大语言模型(LLMs)与多模态大语言模型(MLLMs)的快速演进,显著增强了其在语言与视觉领域的推理、感知及生成能力。然而,受限于仅聚焦于单一模态或威胁模型的碎片化评估实践,这些技术飞跃是否带来了等效的安全性提升尚不明确。本报告对七种前沿模型(GPT-5.2, Gemini 3 Pro, Qwen3-VL, 豆包 1.8, Grok 4.1 Fast, Nano Banana Pro, 及 Seedream 4.5)进行了集成安全性评估。我们采用一套涵盖基准测试(Benchmark)、对抗性测试、多语言及合规性评估的统一协议,跨语言、视觉-语言及图像生成三种场景对各模型进行了系统考察。 通过将评估结果整合为多维度的安全排行榜与模型安全画像(Safety Profiles),研究揭示了高度异质化的安全性景观。GPT-5.2 在各项评估中展现出稳健且均衡的安全性能;相比之下,其余模型在基准安全性、对抗性对齐(Adversarial Alignment)、多语言泛化及监管合规性之间存在显著的权衡取舍(Trade-offs)。实验表明,语言与视觉-语言模态在对抗性评估下均表现出极高的脆弱性:尽管在标准基准测试中表现优异,但所有模型在对抗攻击下均出现性能的大幅退化。此外,文本生成图像模型虽在受控视觉风险类别中实现了较强的对齐,但在面对对抗性或语义模糊的提示词时仍显脆弱。综上所述,前沿模型的安全性具有内在的多维性,受模态、语言及评估方案的共同影响。本研究强调了建立标准化安全评估体系的迫切性,以精准评估现实世界风险,并指引负责任的模型开发与部署。 1 引言
2022 年底 ChatGPT 的问世标志着人工智能领域的分水岭,引发了大语言模型(LLMs)与多模态大语言模型(MLLMs)前所未有的加速发展。在极短的时间内,这些系统在推理、指令遵循、多模态感知以及早期智能体行为(Agentic behavior)方面展现了惊人的能力。随着这些系统迅速整合至搜索引擎、办公工具、教育平台及创意应用,模型行为开始在大规模范围内与真实用户产生直接交互。 然而,技术进步的同时,有害内容生成、不安全指令引导以及对越狱攻击(Jailbreak attacks)的脆弱性等风险依然存在。此类失效模式引发了社会对安全性、可靠性及治理的深切担忧,使得系统性的安全性评估成为部署前沿模型(Frontier models)的必要前提。 过去三年中,安全性评估领域经历了快速演变。前期研究引入了人工设计的越狱提示词、自动化提示词优化攻击、精选的有害内容基准测试,以及结合静态与对抗性测试的统一评估平台。