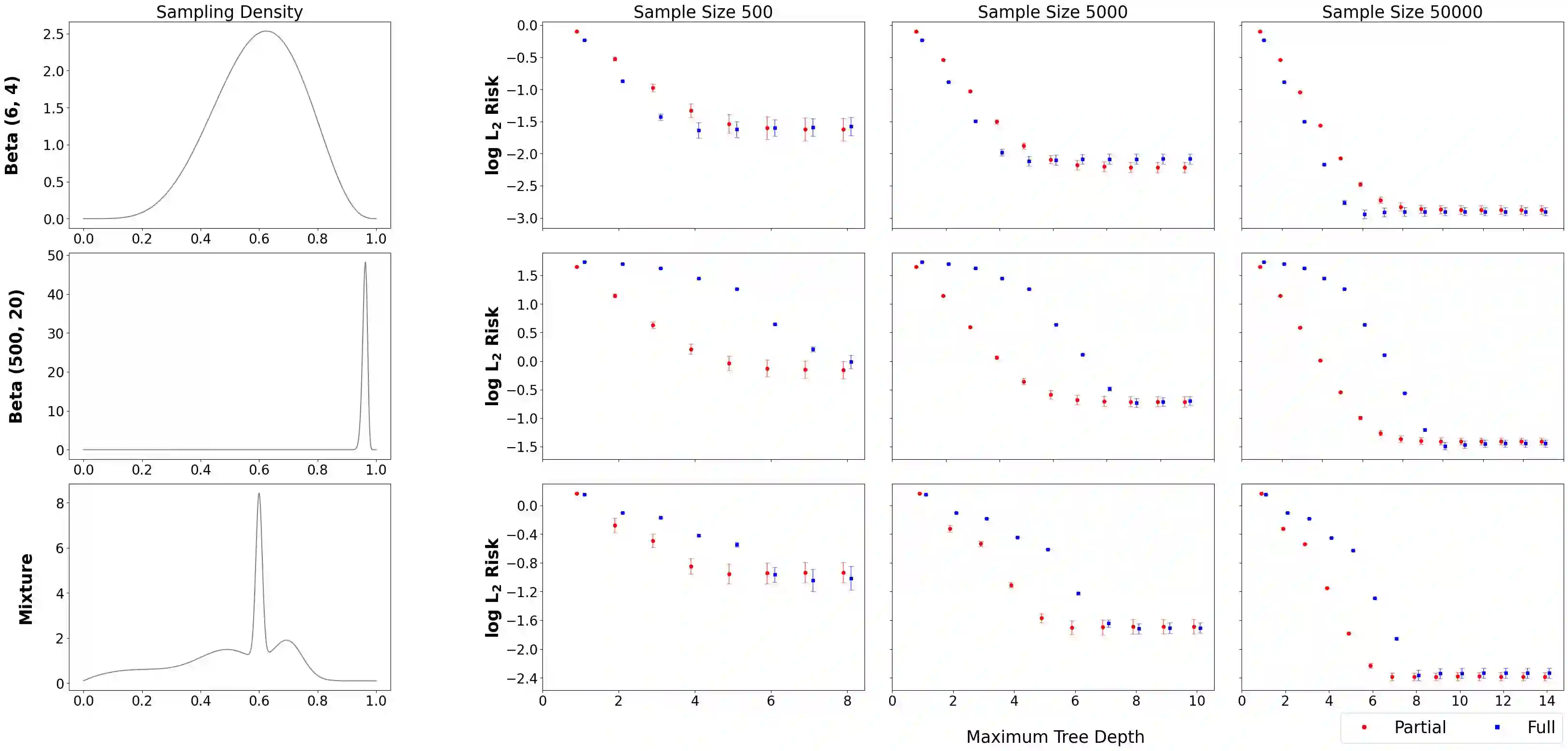
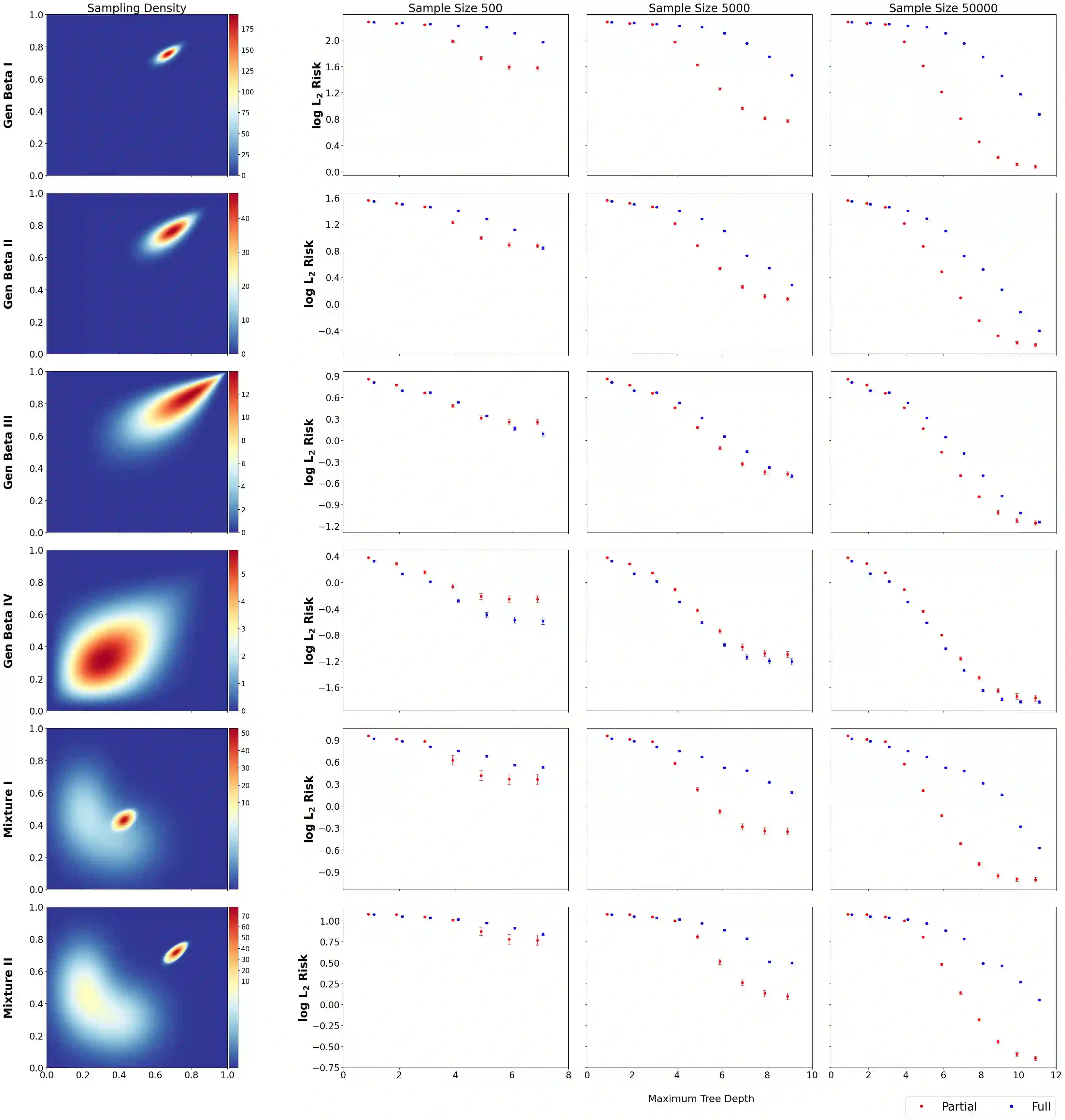
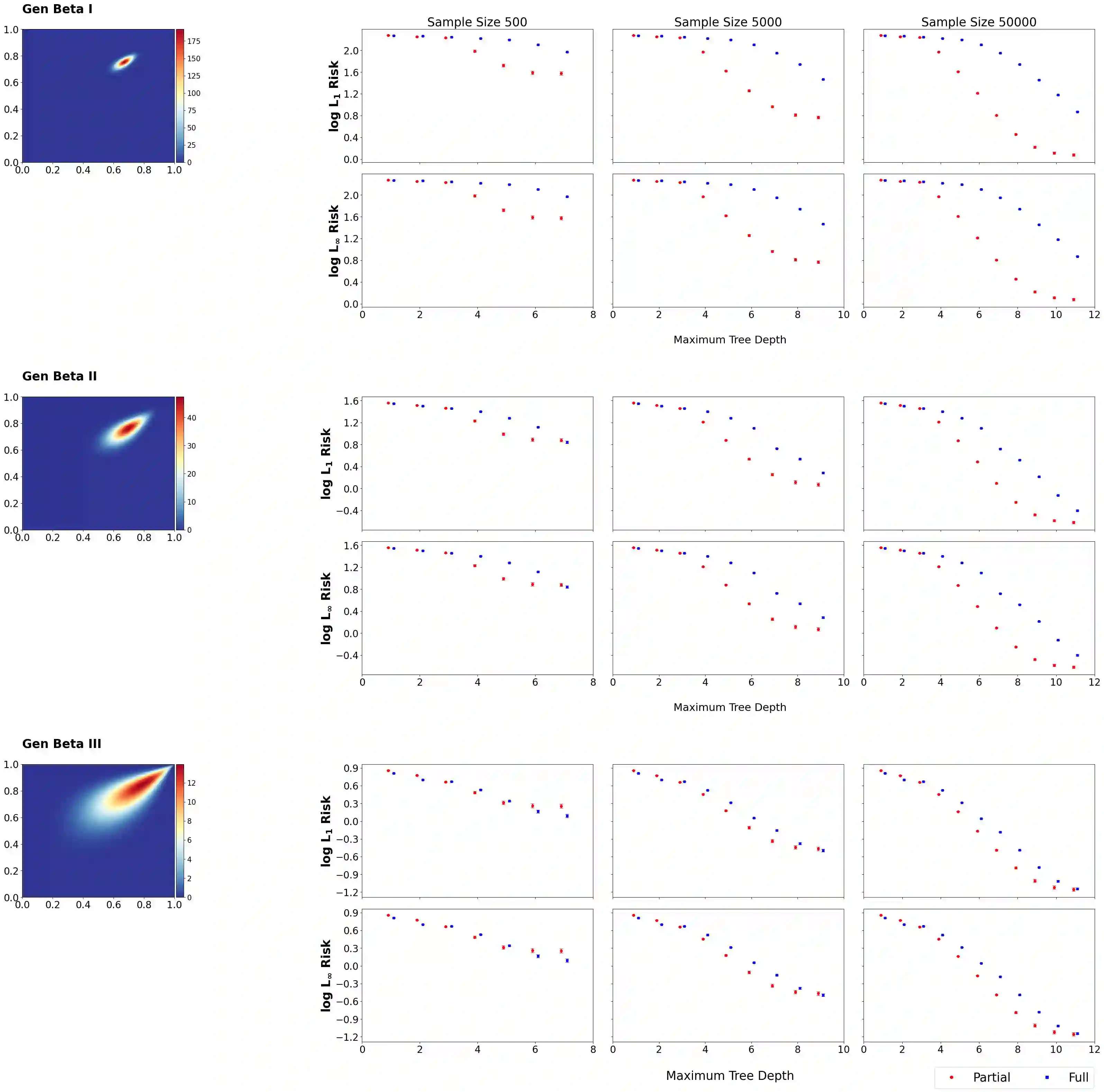
Tree-based models for probability distributions are usually specified using a predetermined, data-independent collection of candidate recursive partitions of the sample space. To characterize an unknown target density in detail over the entire sample space, candidate partitions must have the capacity to expand deeply into all areas of the sample space with potential non-zero sampling probability. Such an expansive system of partitions often incurs prohibitive computational costs and makes inference prone to overfitting, especially in regions with little probability mass. Existing models typically make a compromise and rely on relatively shallow trees. This hampers one of the most desirable features of trees, their