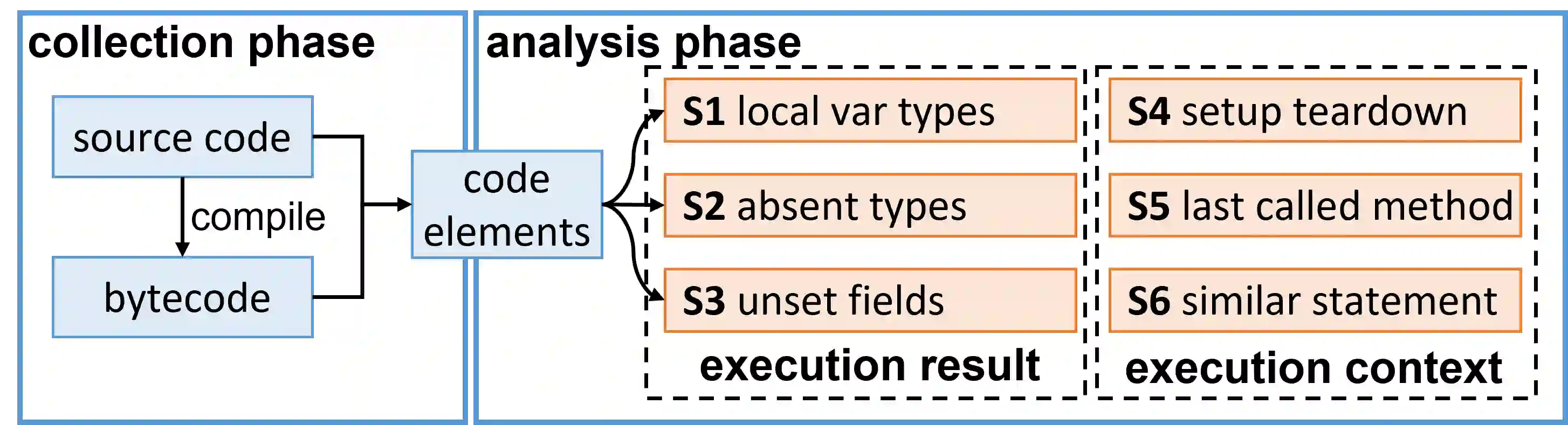
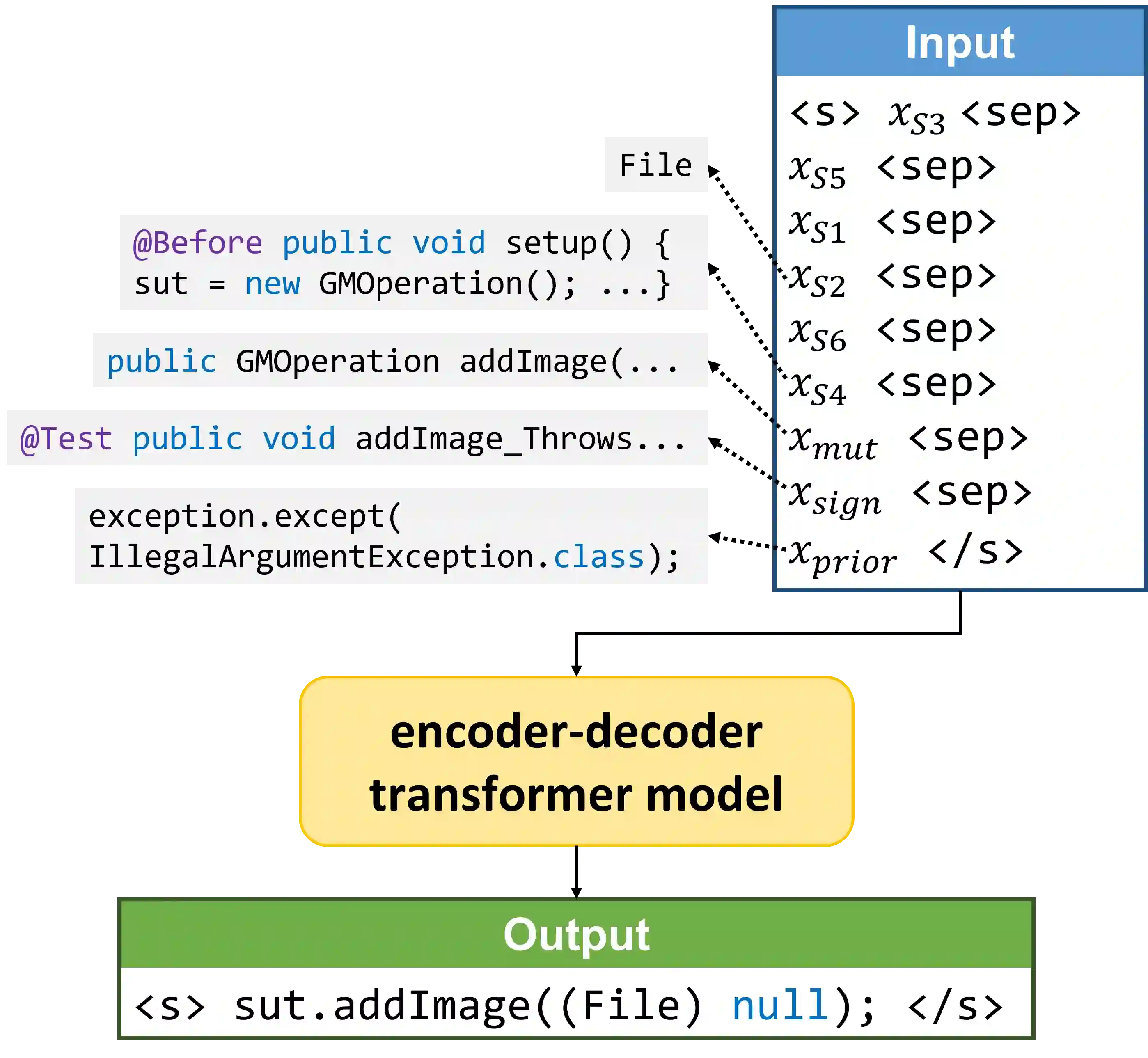
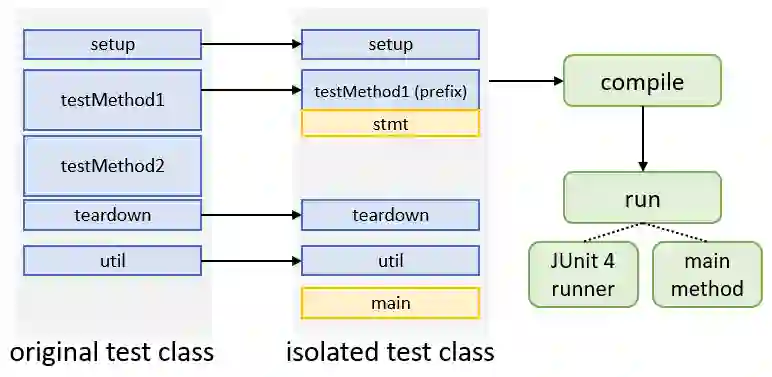
Writing tests is a time-consuming yet essential task during software development. We propose to leverage recent advances in deep learning for text and code generation to assist developers in writing tests. We formalize the novel task of test completion to automatically complete the next statement in a test method based on the context of prior statements and the code under test. We develop TeCo -- a deep learning model using code semantics for test completion. The key insight underlying TeCo is that predicting the next statement in a test method requires reasoning about code execution, which is hard to do with only syntax-level data that existing code completion models use. TeCo extracts and uses six kinds of code semantics data, including the execution result of prior statements and the execution context of the test method. To