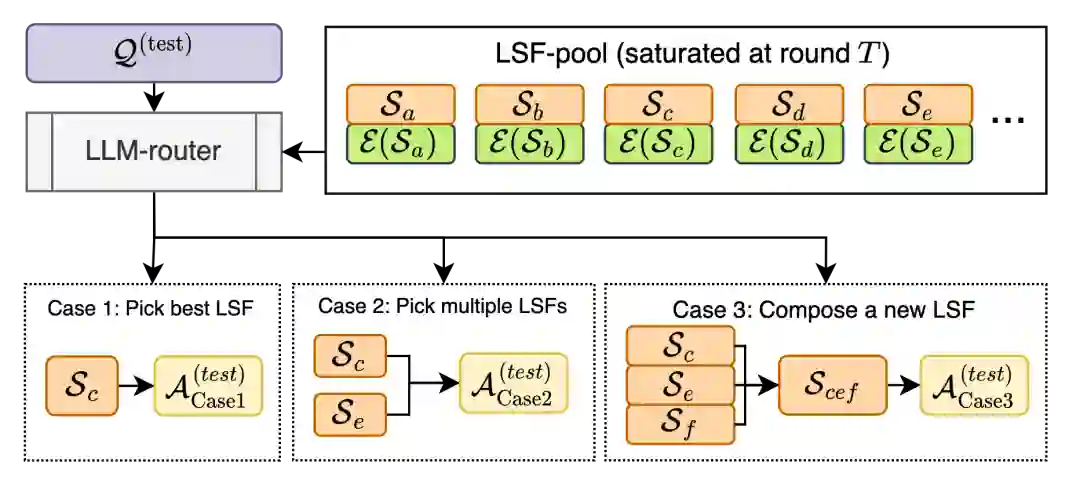
因此,CLSR 的目标并不是把所有回答压到最短,而是在预算约束下动态决定何时压缩、何时冗余、何时验证。对于简单题,单个低成本 LSF 就足够;对于 hard reasoning,router 可以主动花更多 token 去做分解、交叉检查和多轮组合。 这正是 CLSR 与普通短推理提示的核心区别:它优化的是路由策略与协议池,而不是固定长度风格。
5. 实验设置
论文在七类 benchmark 上评估 CLSR:MMLU-Pro、GPQA-main、GSM8K、MATH500、AIME21–24、ScienceQA、HotpotQA。这些任务覆盖知识密集型 QA、专家级科学问答、算术推理、竞赛数学、多选科学问答和多跳问答。 backbone 包括 LLaMA3-8B、DeepSeek-R1-Distill-Qwen3-8B、Qwen3-8B、Qwen3-32B 等开源模型。对比方法包括 Raw CoT、CoD、CCoT、SoT,以及 PoT、PAL、Plan-to-Solve、PromptBreeder 等程序化或 prompt 优化基线。 评价指标主要是两个:
-
Accuracy:最终答案准确率;
-
Completion tokens:测试时生成端 token,包括 CLSR 的 LSF 响应、router plan、中间响应和聚合等生成部分。论文附录也探讨了在online测试中的input token和output tokens的比例对真实latency和推理成本的影响。
CLSR 的核心 claim 的准确表述是:CLSR 在多模型、多任务上更稳定地把系统推向更好的 accuracy–token frontier:在接近 Raw CoT 准确率的同时,显著减少生成端 token;在相近 token 预算下,通常比简单短推理提示保留更多有效状态。
6. 主结果:CLSR 改善的是 accuracy–token frontier
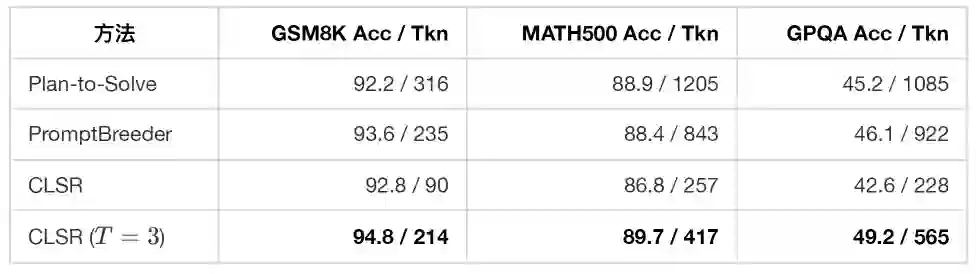
下表摘取论文主表中的若干代表性结果。每个单元格为 Acc / Tkn,Tkn 表示平均生成 completion tokens。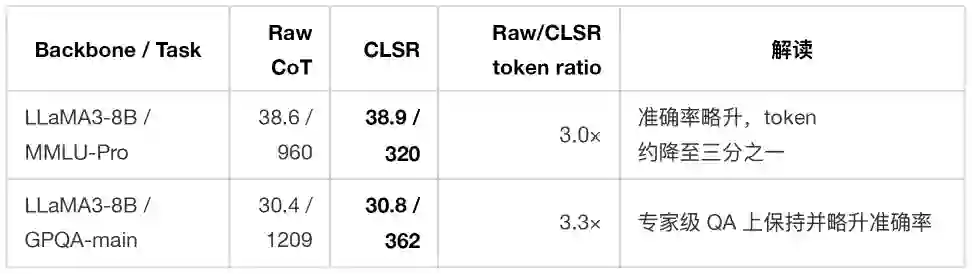
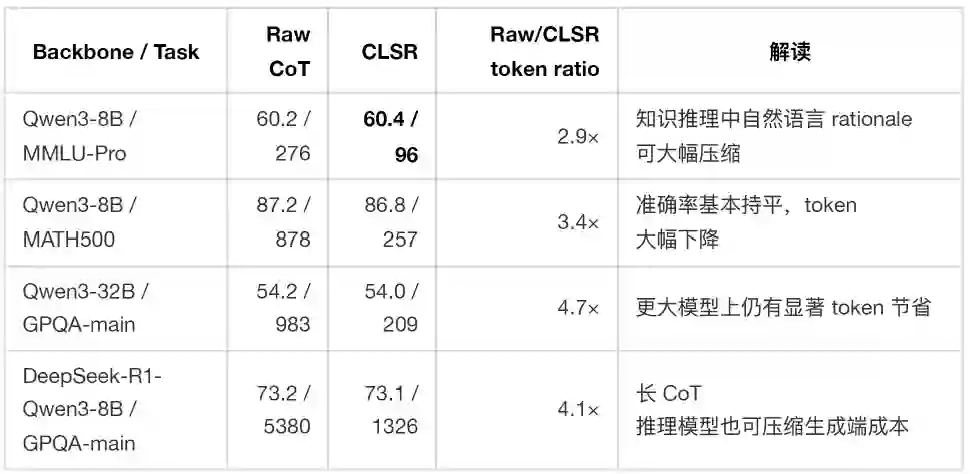