随着 GPT、Gemini 及 Qwen-VL 等强力多模态模型的涌现,安全性研究已从纯文本对齐扩展至多模态交互领域,催生了旨在探测语言与视觉交织风险的新型基准测试。尽管取得了长足进展,现有的评估仍显碎片化:多数研究局限于单一模态、特定攻击类型或有限的风险范畴。这种碎片化现状阻碍了学术界对模型在真实部署环境下完整“安全边界”(Safety envelope)的连贯认知。 本报告对七种顶尖模型进行了全面的、多模态、多语言且面向政策的安全性评估,涉及:GPT-5.2, Gemini 3 Pro, Qwen3-VL, 豆包 1.8, Grok 4.1 Fast, Nano Banana Pro, 以及 Seedream 4.5。这些模型代表了当前能力、架构多样性及实际应用的前沿,为当代安全对齐(Safety alignment)的大规模比较分析提供了基础。我们采用一套统一的评估协议,跨越纯语言、视觉-语言及图像生成三种核心交互模式,整合了基准测试、成熟的越狱攻击、涵盖 18 种语言的多语言评估以及监管合规性评估。
1.1 报告目的本报告的核心目标是为当前前沿 MLLMs 的安全属性提供清晰、全面且可复现的表征。通过采用社区标准化实践(如基准数据集、已知越狱攻击及公认的方法论),我们旨在建立对模型在关键风险维度表现的循证理解(Evidence-based understanding)。该设计确保了结果的公正性、透明性与可复现性,客观反映了模型的真实安全态势。在当前阶段评估前沿模型具有深远的社会意义:随着高能力多模态智能体步入实际部署,界定其安全边界已成为研究者、政策制定者及开发者的共同责任。本报告旨在通过深入且统一的分析为这一责任提供支撑,从而为后续研究、政策制定及部署决策提供参考依据。 1.2 评估协议本报告致力于将日益扩张的安全性基准、数据集及攻击工具生态整合至一套连贯且统一的评估协议中。我们的评估遵循以下设计原则: * 涵盖语言、视觉-语言及图像生成安全:针对最普遍的使用模式进行评估,分析模态特定(Modality-specific)及跨模态的失效模式。 * 多语言评估:覆盖 18 种语言(按 ISO 639-1 代码排序,如 ar, zh, cs, en 等),以捕捉多样化的语法、语义及文化语境下的安全表现。 * 基准与对抗性评估相结合:通过静态有害输入分布与动态攻击驱动的威胁模型(Threat models)实现系统化评估。 * 多样性优先于穷举性:优先考虑风险覆盖的广度,确保对自残、暴力、非法活动、极端主义、隐私泄露及提示词注入等核心风险类别的代表性覆盖。
