
导读
人工智能在科学发现领域的应用日益深入,从蛋白质结构预测到新材料设计,AI正在深刻改变科学研究的进程。然而,一个更根本的问题随之浮现:AI系统能否像人类科学家一样,在时间约束下预测科学进步的轨迹?它能够判断一个科学突破是否会发生、何时发生、以及如何实现吗?带着这些疑问,来自牛津大学、斯坦福大学、华盛顿大学、艾伦人工智能研究所等机构的联合团队(Sean Wu、Pan Lu、Yupeng Chen、Jonathan Bragg、Yutaro Yamada、Peter Clark、David Clifton、Philip Torr、James Zou、Junchi Yu)提出了一项系统性的评估框架——CUSP(Cutoff-conditioned Unseen Scientific Progress)。
这篇论文的核心贡献在于,它首次在受控的时间知识约束下,对前沿AI模型进行了大规模、多学科的“科学预测”能力评估。与现有的科学推理或问题解决评测不同,CUSP直面一个痛点:当前我们并不清楚AI到底能在多大程度上“预见”尚未发生的科学进展。它既不是考察模型对已有知识的检索,也不是测试其解决已知问题,而是要检验其能否基于一个时间点前的所有信息,对未来发生的科学事件进行判断和预测。
CUSP基准包含了来自Nature、Science、Cell等顶级期刊及社区驱动资源的4760个可验证科学里程碑。通过巧妙的“时间胶囊”设计,CUSP能够区分模型在训练截止日前后的事件上的表现,从而剥离出预测能力与知识回忆的差异。评估覆盖了4个维度:可行性评估、机制推理、生成方案设计、时间预测。研究发现,即使是最前沿的模型,在判断科学进展是否实现以及何时实现方面,也表现出了系统性且领域依赖的局限性。这篇文章值得所有关心AI能力边界、科学发现机制以及AI评估方法论的研究者和从业者认真研读。
论文基本信息
