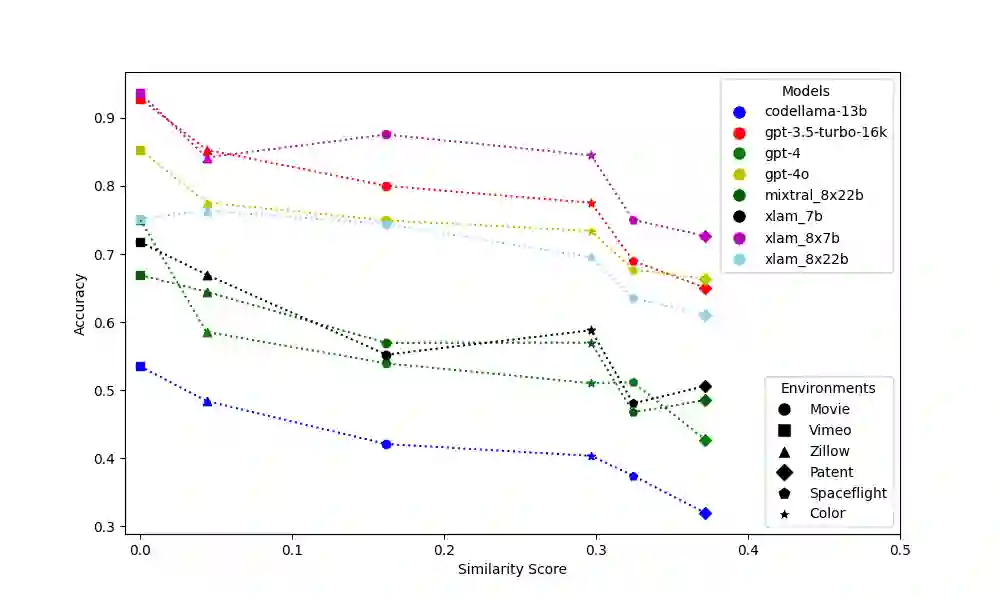
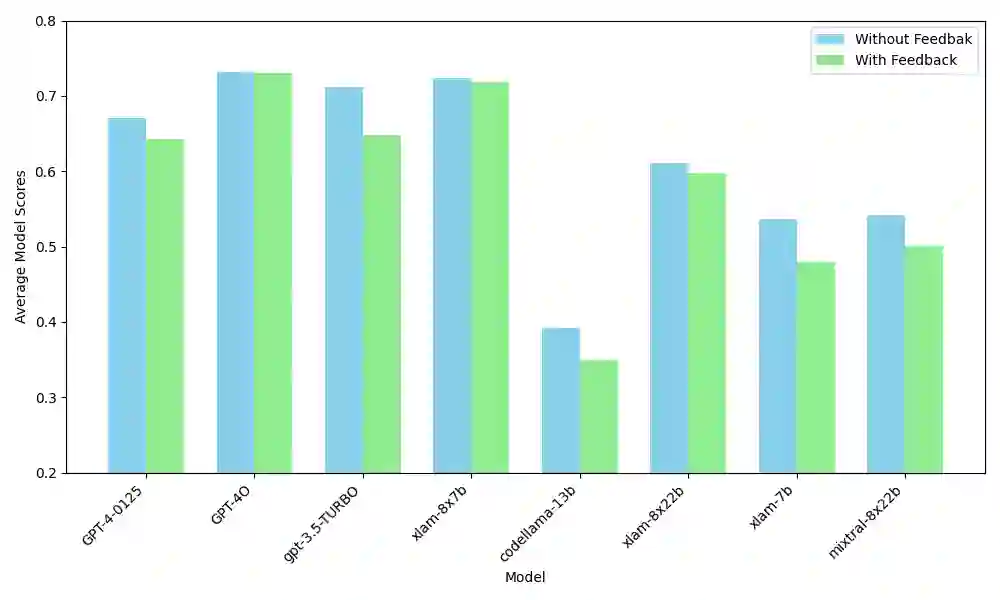
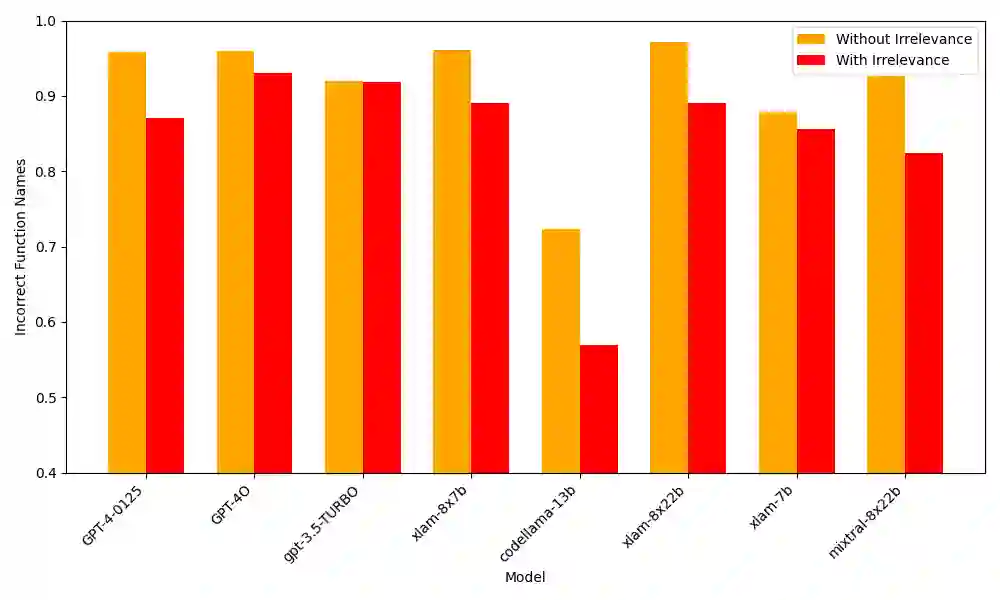
Evaluating the output of Large Language Models (LLMs) is one of the most critical aspects of building a performant compound AI system. Since the output from LLMs propagate to downstream steps, identifying LLM errors is crucial to system performance. A common task for LLMs in AI systems is tool use. While there are several benchmark environments for evaluating LLMs on this task, they typically only give a success rate without any explanation of the failure cases. To solve this problem, we introduce SpecTool, a new benchmark to identify error patterns in LLM output on tool-use tasks. Our benchmark data set comprises of queries from diverse environments that can be used to test for the presence of seven newly characterized error patterns. Using SPECTOOL , we show that even the most prominent LLMs exhibit these error patterns in their outputs. Researchers can use the analysis and insights from SPECTOOL to guide their error mitigation strategies.
翻译:评估大语言模型(LLMs)的输出是构建高性能复合人工智能系统最关键的方向之一。由于LLMs的输出会传递至下游环节,识别LLM错误对系统性能至关重要。在AI系统中,LLMs的一项常见任务是工具调用。尽管目前已有多个用于评估LLMs在此任务表现的基准环境,但它们通常仅提供成功率而缺乏对失败案例的归因分析。为解决此问题,我们提出了SpecTool——一个用于识别LLM在工具调用任务中输出错误模式的新型基准。我们的基准数据集包含来自多样化环境的查询指令,可用于检测七种新定义错误模式的存在性。通过SPECTOOL的测试,我们发现即使最先进的LLMs在其输出中仍会呈现这些错误模式。研究人员可利用SPECTOOL提供的分析与洞见来指导其错误缓解策略的制定。