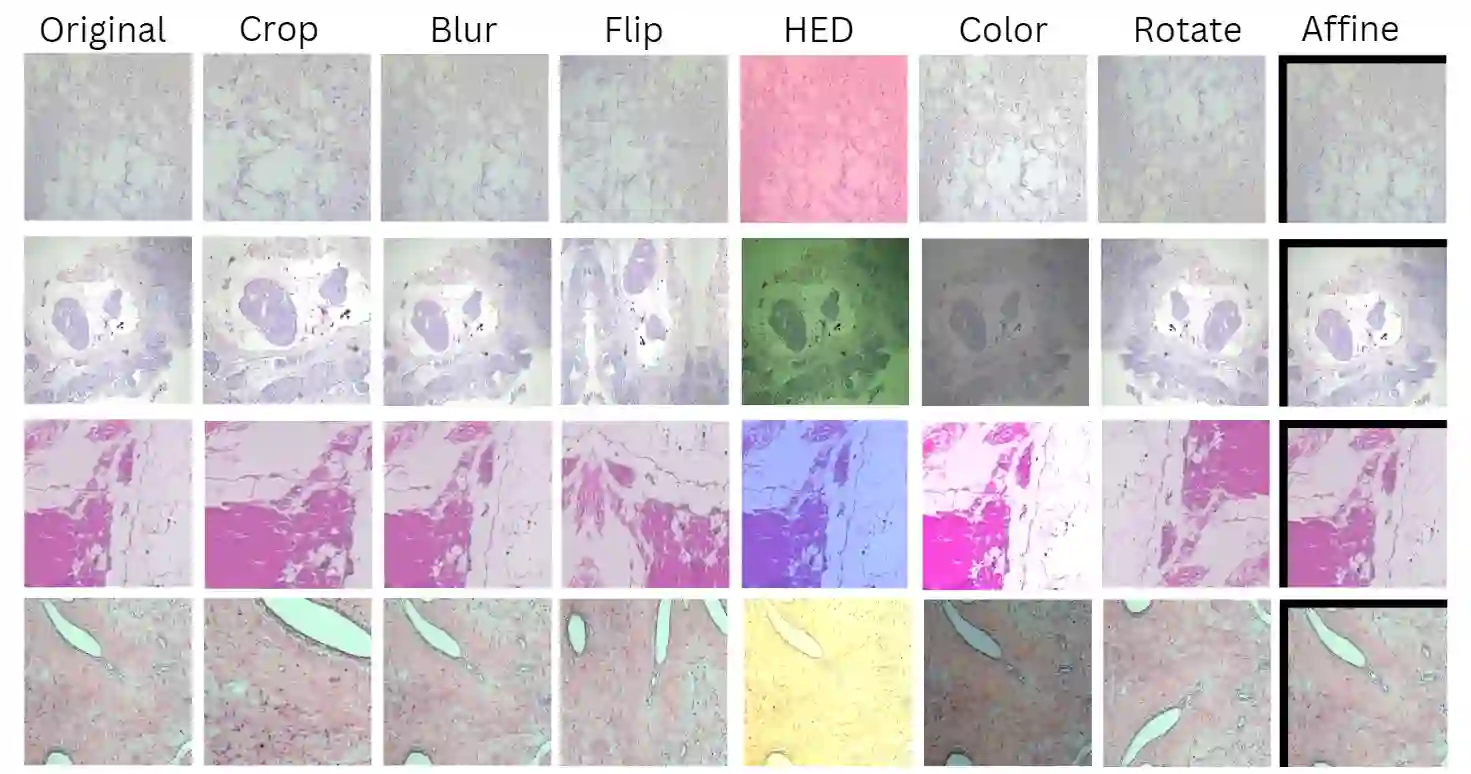
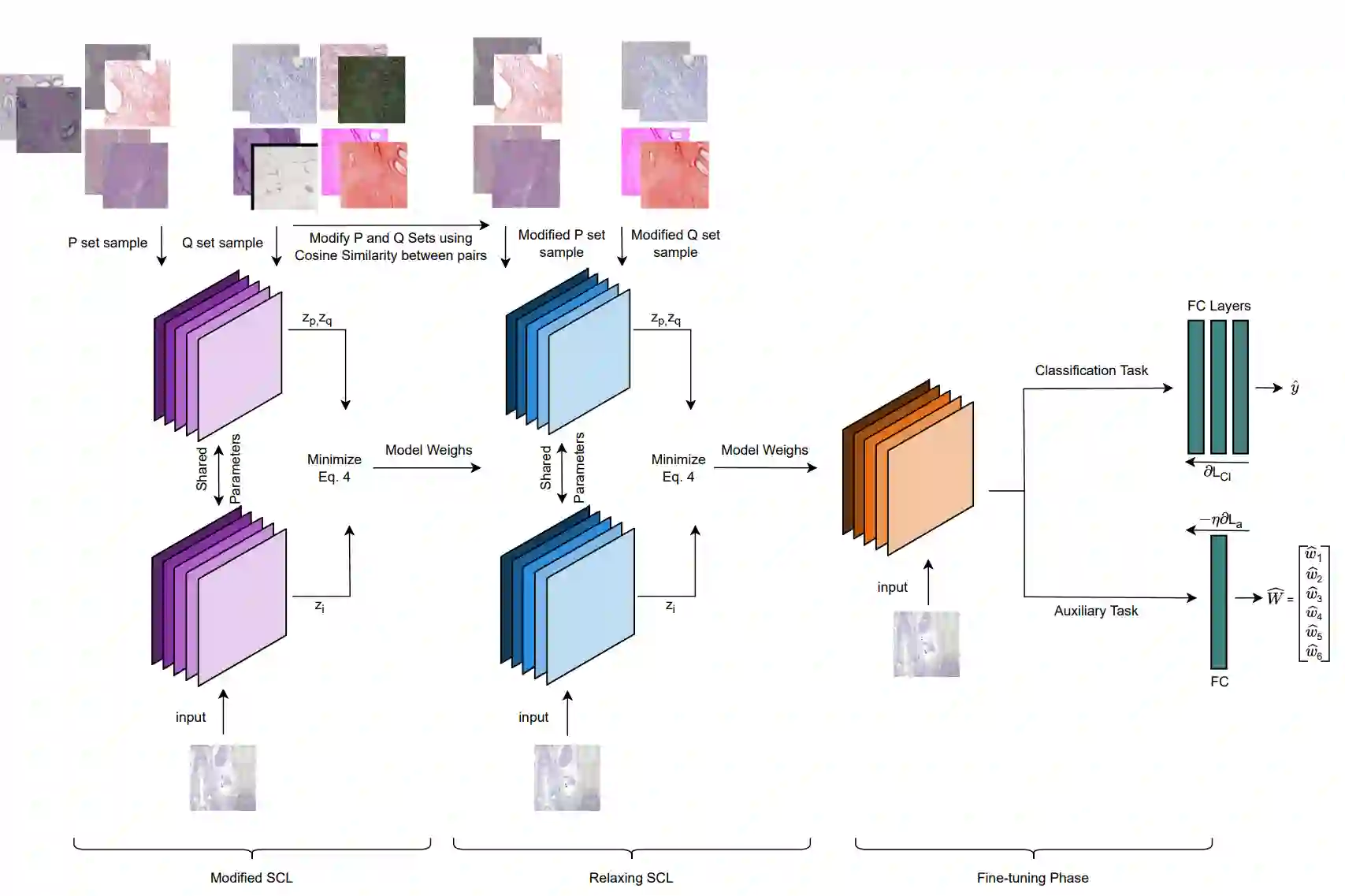
Deep neural networks have reached remarkable achievements in medical image processing tasks, specifically classifying and detecting various diseases. However, when confronted with limited data, these networks face a critical vulnerability, often succumbing to overfitting by excessively memorizing the limited information available. This work addresses the challenge mentioned above by improving the supervised contrastive learning method to reduce the impact of false positives. Unlike most existing methods that rely predominantly on fully supervised learning, our approach leverages the advantages of self-supervised learning in conjunction with employing the available labeled data. We evaluate our method on the BreakHis dataset, which consists of breast cancer histopathology images, and demonstrate an increase in classification accuracy by 1.45% at the image level and 1.42% at the patient level compared to the state-of-the-art method. This improvement corresponds to 93.63% absolute accuracy, highlighting our approach's effectiveness in leveraging data properties to learn more appropriate representation space.
翻译:深度神经网络在医学图像处理任务(特别是各类疾病的分类与检测)中取得了显著成果。然而,当面对有限数据时,这些网络存在关键性弱点,常因过度记忆有限信息而出现过拟合。本研究通过改进监督对比学习方法以减少假阳性影响,从而解决上述挑战。与多数依赖全监督学习的现有方法不同,本方法在利用可用标注数据的同时,充分发挥自监督学习的优势。我们基于由乳腺癌组织病理学图像构成的BreakHis数据集进行评估,结果显示:与现有最优方法相比,本方法在图像级分类准确率上提升1.45%,在患者级分类准确率上提升1.42%。该改进对应93.63%的绝对准确率,充分证明了本方法通过利用数据特性学习更优表征空间的有效性。