英文题目 Forecasting Scientific Progress with Artificial Intelligence 作者 Sean Wu, Pan Lu, Yupeng Chen, Jonathan Bragg, Yutaro Yamada, Peter Clark, David Clifton, Philip Torr, James Zou, Junchi Yu arXiv ID 2605.22681 类别 cs.AI Comments/接收信息 73 pages, 13 figures, 29 tables 原文链接 https://arxiv.org/abs/2605.22681
摘要
本文旨在回答一个核心问题:当前AI系统是否能够预见科学进步的轨迹?为了系统性地研究这一问题,作者引入了一个在受控知识约束下预测科学进步的时间性评估框架。他们提出了CUSP,这是一个多学科、事件级的基准,用于评估AI系统在四个维度上的科学预测能力:可行性评估(能否判断科学进展是否会发生)、机制推理(能否识别背后的技术路径)、生成方案设计(能否生成与实际发现吻合的方法)以及时间预测(能否预测进展发生的时间)。在4760个科学事件上,研究观察到了当前前沿模型存在系统性和领域依赖的局限性。
研究的关键发现包括:
- 模型能够从竞争性候选方案中识别出合理的研究方向,但无法可靠地判断科学进展是否会被实现。
- 模型系统性地错误估计了科学事件发生的时间,通常倾向于预测比实际更晚的时间。
- 性能在不同科学领域之间高度异质:AI领域的时间预测比生物、化学和物理领域更可预测。
- 模型在训练截止日之前和之后的事件上的表现差异不大,这表明其局限性不能仅由训练数据中知识暴露的程度来解释。
- 在受控信息访问实验下,模型通过获得更多截止日前的知识能够提升性能,但这仍然无法弥合与完全信息设置(即获得事后知识)之间的差距,特别是对于高引用的科学进展,这一差距更为显著。
- 模型表现出系统性的过度自信和强烈的响应偏差,这表明其不确定性估计在科学预测任务上不可靠。
综上所述,当前AI系统作为科学进步的预测工具仍然力不从心。知识访问并未转化为可靠的预测能力,模型更多地从事后信息中获益,而非前瞻性的预测。
