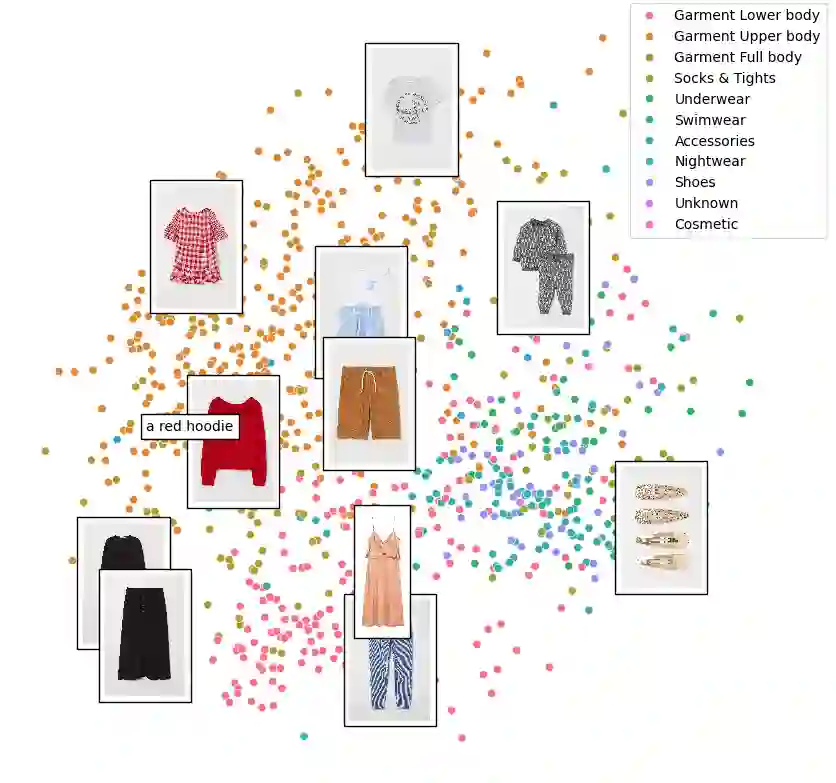
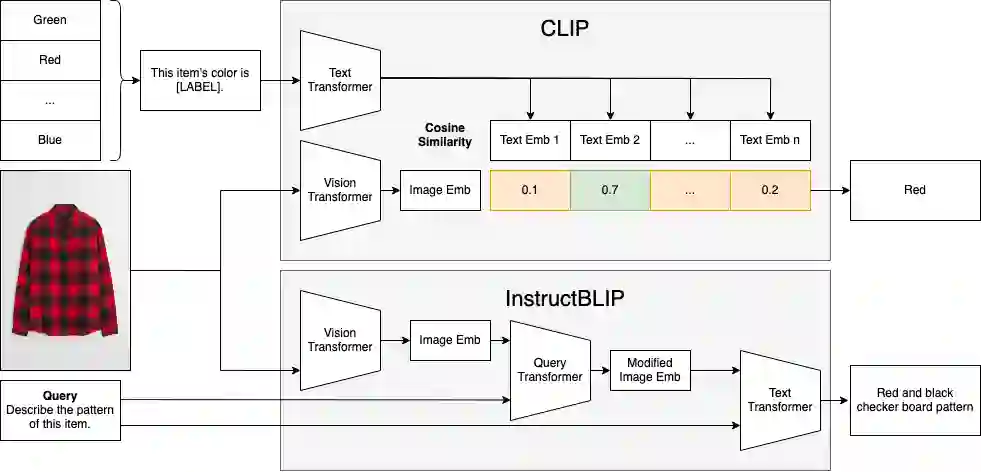
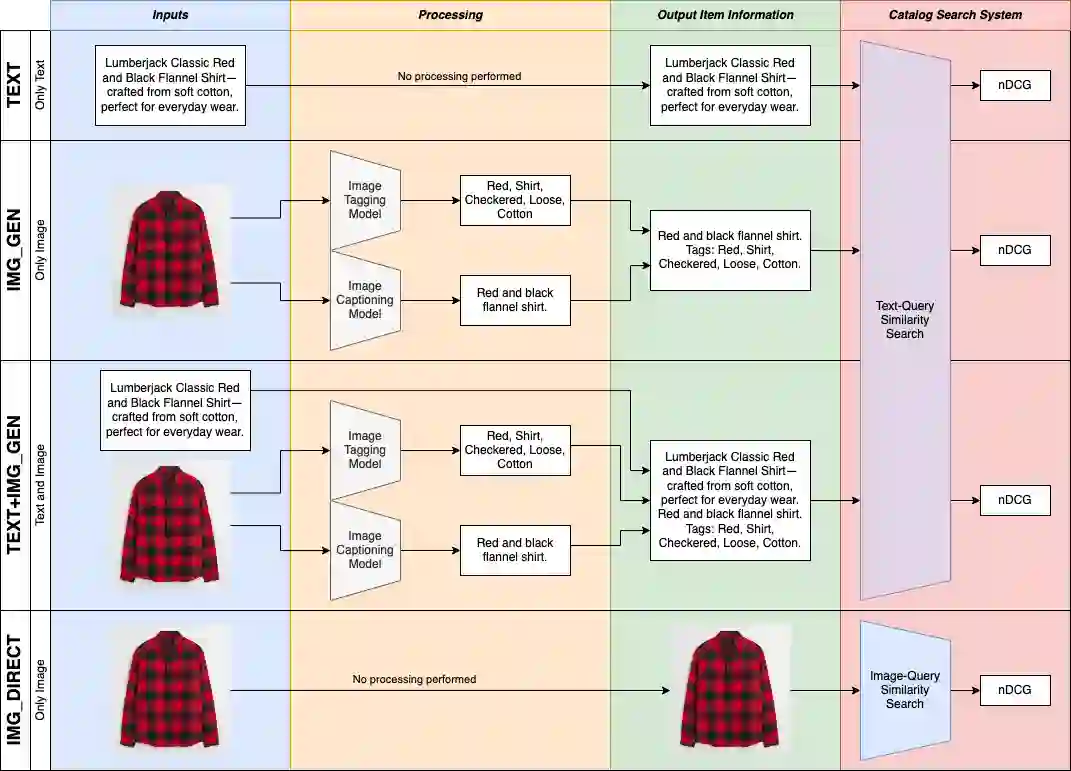
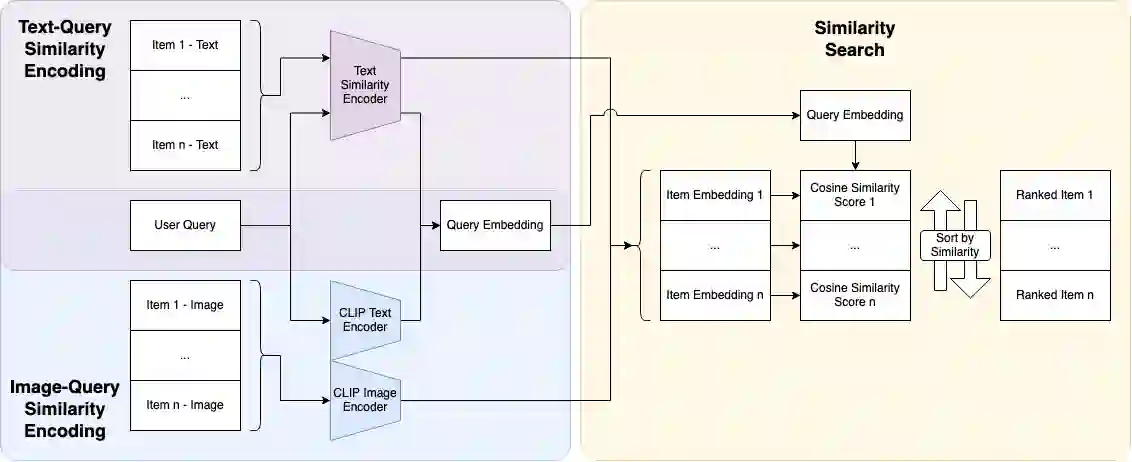
