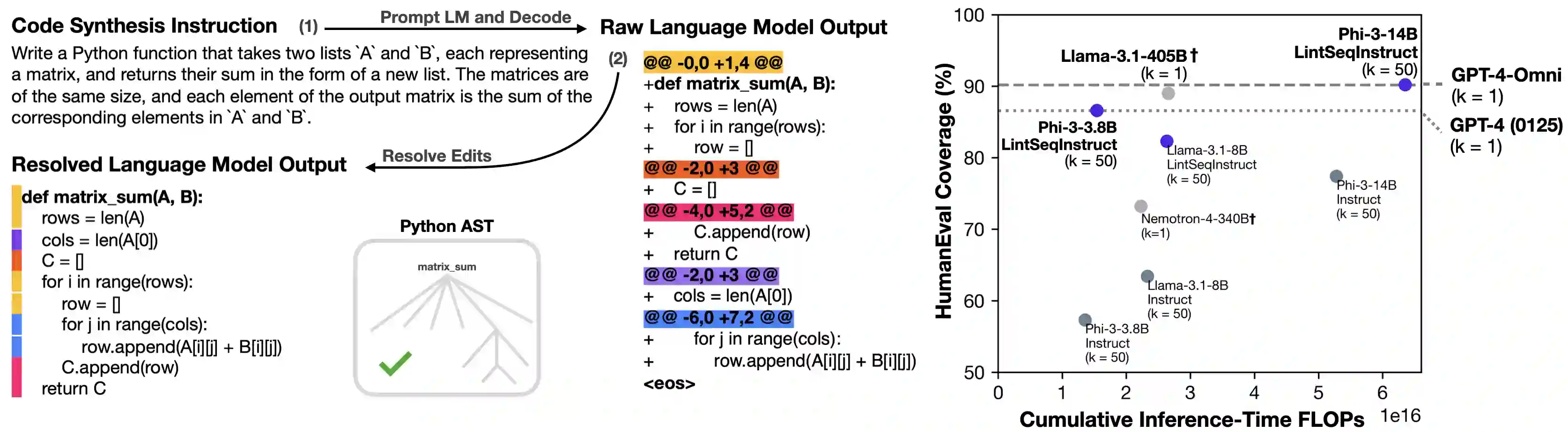
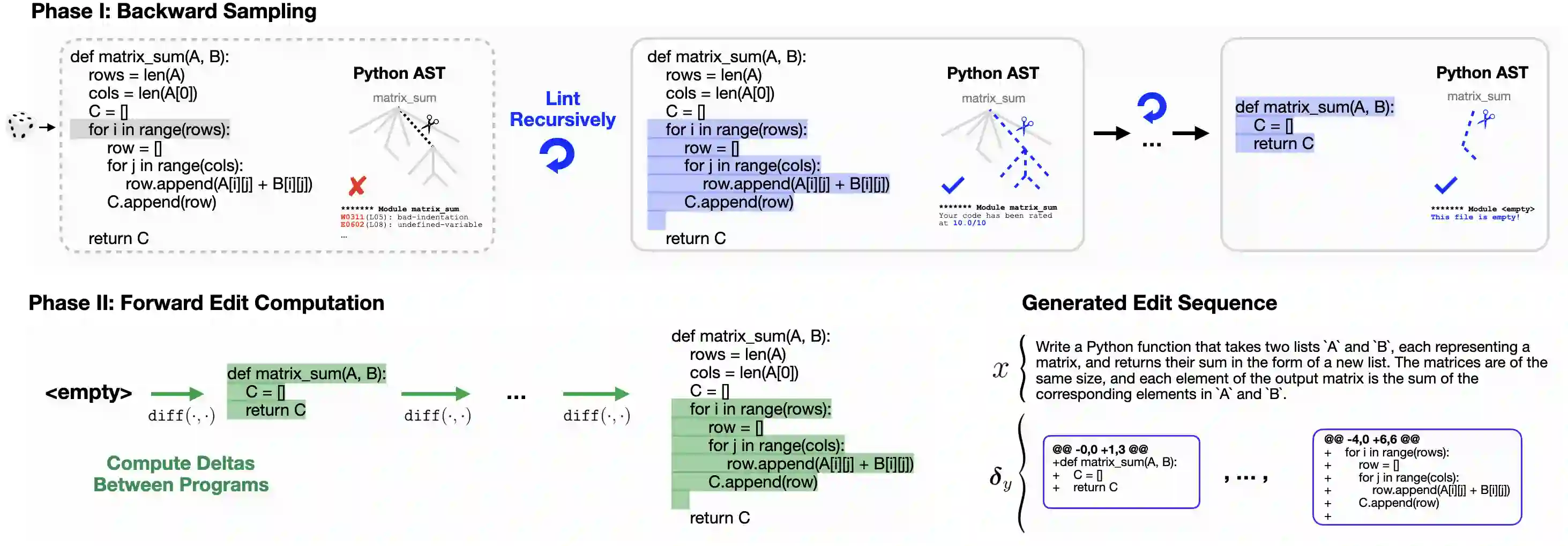
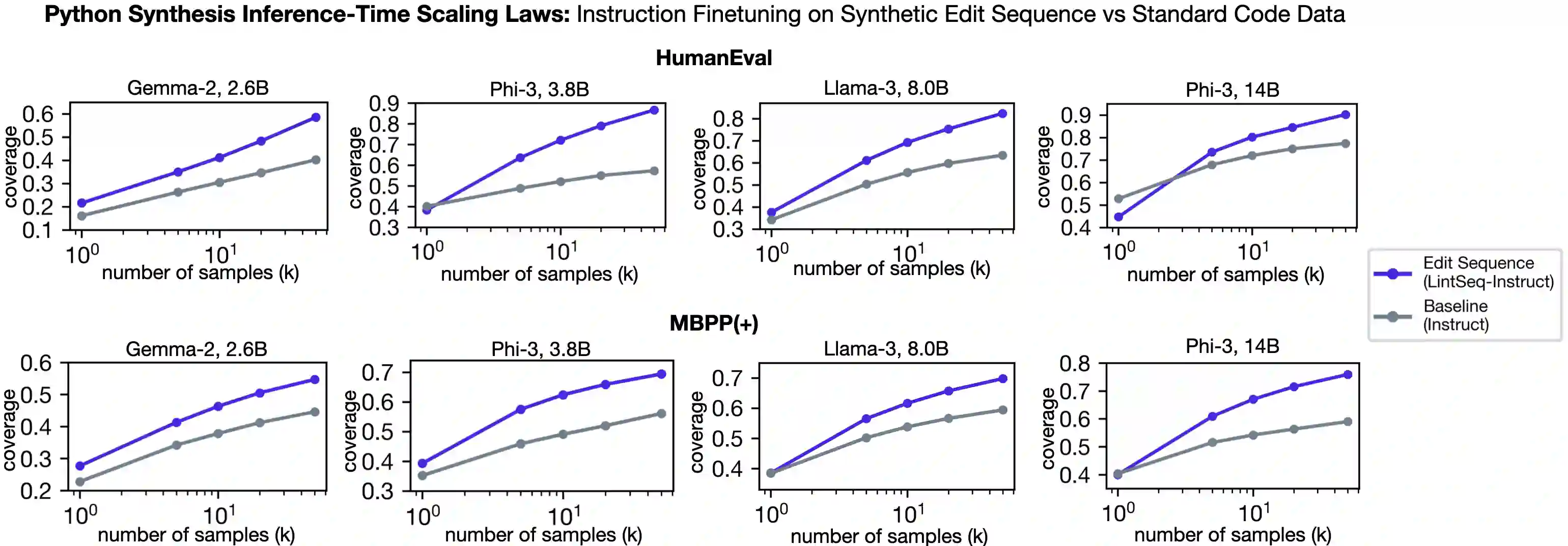
Software engineers mainly write code by editing existing programs. In contrast, large language models (LLMs) autoregressively synthesize programs in a single pass. One explanation for this is the scarcity of open-sourced edit data. While high-quality instruction data for code synthesis is already scarce, high-quality edit data is even scarcer. To fill this gap, we develop a synthetic data generation algorithm called LintSeq. This algorithm refactors existing code into a sequence of code edits by using a linter to procedurally sample across the error-free insertions that can be used to sequentially write programs. It outputs edit sequences as text strings consisting of consecutive program diffs. To test LintSeq, we use it to refactor a dataset of instruction + program pairs into instruction + program-diff-sequence tuples. Then, we instruction finetune a series of smaller LLMs ranging from 2.6B to 14B parameters on both the re-factored and original versions of this dataset, comparing zero-shot performance on code synthesis benchmarks. We show that during repeated sampling, edit sequence finetuned models produce more diverse programs than baselines. This results in better inference-time scaling for benchmark coverage as a