引言:论文要解决什么问题
科学进步常常被认为遵循某种结构化的模式,例如半导体领域的摩尔定律和深度学习中的标度律。这些来自经验的规律长期以来为研究路线图、资金优先事项和技术预测提供了依据。随着AI在生物、化学、物理以及AI自身领域科学发现中的深度融入,一个根本性的问题浮现出来:AI系统能否预测科学进步的轨迹? 以往的研究大量评估了AI作为通用科学助手的能力,例如在假设生成、实验设计、科学推理、问题解决以及影响力预测等方面。这些研究确实证明了AI的广泛适用性,但没有一项评估涉及AI系统在时间知识约束下对科学进步进行可靠预测的能力。评估这种能力本身就具有挑战性:预测必须立足于具体的、可验证的科学事件,同时还要防止模型接触到事件发生后产生的信息。
这一空白正是CUSP所针对的核心痛点。论文要解决的关键问题是:当前AI系统是否有能力预见科学进步的轨迹?它们在科学预测方面的真实能力和本质局限是什么?为此,作者构建了一个新型的评估框架,旨在分离知识的记忆与知识的前瞻性运用,从而刻画模型在“预测未来”而不是“回忆过去”时的真实水平。
方法:核心思路与技术路线
CUSP的核心方法论具有两个显著特点:一是通过“时间胶囊”设计实现受控的知识约束;二是通过四种互补的任务类型全面评估预测能力的各个维度。
CUSP基准构建
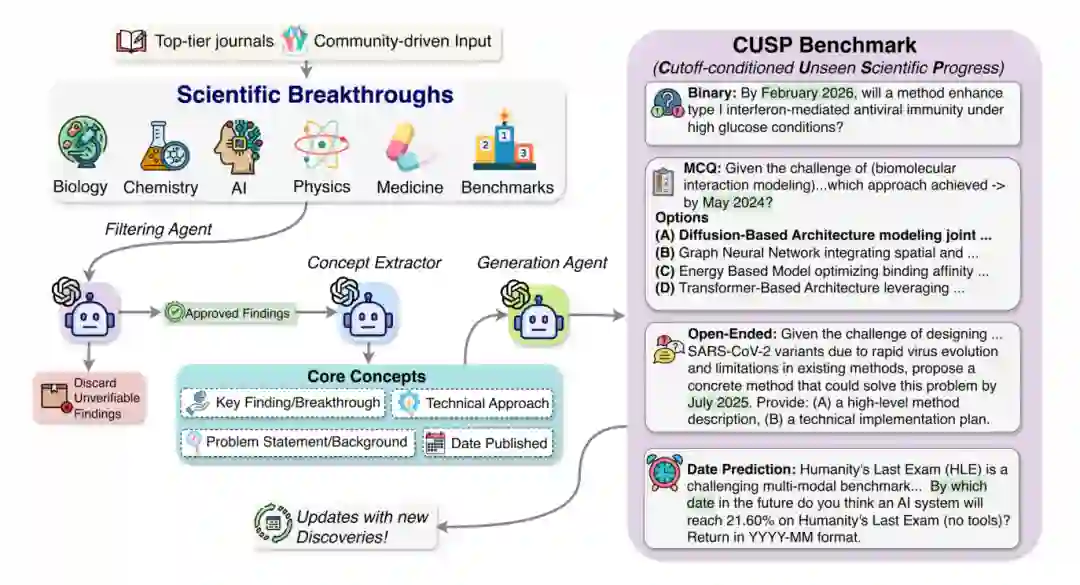
图1:CUSP基准构建流程。系统从顶级期刊与社区资源汇聚科学突破,经筛选、概念抽取和任务生成后形成二元判断、多选、自由回答与日期预测四类任务,并可随新发现持续更新。 CUSP基准基于一个时间分层的科学里程碑语料库构建,时间跨度从2024年1月到2026年3月。所有纳入的里程碑都是可验证的、确定性的科学进展。 数据来源严格来自于顶级期刊:自然科学方面,从Nature、Science、Cell中提取高影响力的同行评审出版物。