实验结果表明:CLSR 的收益并不只来自小模型,也不只来自简单任务。即使在强推理模型或长推理任务上,自然语言 CoT 中仍然存在大量对机器继续推理并非必要的表述。 更关键的是,与短推理 baseline 相比,CLSR 并非只是“更短”。以 Qwen3-8B 为例:
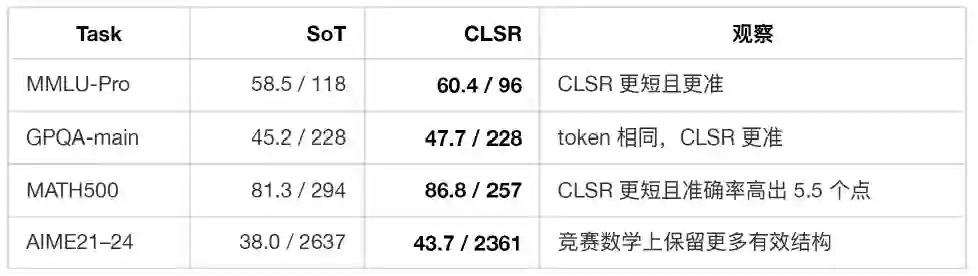
这组对比很能说明 CLSR 的本质:它并不是在自然语言 CoT 上做“文风压缩”,更主要是在寻找一种更合适的状态编码。短推理提示可能删掉了关键中间状态;LSF 则试图用更紧凑的符号保留这些状态。
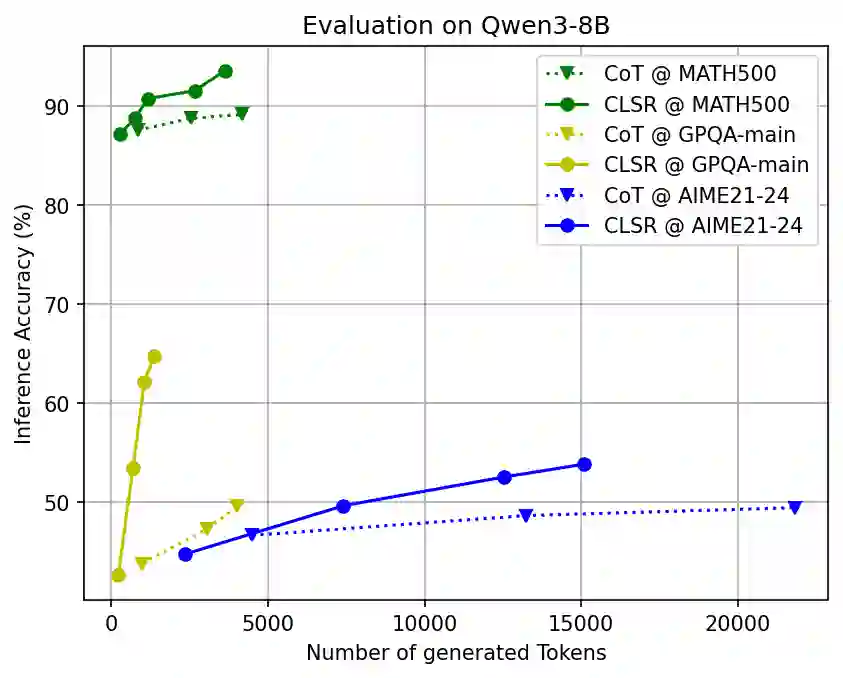
7. 机制分析一:CLSR 的收益来自“换码”,而非机械缩写
论文中的 accuracy–token 曲线显示,CLSR 在 MMLU-Pro、GPQA、GSM8K、MATH500 等任务上整体更接近 Pareto frontier。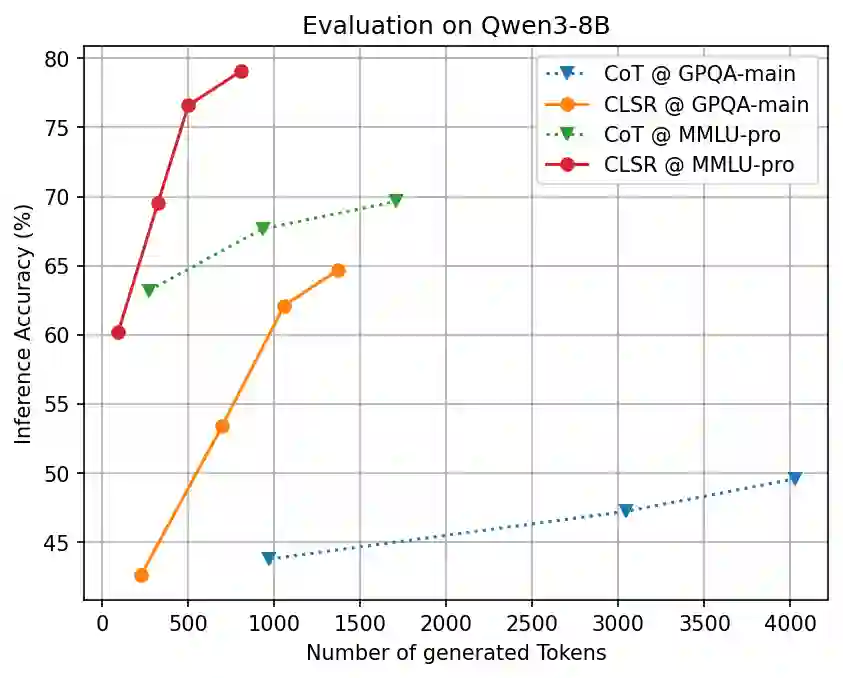
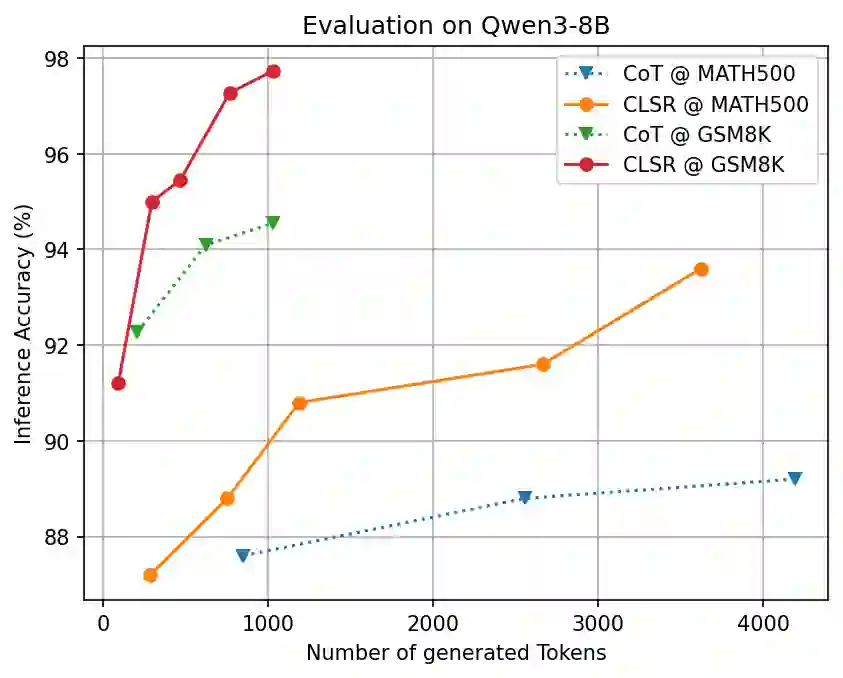
实验表明:当 token 预算增加时,CLSR 的额外 token 往往更能转化为准确率收益。这与理论中的 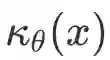
-
知识密集型 QA:压缩重点是证据筛选、选项排除与短验证;
-
数学推理:压缩重点是变量绑定、等式变形、子目标与 check;
-
多跳问答:压缩重点是 evidence bridge、support status、null guard;
-
格式敏感任务:压缩重点是 output contract 与 parseability。
这说明 LSF 是一组 task-conditioned、model-conditioned 的推理协议。
8. 机制分析二:难题更需要把 token 用在验证环节
CLSR 的一个重要 ablation 是多轮数 $T$。以 Qwen3-8B 为例:
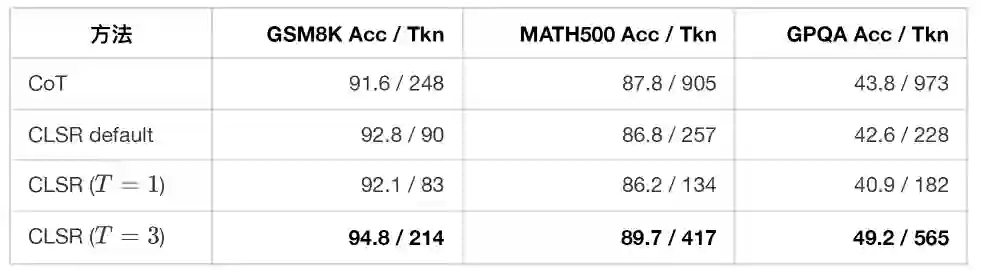
若把 CLSR 理解成“让模型尽可能短”,那么 $T=1$ 应该总是最优;但实验恰好说明不是。对于 GSM8K、MATH500、GPQA,$T=3$ 使用更多 token,却显著提高准确率,同时仍然少于 Raw CoT。 因此,针对难题推理任务,CLSR 的原则不是“少说”,而是:把 token 从自然语言叙述转移到结构化验证、分解和纠错上。