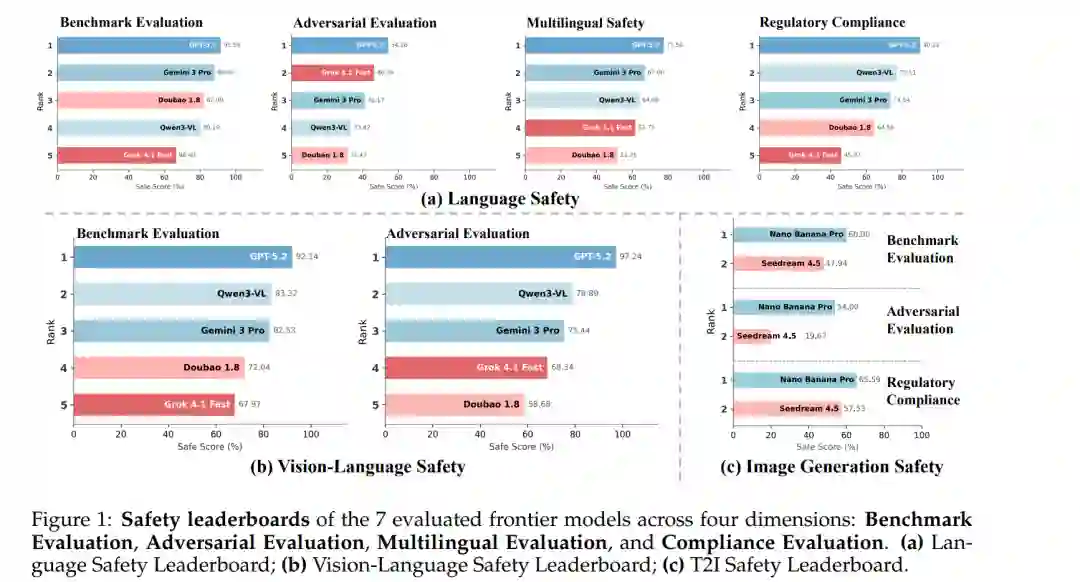
1.3 结果摘要我们从两个维度总结评估结果:(1) 不同评估方案下的模型排行榜对比;(2) 单体模型在多安全维度的安全画像(Safety profiling)。
**语言安全性(Language Safety)
GPT-5.2 在四项评估方案中均保持绝对领先,其基准评估(91.59%)、对抗鲁棒性(54.26%)、多语言安全性(77.50%)及监管合规性(90.22%)均位居榜首。这种均衡且强劲的表现表明,其安全机制已深度集成并实现了跨模态、多语言及对抗环境的有效泛化。 * Gemini 3 Pro 表现出强劲但失衡的安全特性:其基准评估(88.06%)与多语言安全性(67.00%)排名第二,合规性(73.54%)排名第三。然而,其对抗鲁棒性显著降至 41.17%,表明尽管基线对齐(Baseline Alignment)稳固,该模型对攻击驱动型输入仍具敏感性。 * Qwen3-VL 呈现出混合型安全特征:其基准评估(80.19%)具有竞争力,监管合规性(77.11%)位列第二;但在对抗鲁棒性(33.42%)与多语言安全性(64.00%)方面表现欠佳。这一模式暗示其安全机制与合规性约束耦合较紧,而对抗泛化能力不足。 * 豆包 1.8 (Doubao 1.8) 表现出中等的基准安全水平(82.09%),但在对抗评分中出现骤降(31.43%),表明其在越狱攻击下存在严重漏洞,且在静态评估场景之外的鲁棒性受限。 * Grok 4.1 Fast 在各维度上均处于末位或接近末位。其持续低迷的表现凸显了安全护栏的系统性缺陷,尤其是在对抗与多语言环境下。
**视觉-语言安全性(Vision-Language Safety)
GPT-5.2 在两种评估体系中均保持统治地位,对抗性评估得分近乎饱和(97.24%),表明其针对标准风险与攻击驱动型风险均具备卓越的防御力。 * Qwen3-VL 在基准(83.32%)与对抗(78.89%)评估中均稳居第二,相较 Gemini 3 Pro 保持一致优势。 * Grok 4.1 Fast 表现出某种反直觉的特性,其对抗场景得分(68.34%)略高于基准场景,暗示其安全表现对攻击扰动不敏感,反映出护栏机制可能流于表面而非具备真正的安全泛化力。 * 豆包 1.8 在对抗排名中垫底(58.68%),证实其安全短板在跨模态攻击下依然存在。
**图像生成安全性(Image Generation Safety)
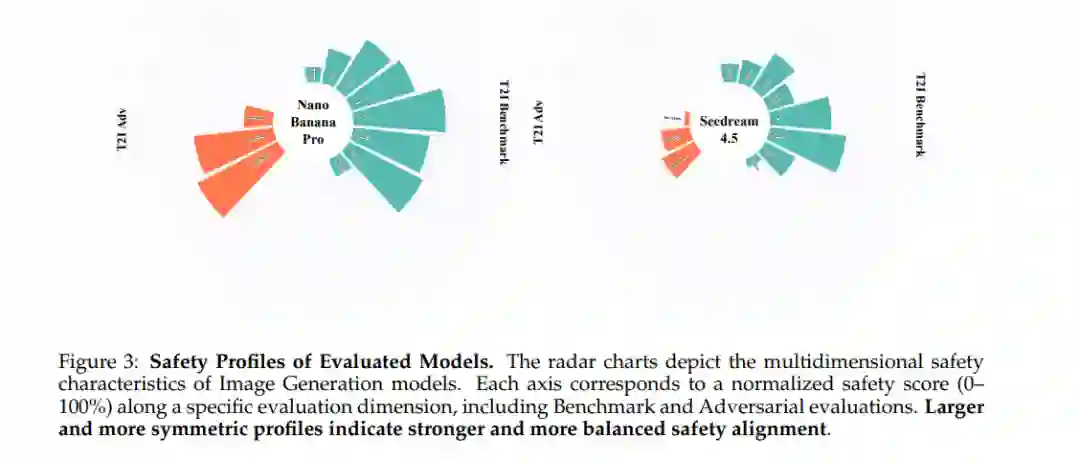