为了确定事件的时间边界,避免时间泄露,论文查询了Crossref、Semantic Scholar、OpenAlex、Europe PMC、arXiv和bioRxiv/medRxiv等多个数据源,并采用每个稿件DOI对应的最早观察日期作为相关知识的边界日。对于人工智能领域,则纳入了来自社区驱动资源的高可见度论文,包括每周顶刊列表、Hugging Face Top Papers中心以及广泛使用的排行榜记录。 最终,CUSP基准共包含4760个科学事件,并从中合成了17429个经过验证的评估任务。基准的一个关键特性是持续更新:随着新发表的发现不断被纳入,基准持续保持动态和时效性。 与传统科学问答、事后推理或论文影响力预测不同,CUSP的关键不是让模型复述已有结论,而是把每个事件绑定到明确的时间边界,并要求模型在“当时可知道的信息”内做预测。因此,CUSP同时考察三件事:模型是否拥有足够科学背景知识,是否能把知识外推到未来事件,以及是否能对自身不确定性保持校准。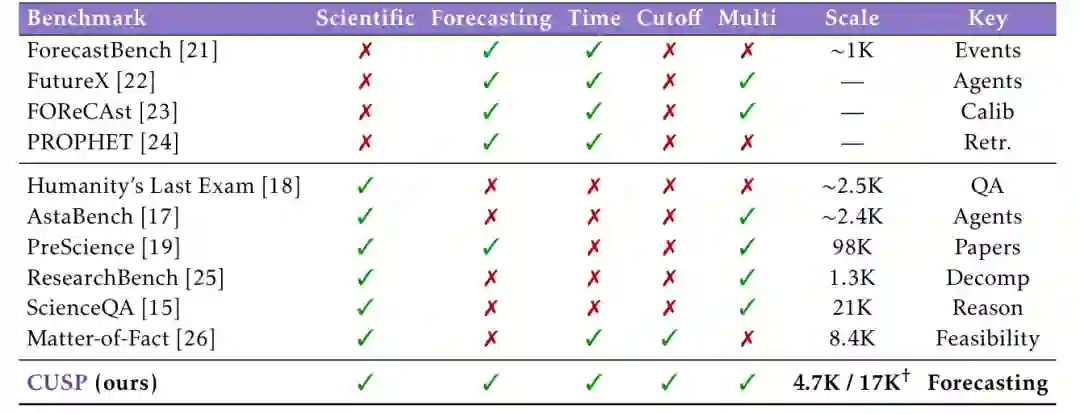
四种任务类型(评估维度)
CUSP将科学预测操作化为四个互补的可测量维度,对应四种任务类型:
- 二元可行性判断(Binary):判断一个科学声明是否会被验证为真(即科学进展是否会发生)。这是对模型基本“可行/不可行”判断力的测试。
- 多项选择(MCQ):从四个候选技术方案中选择一个最有可能实现该科学进展的方法。这测试的是模型对领域内技术趋势和实现路径的识别能力。
- 自由回答方案生成(FRQ):模型需要生成一个自由形式的解决方案,描述如何实现该科学进展。这测试的是模型生成细节、与真实方法对齐、以及提出新颖方案的能力。
- 日期预测(Date):预测科学事件发生的具体年月。这是对模型时间分辨率和预测偏差的精细化测试。
知识控制机制:“时间胶囊”设计