这也是高强度推理任务中最有价值的启示。很多失败的压缩方法把 verification 也删掉了;CLSR 则通过 router 决定什么时候需要更严格的 LSF、什么时候需要多个 LSF 聚合、什么时候需要多轮组合。
9. 机制分析三:CLSR 与程序化推理的关系
程序化推理方法如 PoT 和 PAL 把推理转成代码,再用外部解释器执行。CLSR 没有依赖外部 executor,但它通过多轮 LSF 协议,在一定条件下可以近似一种“模型内部的程序化状态更新”。论文也从理论上讨论了这种关系:在 interpreter-realizability 前提下,多轮 LSF protocol 可以条件性地 subsume program-execution pipeline。 Qwen3-8B 上的比较如下: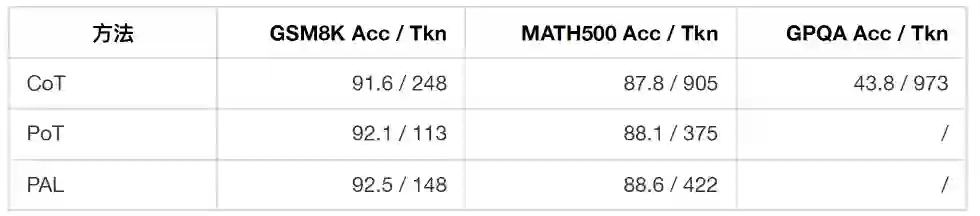
这里需要谨慎解读:PoT/PAL 的 token 统计只计算生成程序所用的 LLM decoding tokens,不等同于整个系统的所有执行成本;而 CLSR 的优势也不意味着外部 executor 不再重要。严格数值计算、长程序执行、形式验证等任务,外部解释器仍有独特价值。 CLSR 的更准确定位是:当任务所需的符号操作仍在模型内部可实现范围内时,LSF 可以提供一种 black-box、离散、可存档、可路由的中间协议;它不替代所有程序执行,而是扩展了“自然语言 CoT”和“外部程序执行”之间的表示空间。
10. 定性样例:LSF trace 更像工作区
定性样例展示了 CLSR 改变的内容。标准 CoT 往往像一段面向读者的解释文;CLSR trace 更像一个压缩工作区,保留变量、操作、候选、检查与最终答案。
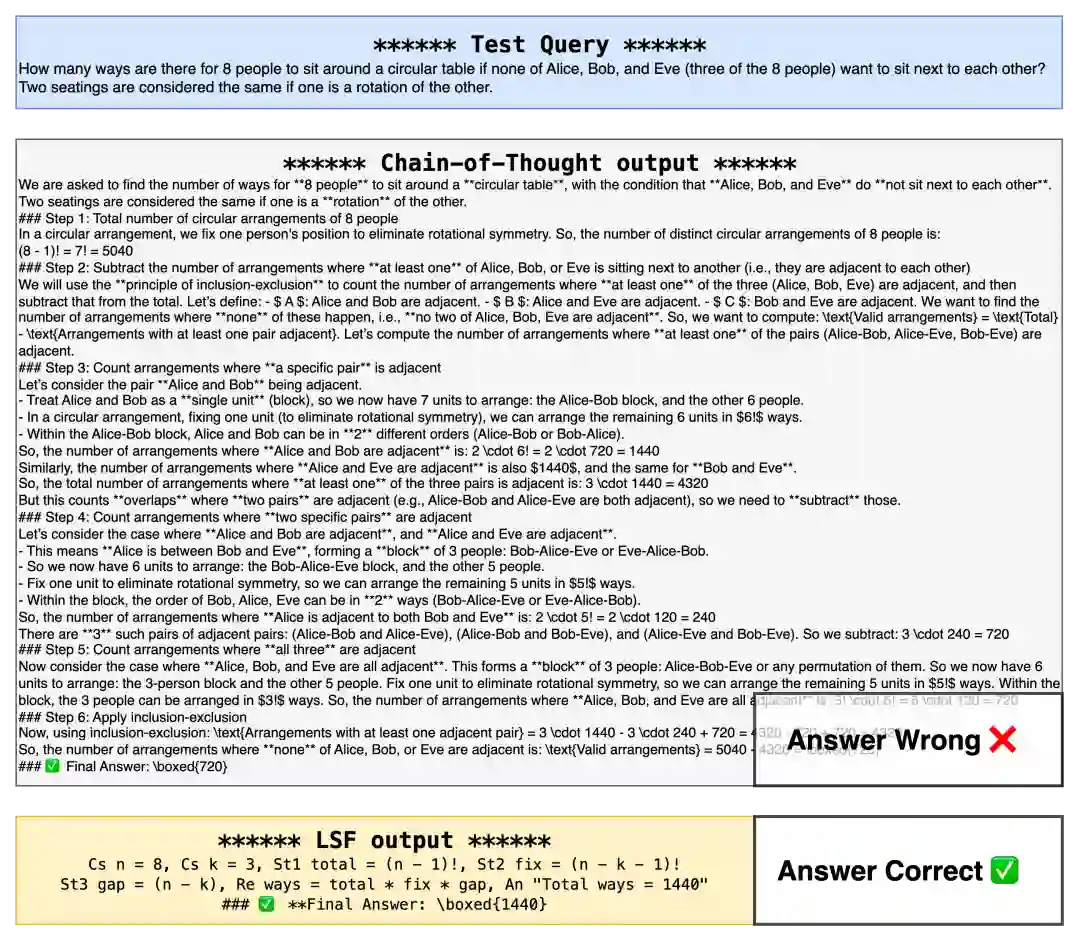
这类 trace 并非完全不可读。很多有效 LSF 仍然借用了人类数学符号、短标签、箭头、括号、变量名和验证标记。原因显然:LLM 预训练于人类文本与代码/数学语料,完全任意的乱码未必稳定;真正有效的机器方言往往是在“人类可读符号”和“机器压缩协议”之间形成新的折中。 这也构成一个值得注意的可解释性问题。LSF 比普通 CoT 更短、更结构化,但不一定更容易被非专业读者理解。因此,在实际系统中更合理的设计可能是双层 trace:内部用 LSF 高效推理,外部在需要时生成自然语言解释,并保留 LSF card、route plan、raw trace、parsed answer 和 verifier log 以便审计。
11. Takeaway messages
CoT 的长,不全是推理本身