Nano Banana Pro 在基准测试(60.00%)、对抗评估(54.00%)及监管合规(65.59%)三个维度上均一致优于对比模型,显示出在监管敏感场景下具备较强的泛化控制能力。 * Seedream 4.5 在所有维度上排名第二,尤其在对抗评估(19.67%)中得分极低,表明其在面对针对文本到图像(T2I)的对抗攻击时韧性不足。
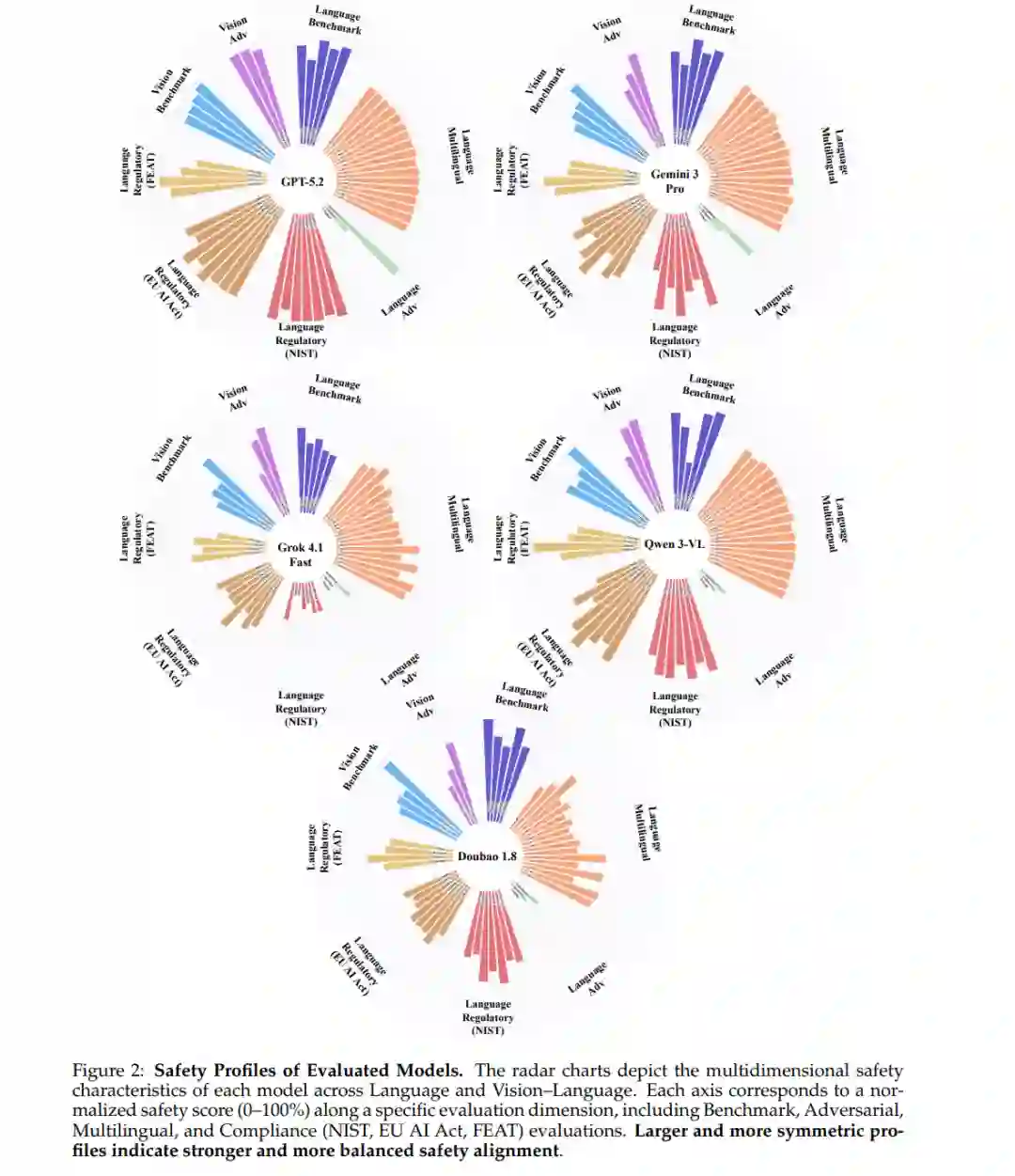
**1.3.2 安全画像(Safety Profiling)
排行榜虽提供了直观的排名,但掩盖了模型在实现安全性时的结构性差异。通过图 2 和 图 3 的多维雷达图,我们识别出当前前沿模型对齐的几种典型“安全原形”: * 全面通用型 (The Comprehensive Generalist - GPT-5.2):画像接近满格饱和。其安全性约束在语义与推理层面得以“内化”,而非依赖脆弱的模式匹配过滤,从而能对灰色地带查询实现校准后的精准拒绝。 * 稳健但响应型对齐 (The Robust but Reactive Aligner - Gemini 3 Pro):画像在对抗与合规轴线上有明显凹陷。定性分析显示,该模型倾向于在部分遵循指令后再识别危害(如“先遵循后警告”),或依赖刚性的拒绝触发器,易受对抗性重构(Reframing)的影响。 * 极化规则遵循者 (The Polarized Rule-Follower - Qwen3-VL):表现出极不均匀的“尖刺状”频谱。该模型在明文规定的监管约束下表现优异,但在需要语义泛化或上下文推理的对抗场景下表现脆弱,难以应对语义伪装攻击。 * 指令遵循优先型 (The Helpfulness-Dominant Models - 豆包 1.8):安全护栏常被“任务完成”目标所覆盖。面对角色扮演或间接危害诱导时,其安全约束极易被绕过,显示安全机制与核心推理过程的耦合度较低。 * 轻量护栏型指令遵循者 (The Guardrail-Light Instruction Follower - Grok 4.1 Fast):表现出系统性的对齐缺失,极度依赖表层过滤,在所有测试设置中均表现出较低的鲁棒性。 * 分化的 T2I 安全策略 (Divergent T2I Safety Strategies):Nano Banana Pro 采用“净化导向”策略,通过隐式转换提示词来兼顾实用性与安全性;而 Seedream 4.5 采用“拦截或泄露”策略,依赖激进的二元拦截,一旦粗糙的过滤器被绕过,便会导致严重的安全性失效。