这是CUSP最精巧的部分。为了确保评估是在受控知识约束下进行,CUSP强制实施了时间胶囊机制:每个模型只能访问其训练截止日之前的知识。整个评估过程设计得非常严格,以确保模型不能事后访问信息。如果一个科学事件发生在某个模型的训练截止日之前(Pre-cutoff),模型理论上“知道”它;如果事件发生在截止日之后(Post-cutoff),模型必须“前瞻预测”它。通过对比模型在Pre-cutoff和Post-cutoff事件上的表现,可以专门测量预测能力,区分开“基于记忆的回忆”和“基于推理的前瞻”。
模型评估
论文评估了多种前沿模型,包括:商用模型GPT-5.4、GPT-4o和Claude Sonnet 4.5,以及开源模型LLaMA-3.3-70B-Instruct、GPT-OSS-20B和DeepSeek R1。每个模型都有明确的训练截止日期。
关键评估指标
- Binary任务 采用合并准确率(对原问题和否定反转版本取平均),用于校正方向性响应偏差,随机基线为0.50。
- MCQ任务 四选一准确率,随机基线为0.25。
- Date任务 采用指数衰减分数 ( e^{-0.1|\Delta t|} ),分数为1.0表示精确预测到月份。
- FRQ任务 包括FRQ得分(0-10评分)和FRQ通过率(得分≥5的比例)。所有FRQ评估使用自动化LLM评分器。
图2:CUSP数据统计与验证质量。4760个科学里程碑覆盖多来源、多领域和2024年1月至2026年3月的时间跨度;AI验证流程与研究生专家校准后,在多种题型上保持较高精度。
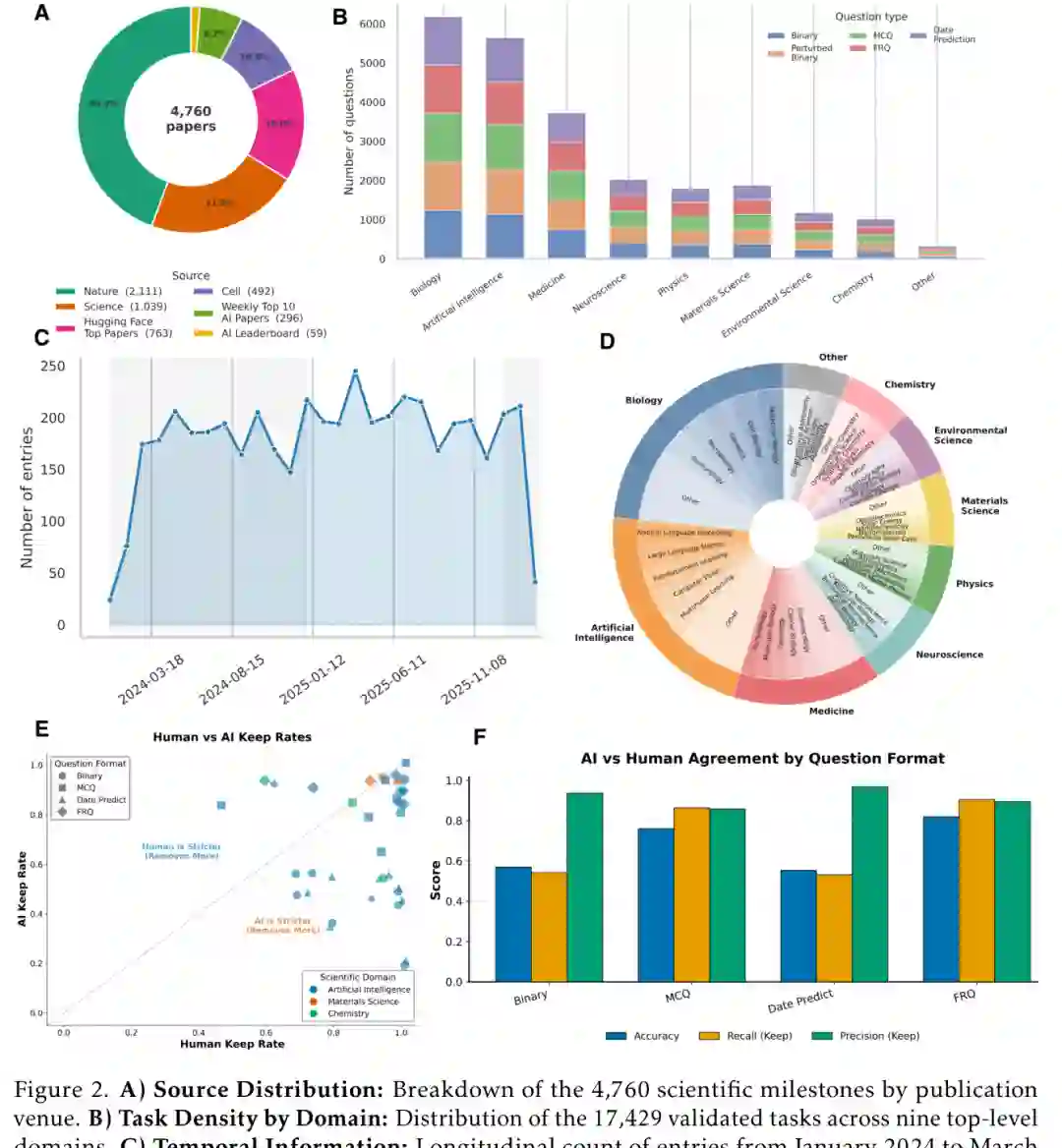 图2:CUSP数据统计与验证质量。4760个科学里程碑覆盖多来源、多领域和2024年1月至2026年3月的时间跨度;AI验证流程与研究生专家校准后,在多种题型上保持较高精度。
图2:CUSP数据统计与验证质量。4760个科学里程碑覆盖多来源、多领域和2024年1月至2026年3月的时间跨度;AI验证流程与研究生专家校准后,在多种题型上保持较高精度。实验:设置、指标与结果
整体模型性能
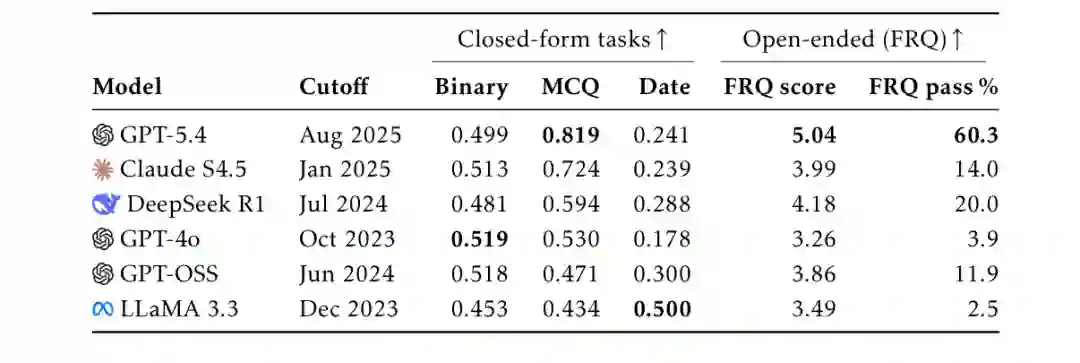