CoT 的长有两部分来源:一部分是解决问题确实需要的中间状态,另一部分是自然语言解释的表达成本。CLSR 的实验表明,在许多任务中,后者占比并不小。把这部分冗余换成符号化状态,可以在不显著损害准确率的前提下减少生成端 token。
Token-efficient reasoning 是表示学习问题,不是文本风格的控制问题
“请简洁作答”只能改变表面文本风格;LSF 演化改变的是中间表示。真正有效的压缩必须回答:哪些变量必须保留?哪些候选必须排除?哪些证据需要绑定?哪些检查标签不可删除?这些不是单纯长度约束能解决的问题。
没有一种机器方言对所有问题最优
简单题适合 strict、low-cost LSF;难题需要多轮组合和验证;科学 QA 与数学推导需要不同的状态结构;强模型和弱模型对同一种符号协议的适应性也不同。因此,CLSR 的关键不只是 LSF,还包括 LSF pool 与 query-adaptive routing。
小模型的能力不仅取决于参数,也取决于推理协议
小模型常常被迫生成大量自然语言叙述,导致宝贵 token 预算花在低密度表达上。若把预算更多用于结构化状态、验证和组合,小模型在特定任务上的 accuracy–token frontier 可以明显改善。这并不是说这些 LSF 协议能替代模型能力,而是说明系统设计能显著改变能力的可用形态。
机器语言的价值在于可复用、可评估、可路由
一个短 trace 只对一个样例有效,它只是压缩答案;一个 LSF 能跨样例复用、能被 profile 评估、能被 router 选择、能与其他 LSF 组合,它才成为一个操作意义上的机器语言。
紧凑的推理 trace 不是万能的
更紧凑的协议也会带来风险:过度压缩可能删除关键验证;符号 trace 可能降低人工可读性;不同模型之间的协议迁移可能出现负迁移;模型版本更新可能改变 LSF 的有效性。因此,CLSR 更适合作为一个可审计的协议层,而不是把所有内部思考隐藏在不可解释的短码中。
12. 从 CLSR 到 Machine Dialectology:机器方言不只是“自言自语”
CLSR 的续作是 Machine Dialectology(MDia)。如果说 CLSR 主要研究同类 LLM agent 如何生成、演化和路由 LSF,那么 MDia 进一步把问题扩展到异构 LLM 社会:不同模型可以是 speaker、listener、router、critic、tool user;一个 dialect 的价值不再只取决于它对生成者是否有效,还取决于它能否被其他 listener 理解、采用、传播和改造。
