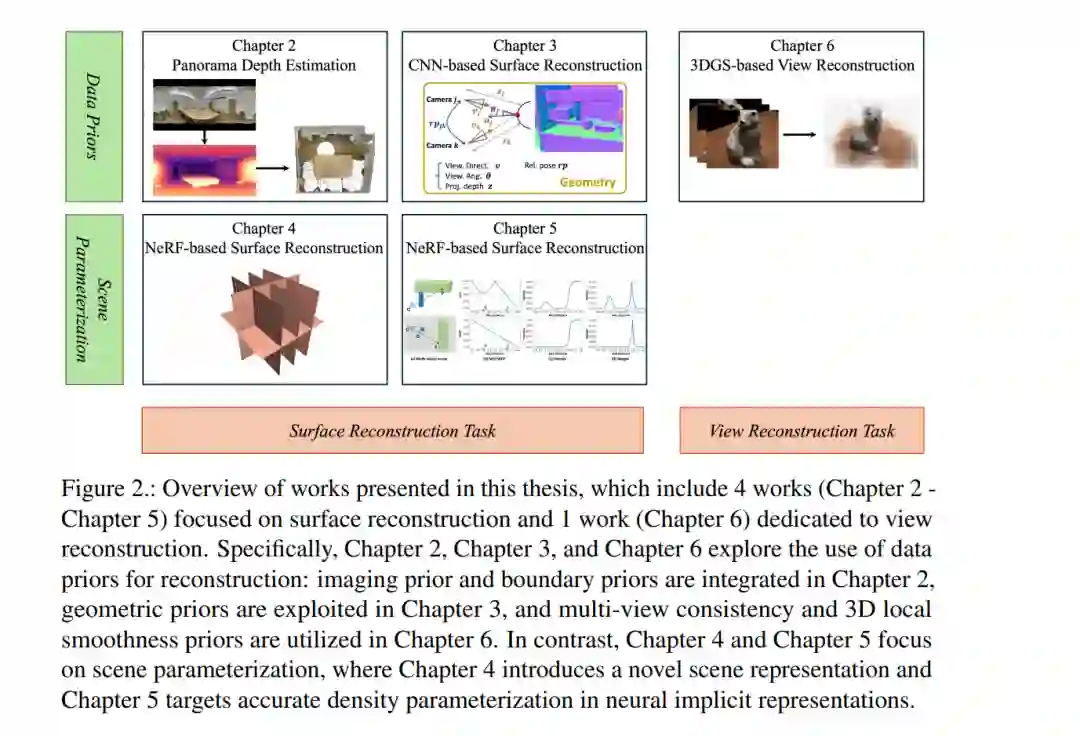
三维场景重建是三维计算机视觉领域的一个基础且关键的研究课题,在混合现实(MR)/ 增强现实(AR)、自主导航及机器人学等领域具有广泛的应用前景。本学位论文致力于分析并开发基于学习的算法,旨在提升三维室内重建的性能表现。具体而言,本文针对多种重建方法中的两大核心挑战展开研究:即数据先验的利用与场景参数化的设计,力求实现更高的重建质量与更强的泛化能力。 在具体章节安排上,第 2、3 及 6 章探讨了多种数据先验在重建任务中的整合:第 2 章融合了成像先验(Imaging Prior)与边界先验;第 3 章挖掘并利用了几何先验;第 6 章则应用了多视图一致性及三维局部平滑先验。与之相对应,第 4 及 5 章侧重于场景参数化的研究:第 4 章提出了一种新颖的场景表示方法,第 5 章则聚焦于神经隐式表示(Neural Implicit Representations)中精确的密度参数化建模。
RGB 图像作为计算机视觉中最基础且广泛使用的视觉模态,不仅包含丰富的信息,而且用户通过智能手机等成像设备即可轻松获取。然而,RGB 图像缺乏深度、几何结构以及物体间相对位置等显式空间信息。相比之下,三维视觉(3D vision)使机器能够感知环境中的结构、形状和空间关系,这对于自动驾驶、具身智能以及增强/虚拟/混合现实(AR/V R/MR)等广泛任务至关重要。通过捕捉深度维度,三维视觉弥合了图像感知与现实世界理解之间的鸿沟,成为开发智能自主系统的关键组件。 三维室内场景是我们日常环境的基础组成部分,涵盖了居住和工作场所。因此,针对这些环境设计的智能系统在提高生活质量方面具有巨大潜力。这类系统的一个核心需求是能够准确感知和理解三维室内空间。然而,由于室内环境固有的复杂性——如遮挡、多变的光照条件以及小型或无纹理物体的存在——这给场景理解任务带来了严峻挑战。因此,开发能够应对这些挑战并推动室内场景理解发展的鲁棒高效算法至关重要。 利用 RGB 图像进行三维室内理解,为昂贵的深度传感器提供了一种高性价比且易于获取的替代方案,使其非常适合大规模和现实世界的应用。此外,来自不同视角的视角图像符合生物视觉机制,并自然地结合了多视图几何原理。通过利用多个视角之间的几何关系,准确理解场景的三维结构变得切实可行。 实现这一目标(即从多视图 RGB 输入中理解场景)的关键第一步是三维场景重建,它是三维语义分割、目标检测和空间推理等下游任务的基础。重建通常指从二维图像中恢复空间和视觉信息的过程。如 [图 1] 所示,该过程可分为两类:表面重建 [130] 和视角重建 [85]。表面重建侧重于恢复场景潜在的三维几何结构,其形式可以是深度图、点云、网格(Mesh)或体素网格(Voxel grids)。通过获取场景的显式表示,表面重建提供了对环境具有物理基础的理解。相比之下,视角重建(亦称新视角合成)旨在利用若干观测图像的先验,生成未知视角下的场景二维 RGB 图像。该任务强调外观理解和不同视角间的视觉一致性,而非表面重建中的显式几何恢复。 尽管三维重建领域已取得显著进展,涵盖了传统场景重建方法 [8, 111, 123, 130, 144, 162, 163, 167] 和神经场景表示 [13, 44, 45, 80, 143, 145, 150, 175, 177, 188],但现有方法仍面临若干局限性 [8, 130, 143, 177]: * 数据先验(Data Priors):室内重建中的成像先验和场景几何利用仍不充分。这包括全景成像先验 [129]、二维深度与表面法线线索 [5]、三维遮挡约束 [130]、多视图对应信息 [36] 等。 * 场景参数化(Scene Parameterization):需要更有效的场景表示和建模策略。例如,三平面(Tri-plane)表示 [9] 在处理复杂室内环境时往往过于简化,而神经隐式表面建模 [177] 在应用于多物体室内重建时存在劣势。
基于上述洞察,本论文重点解决基于多视图 RGB 的室内重建中的上述问题,通过利用不同视角的互补信息和改进场景表示,来提高几何与外观的准确性。具体而言,第 2、3 和 6 章旨在探索数据先验对三维室内重建的贡献,而第 4 和 5 章则提出了新的三维室内重建场景参数化方法。此外,本论文还针对不同的应用场景,研究了几种具有代表性的基于学习的重建范式,即 三维卷积神经网络 (3D CNNs) [133]、神经辐射场 (NeRF) [85] 以及 3D 高斯泼溅 (3DGS) [61]。