provide a testbed for this new task, as well as to evaluate TeCo, we collect a corpus of 130,934 test methods from 1,270 open-source Java projects. Our results show that TeCo achieves an exact-match accuracy of 18, which is 29% higher than the best baseline using syntax-level data only. When measuring functional correctness of generated next statement, TeCo can generate runnable code in 29% of the cases compared to 18% obtained by the best baseline. Moreover, TeCo is significantly better than prior work on test oracle generation.
翻译:编写测试是软件开发中一项耗时但必不可少的任务。我们提出利用深度学习在文本和代码生成方面的最新进展来协助开发人员编写测试。我们正式定义了测试补全这一新任务,即根据先前语句的上下文以及被测代码,自动补全测试方法中的下一条语句。我们开发了TeCo——一个利用代码语义进行测试补全的深度学习模型。TeCo的核心洞察在于:预测测试方法中的下一条语句需要对代码执行进行推理,而现有的代码补全模型仅使用语法级数据难以做到这一点。TeCo提取并使用了六类代码语义数据,包括先前语句的执行结果以及测试方法的执行上下文。为了为该新任务提供测试平台并评估TeCo,我们从1,270个开源Java项目中收集了130,934个测试方法。结果表明,TeCo的精确匹配准确率达到18%,比仅使用语法级数据的最佳基线方法高出29%。在衡量生成的下一条语句的功能正确性时,TeCo在29%的情况下能够生成可运行代码,而最佳基线方法仅为18%。此外,TeCo在测试预言生成方面也显著优于先前的工作。