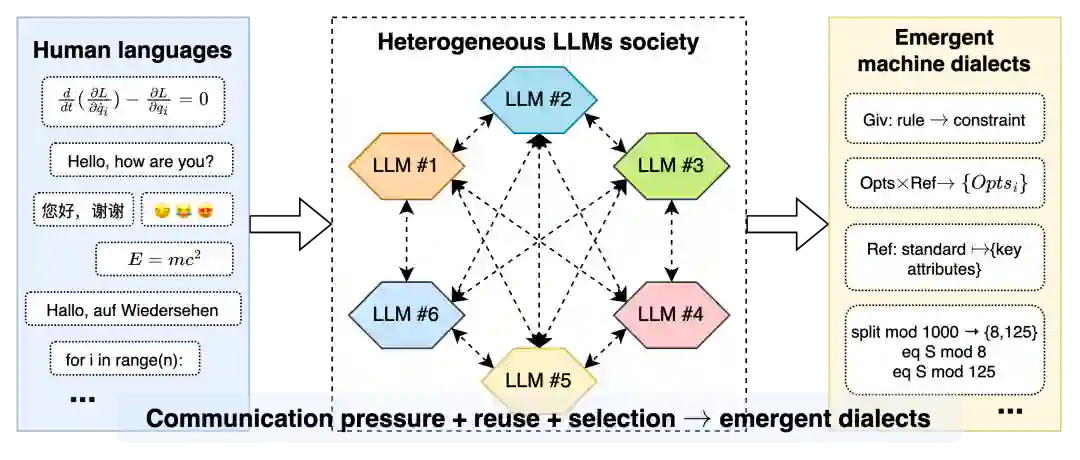
MDia 的分析单位是一个 speaker–listener–dialect–task event。每条 event 记录 query、benchmark、speaker、listener、dialect card、route decision、response、parsed answer、gold answer、correctness、completion tokens、router tokens、latency、seed 和 provenance。这样,“机器方言”不再只是一个 prompt 或 trace,而成为可以统计、比较、路由和归档的社会语言学对象。 MDia 的核心结论是 receiver-relative utility:一个 dialect 不是绝对强或弱,而是对某个 listener、某类任务、某个预算条件强或弱。这一结论对多模型系统尤其重要,因为实际部署中我们常常关心的并不是“哪个模型最强”,而是:哪个 speaker 产生的 dialect,最适合当前 listener 在当前任务和预算下使用?
MDia 的阶段性结果显示,在八个 benchmark columns 上,MDia 相比最强 token-reduction baseline 宏平均准确率提升约 3.6%,相比 Raw CoT 提升约 3.1%,同时平均减少约 71% 的生成 completion tokens。更重要的是,MDia 并不把所有 dialect 无条件 ensemble,而是通过 profile-aware routing 识别 publicness、openness、resistance、teaching advantage 和 foreign-dialect risk。
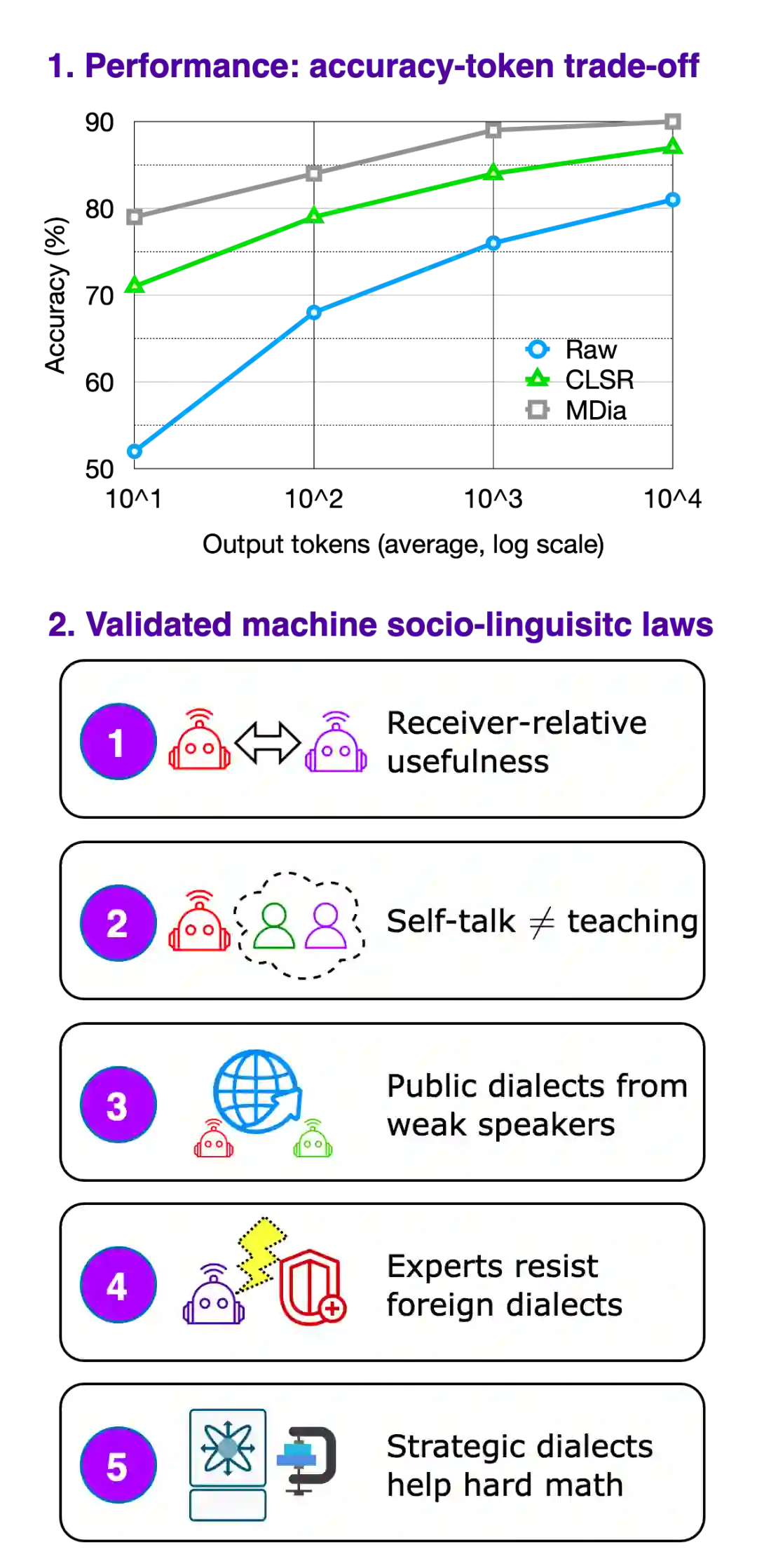
一个特别有启发性的实验是 listener replacement:固定 dialect archive,替换 listener,比较 self-dialect routing、name-based routing、profile-calibrated routing 等策略。MDia 稿件中 profile-calibrated routing 的加权准确率从 self-dialect routing 的 69.6% 提升到 83.6%,平均生成 tokens 从 879 降到 449。这说明强 dialect 并不一定是“自言自语”最强,而可能是“对别人最有教学性”。 MDia 的 rule bank 进一步抽象出一组 machine-sociolinguistic regularities,例如:
