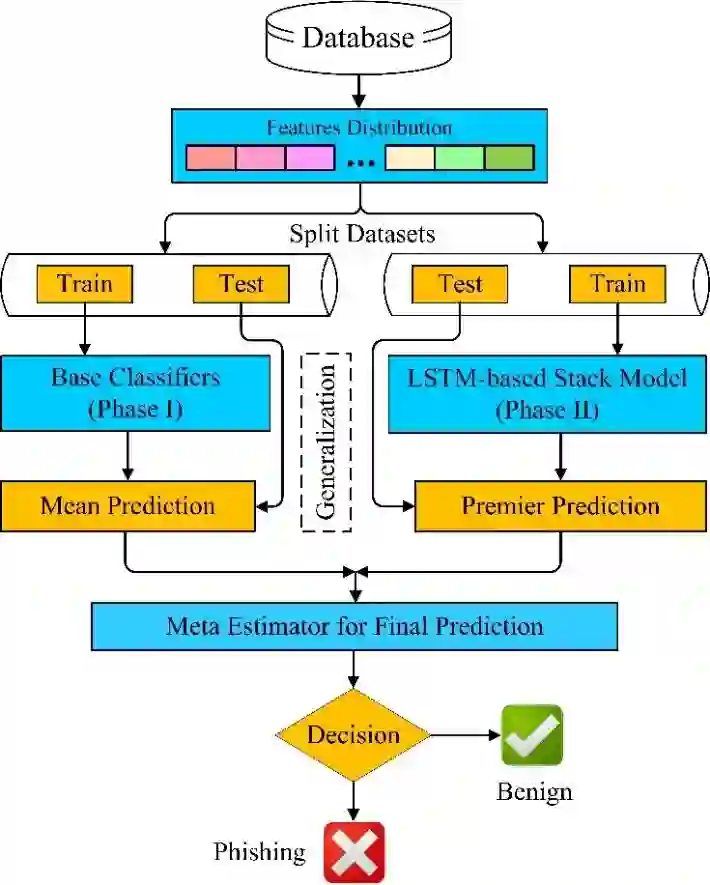
The escalating reliance on revolutionary online web services has introduced heightened security risks, with persistent challenges posed by phishing despite extensive security measures. Traditional phishing systems, reliant on machine learning and manual features, struggle with evolving tactics. Recent advances in deep learning offer promising avenues for tackling novel phishing challenges and malicious URLs. This paper introduces a two-phase stack generalized model named AntiPhishStack, designed to detect phishing sites. The model leverages the learning of URLs and character-level TF-IDF features symmetrically, enhancing its ability to combat emerging phishing threats. In Phase I, features are trained on a base machine learning classifier, employing K-fold cross-validation for robust mean prediction. Phase II employs a two-layered stacked-based LSTM network with five adaptive optimizers for dynamic compilation, ensuring premier prediction on these features. Additionally, the symmetrical predictions from both phases are optimized and integrated to train a meta-XGBoost classifier, contributing to a final robust prediction. The significance of this work lies in advancing phishing detection with AntiPhishStack, operating without prior phishing-specific feature knowledge. Experimental validation on two benchmark datasets, comprising benign and phishing or malicious URLs, demonstrates the model's exceptional performance, achieving a notable 96.04% accuracy compared to existing studies. This research adds value to the ongoing discourse on symmetry and asymmetry in information security and provides a forward-thinking solution for enhancing network security in the face of evolving cyber threats.
翻译:随着对革命性在线网络服务依赖的不断加深,安全风险日益凸显,尽管采取了广泛的安全措施,钓鱼攻击仍然构成持续挑战。依赖机器学习和人工特征的传统钓鱼检测系统难以应对不断演变的攻击手法。深度学习的最新进展为应对新型钓鱼攻击和恶意URL提供了有前景的途径。本文提出了一种名为AntiPhishStack的两阶段堆叠泛化模型,用于检测钓鱼网站。该模型对称地利用URL学习和字符级TF-IDF特征,增强了应对新兴钓鱼威胁的能力。在第一阶段,特征在基础机器学习分类器上进行训练,采用K折交叉验证实现稳健的均值预测。第二阶段采用双层堆叠LSTM网络,配备五种自适应优化器进行动态编译,确保对这些特征的优质预测。此外,两阶段的对称预测被优化并整合,用于训练元XGBoost分类器,从而形成最终的稳健预测。本工作的意义在于通过AntiPhishStack推进钓鱼检测技术,无需依赖特定的钓鱼先验特征知识。在两个基准数据集(包含良性URL和钓鱼或恶意URL)上的实验验证表明,该模型性能卓越,与现有研究相比达到了96.04%的显著准确率。这项研究为信息安全中对称性与非对称性的持续讨论增添了价值,并为在应对不断演变的网络威胁中增强网络安全提供了前瞻性解决方案。