function of samples, i.e. the fraction of problems "pass@k" solved by any attempt given "k" tries. For example, on HumanEval pass@50, small LLMs finetuned on synthetic edit sequences are competitive with GPT-4 and outperform models finetuned on the baseline dataset by +20% (+/-3%) in absolute score. Finally, we also pretrain our own tiny LMs for code understanding. We show that finetuning tiny models on synthetic code edits results in state-of-the-art code synthesis for the on-device model class. Our 150M parameter edit sequence LM matches or outperforms code models with twice as many parameters, both with and without repeated sampling, including Codex and AlphaCode.
翻译:软件工程师主要通过编辑现有程序来编写代码。相比之下,大型语言模型(LLMs)以自回归方式单次合成程序。造成这种差异的一个原因是开源编辑数据的稀缺性。虽然高质量的代码合成指令数据已然匮乏,但高质量的编辑数据更为稀缺。为填补这一空白,我们开发了一种名为LintSeq的合成数据生成算法。该算法通过使用代码检查工具对无错误插入操作进行程序化采样,将现有代码重构为一系列代码编辑序列,从而逐步生成程序。算法以文本字符串形式输出编辑序列,这些字符串由连续的程序差异(diff)组成。为验证LintSeq,我们使用它将一组“指令+程序”对数据集重构为“指令+程序差异序列”元组。随后,我们在该数据集的重构版本和原始版本上,对一系列参数规模从26亿到140亿不等的较小LLMs进行指令微调,并比较它们在代码合成基准测试上的零样本性能。实验表明,在重复采样过程中,经过编辑序列微调的模型比基线模型能生成更多样化的程序。这带来了更好的推理时扩展性——即基准覆盖率随样本数量(“k”次尝试中任意尝试成功解决问题的比例“pass@k”)变化的函数关系。例如,在HumanEval的pass@50测试中,基于合成编辑序列微调的小型LLMs与GPT-4性能相当,且绝对分数比基于基线数据集微调的模型高出+20%(±3%)。最后,我们还预训练了用于代码理解的微型语言模型。实验证明,在合成代码编辑序列上微调微型模型,可为设备端模型类别带来最先进的代码合成性能。我们的1.5亿参数编辑序列语言模型在有无重复采样的条件下,均达到或超越了参数规模两倍于自身的代码模型性能,包括Codex和AlphaCode。