-
listener openness asymmetry:不同 listener 对外来 dialect 的开放程度不同;
-
public dialect asymmetry:某些 speaker 产生的 dialect 更容易被其他模型采用;
-
weak-speaker teaching:较弱 speaker 有时能产生更稳定、更公共的教学方言;
-
foreign-dialect risk:外来 dialect 可能因过度压缩或格式不匹配而损害强 listener;
-
route simplicity:当 archive 候选高方差时,简单 profile-aware routing 可能优于过度组合。
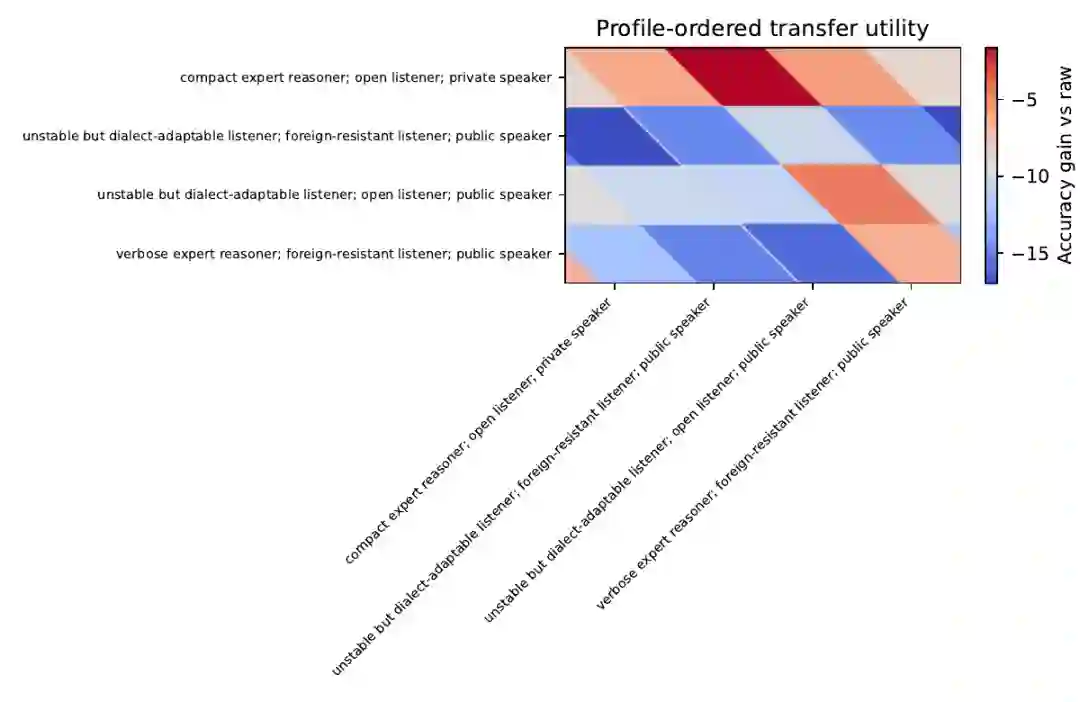
这使得 MDia 从“token compression”走向了“machine sociolinguistics”:研究机器之间如何发明、教学、借用、抵抗、迁移和路由符号协议。
13. 成果应用:Principia 与 principle-first idea discovery
CLSR/MDia 的一个重要应用方向是科研创意发现系统 Principia。Principia 的设计哲学不是直接让模型生成一个看似新颖的 proposal,而是把研究创意拆成可追踪、可验证、可复用的结构化对象。 一个简化流程如下: research goal → relevant works → existed ideas → reusable principles → takeaway messages → evidence composition → symbolic derivation → Idea Card → comparison, validation, and export` 传统 brainstorming 工具往往产生流畅文本,但很难回答:这个 idea 来自哪些文献?依赖哪些原则?假设是什么?与已有工作差异在哪里?风险在哪里?如何验证?Principia 试图把这些环节显式化,使 idea discovery 从一次性生成变成一个带有 lineage、evidence、assumption、risk 和 validation path 的工作流。 CLSR/MDia 在这里可以作为推理协议层。