ability to characterize local features, and results in reduced statistical efficiency. Traditional wisdom suggests that this compromise is inevitable to ensure coherent likelihood-based reasoning, as a data-dependent partition system that allows deeper expansion only in regions with more observations would induce double dipping of the data and thus lead to inconsistent inference. We propose a simple strategy to restore coherency while allowing the candidate partitions to be data-dependent, using Cox's partial likelihood. This strategy parametrizes the tree-based sampling model according to the allocation of probability mass based on the observed data, and yet under appropriate specification, the resulting inference remains valid. Our partial likelihood approach is broadly applicable to existing likelihood-based methods and in particular to Bayesian inference on tree-based models. We give examples in density estimation in which the partial likelihood is endowed with existing priors on tree-based models and compare with the standard, full-likelihood approach. The results show substantial gains in estimation accuracy and computational efficiency from using the partial likelihood.
翻译:基于树结构的概率分布模型通常通过预定义的、与数据无关的候选递归分割集合来构建。为了在整个样本空间中详细刻画未知目标密度,候选分割必须能够深入扩展到样本空间中所有可能具有非零采样概率的区域。这种扩展性分割系统往往会产生极高的计算成本,并容易导致过拟合,特别是在概率质量较小的区域。现有模型通常采取折中方案,依赖相对浅层的树结构。这削弱了树模型最具吸引力的特性之一——刻画局部特征的能力,并导致统计效率降低。传统观点认为,这种折中是保证基于似然的推理具有一致性的必然选择,因为若允许分割系统根据数据动态调整(仅在观测较多的区域进行深层扩展),会导致数据的重复利用,从而产生不一致的推断。我们提出一种简单策略,在允许候选分割依赖数据的同时保持推理的一致性,该方法基于Cox的部分似然思想。该策略根据观测数据的概率质量分配来参数化基于树结构的采样模型,在适当的设定下,所得推断仍保持有效性。我们的部分似然方法广泛适用于现有的基于似然的方法,特别是基于树模型的贝叶斯推断。我们以密度估计为例,将现有基于树模型的先验分布赋予部分似然,并与标准的全似然方法进行比较。结果表明,使用部分似然能显著提升估计精度与计算效率。