- Binary任务(基线0.50) 所有模型的准确率范围在0.453至0.519之间,基本接近随机水平。这说明模型无法可靠判断一个科学声明是否会被验证。
- MCQ任务(基线0.25) 所有模型都显著高于基线。GPT-5.4表现最强,准确率达0.819。这表明模型能识别出科学突破背后最可能的实现路径。
- Date任务(分数1.0为精确) 性能排名与其他任务不同。LLaMA 3.3最佳,得分为0.500。前沿模型如GPT-5.4和Claude S4.5反而表现更差,得分分别为0.241和0.239。
- FRQ任务 GPT-5.4表现最佳,得分为5.04,通过率60.3%。其他模型FRQ通过率均低于20%(DeepSeek R1为20.0%,Claude S4.5为14.0%),表明生成准确解决方案比从选项中选择难得多。
日期预测的深入分析
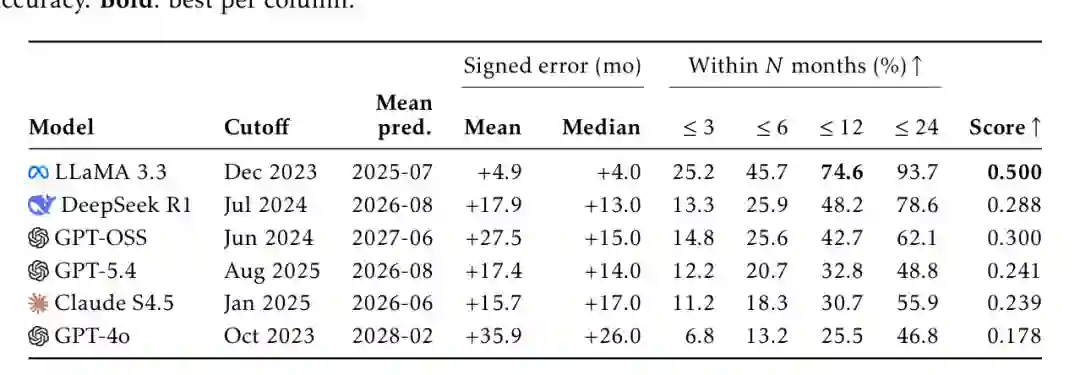
- LLaMA 3.3误差最小,中位数误差仅为+4.0个月,34.8%的预测在3个月内,45.7%在6个月内,74.6%在12个月内。
- GPT-4o偏差最大,平均预测日期偏差达+35.9个月,中位数误差+26.0个月。
- 精确月份预测率(exact match)对所有模型都极低,均低于4%。
这表明模型可以粗粒度地感知时间范围,但缺乏精细的时间分辨率。
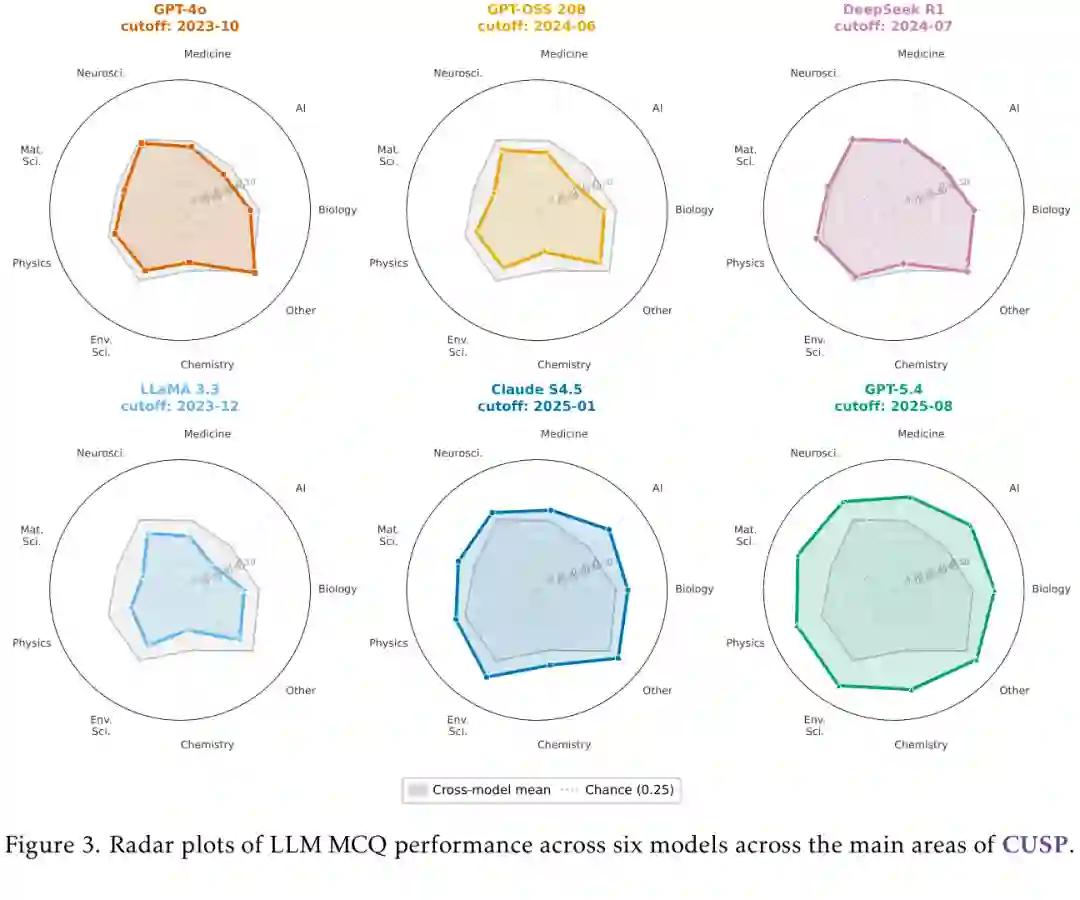
领域异质性
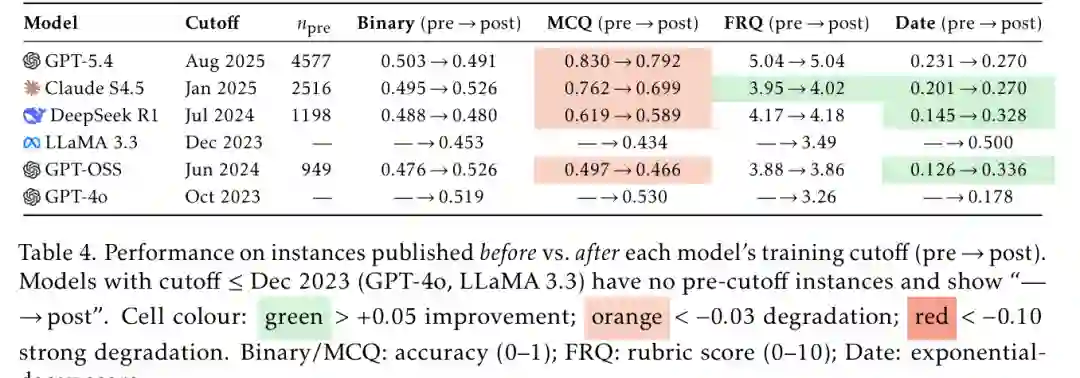
训练截止日前后性能对比
控制信息访问实验
为了进一步厘清是知识不够还是推理能力不足,论文设计了信息访问实验:向模型提供额外的、丰富的截止日前知识(例如论文的标题、摘要,甚至引用信息)。 结果发现:
- 提供额外知识确实提升了模型在Pre-cutoff和Post-cutoff事件上的性能,表明存在知识利用上的“知识鸿沟”。