具体来说,它们可能在三个层面帮助 principle-first discovery: 第一,减少冗余自然语言推理。 许多科研探索流程需要反复比较文献、抽取机制、组合原则、生成假设。如果每一步都展开成长自然语言,token 预算很快被解释性文本占满。LSF/MDia 可以把部分中间状态压缩成 symbolic handles、derivation patches 和 verifier checks。 第二,提高中间对象的可复用性。 科研 idea 的关键往往不是一次性的答案,更重要的其实是可复用的 principles、operators、failure modes 和 validation templates。机器方言可以把这些对象组织成可路由、可组合的协议,而不只是散落在上下文中的自然语言片段。 第三,使小型开源模型在受控工作流中更有效。 更好的 token 利用率并不会让小模型普遍等价于大型闭源模型,但在结构清晰、协议明确、证据可追踪的科研辅助环节中,它可能显著提高小模型的有效工作半径。也就是说,能力提升不仅来自模型规模,也来自推理过程的组织方式。 从这个角度看,Principia 可以被理解为 CLSR/MDia 思想的一个应用场景:让 LLM 不仅可以回答问题,还可以发展可复用的符号语言,用于组织原则、压缩推理、追踪证据、路由验证,并最终形成更可检验的研究假设。
14. 边界与开放问题:为什么这条路线仍需谨慎推进
为了避免过度解读,有必要明确 CLSR/MDia 当前的边界。 第一,LSF 不是完全脱离人类先验的新语言。 LLM 预训练已经吸收了自然语言、数学符号、代码格式和领域缩写。CLSR 的贡献不是证明模型从零发明了语言,而是证明在给定模型先验下,可以通过正确性与 token 成本选择出更适合机器推理的操作协议。 第二,紧凑 trace 不等于可靠解释。 LSF trace 可能更结构化,但不一定能直接解释模型内部因果机制。高风险场景中不能把短 trace 当作充分解释,仍需保留自然语言解释、路由记录、验证日志和可回放的协议卡。 第三,跨模型迁移并非总是正向。 MDia 的 foreign-dialect risk 说明,外来 dialect 可能压制强 listener 原本丰富的推理过程,或引入不适合任务的格式约束。因此,机器方言需要 profile-aware routing,而不是无条件共享。 第四,程序执行与形式系统仍然不可替代。 对需要精确计算、长程符号执行或形式证明的任务,外部工具与 formal verifier 仍有不可替代的优势。CLSR 更像是拓宽了中间表示空间,而不是终结程序化推理。 第五,模型版本变化会影响 dialect 稳定性。 如果 LLM 的 tokenizer、指令跟随方式或解码偏好发生变化,旧 LSF 的有效性可能下降。未来需要研究 dialect 的版本化、回归测试、漂移检测与安全审计。 这些边界并不削弱 CLSR 的意义。相反,它们让研究问题更清楚:我们真正需要的是一套可测量、可审计、可演化的机器通信协议,而不是把压缩 trace 神秘化。
15. 小结:让模型少说,不如让模型自主演化出更合适的语言组织状态
CLSR 的重要性不在于提出了一个更短的 prompt,而在于重新定义了 LLM 推理系统中的中间表示。 过去,我们经常把 CoT 看作模型推理能力的外显形式:写得越详细,似乎就越会推理。CLSR 说明,这个判断至少是不完整的。自然语言 CoT 的确有助于人类理解和模型分步推理,但它并不是机器推理的唯一可行介质,也未必是 token-efficient 的介质。 CLSR 把问题从:如何让模型生成更短的 CoT? 推进到:如何让模型发展出更高信息密度、可复用、可路由、可传播的推理语言? 它给出的答案是:让 LLM agent 自主生成 LSF,通过正确性与 token 成本进行演化选择,再在测试时根据问题路由、集成或组合这些 LSF。MDia 进一步把这一思想扩展到异构 LLM 社会,研究不同模型之间的 dialect transfer、publicness、openness、resistance 和 route policy。Principia 则尝试把这一路线放入科研创意发现系统中,让 symbolic protocols 成为原则抽取、证据组合和 idea derivation 的基础设施。 如果说 CoT 时代让我们看到“模型可以把思考写出来”,那么 CLSR/MDia 试图说明下一步可能是:高效推理系统不一定要求模型始终用人类自然语言思考;它们可以发展面向机器的符号方言,并在需要时把这些方言翻译给人类。
这表明,我们可以把 token efficiency 从工程优化提升为表示学习与机器通信问题,也让我们重新思考:当模型越来越多地与模型协作时,真正重要的是它们能否用最合适的语言传递最关键的状态,而非它们是否足够拟人。
参考链接
- CLSR 论文ICML官方链接:https://icml.cc/virtual/2026/poster/61557
- CLSR / MDia 代码与资料:https://github.com/pzqpzq/LSF_MDia
- Principia 应用原型:https://github.com/pzqpzq/Principia