- 但即使在获得更多知识后,模型在Post-cutoff事件上的性能仍然显著低于“完全信息设置”(即允许获得事后知识)。这表明存在一个难以弥合的“预测鸿沟”。
- 对于高引用的科学进展,这种预测差距更大。也就是说,最具影响力的科学发现最难被预测,即使模型有充足的知识背景。
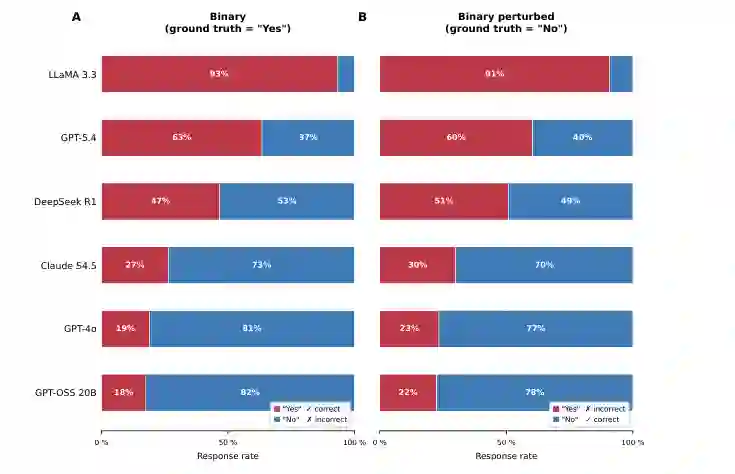
系统偏差与失效模式
结论:贡献、局限与启发
主要贡献:本文引入了CUSP,它是一个多学科、事件级、时间性的基准,用于评估AI系统在受控知识约束下预测科学进步的能力。通过系统的实验,论文揭示了当前AI系统的一个根本性局限:它们在预测科学进步是否实现、何时实现以及如何实现方面存在系统性失败。这些局限不能简单归因于知识暴露不足,它们更多反映了模型在“前瞻推理”上的脆弱性。 局限性:论文指出,当前AI系统无法形成有根据的、校准过的科学预期。它们不擅长从已知知识中推断尚未发生的事情,而更擅长在结果知晓后从事后信息中获益。不确定性估计的不可靠性(过度自信和响应偏差)是另一个严重局限。此外,领域间性能的高度异质表明,不同科学领域的预测挑战差异巨大,单一模型或方法无法普遍适用。 启发:这项研究对于AI在科学中的应用具有重要指导意义。它表明,要让AI不仅作为一个“知识检索机”或“解题助手”,而是作为一个可靠的“科学预言家”,需要超越检索的能力。未来的AI系统必须学会在不确定性下进行推理,理解科学发现如何在时间维度上展开。CUSP作为一种评估工具,为后续的工作——包括设计更好的知识表示、更精妙的预测推理机制以及更可靠的不确定性校准——提供了坚实的评估基础。它也提醒我们,即使是当前最强大的模型,在真正前瞻性的科学预测方面,距离人类智识仍有相当距离。这一领域将是下一阶段AI能力突破的关键战场之一。
原文信息
原文标题:Forecasting Scientific Progress with Artificial Intelligence 原文链接:https://arxiv.org/abs/2605.22681