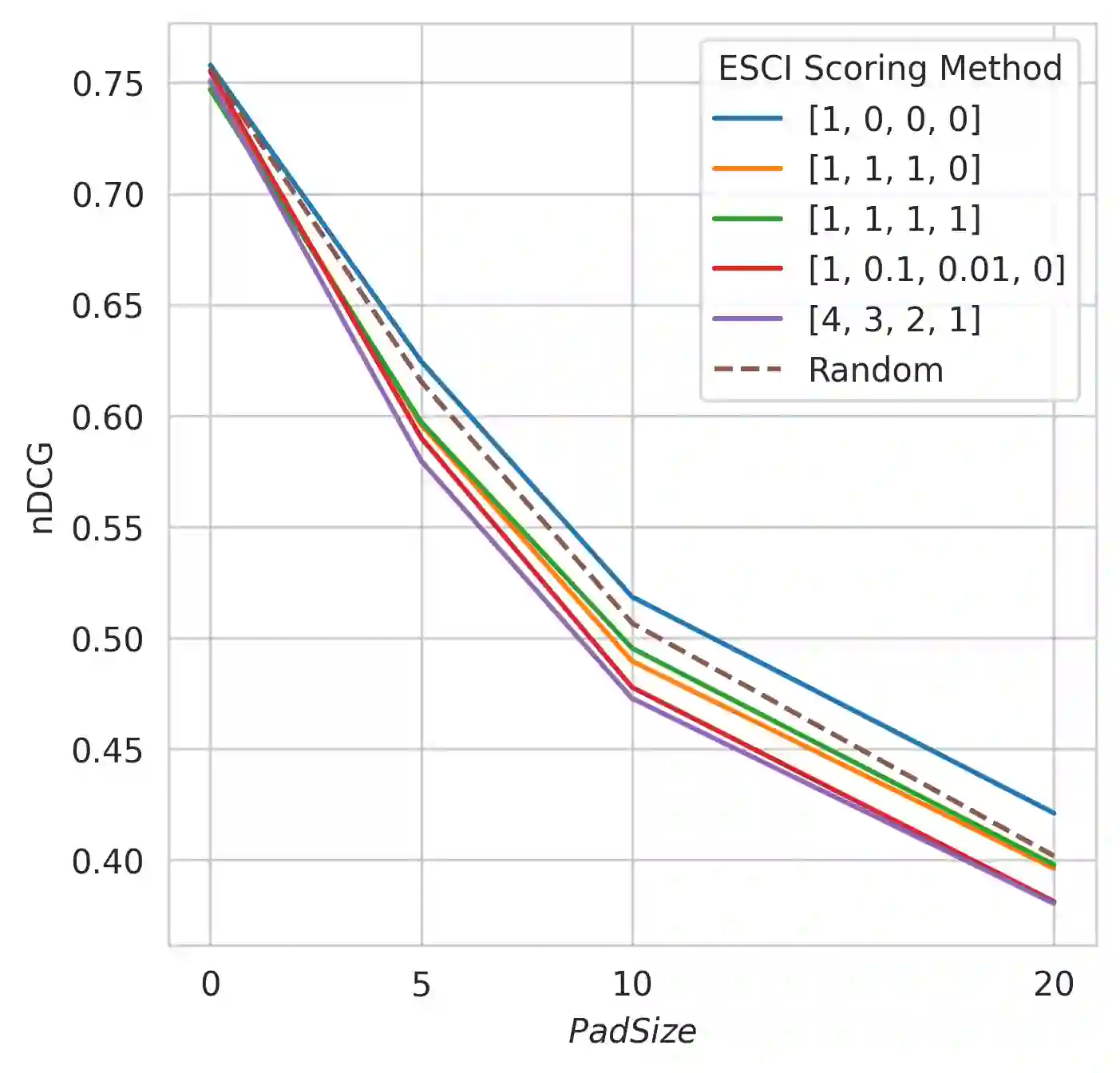
This paper explores the usage of multimodal image-to-text models to enhance text-based item retrieval. We propose utilizing pre-trained image captioning and tagging models, such as instructBLIP and CLIP, to generate text-based product descriptions which are combined with existing text descriptions. Our work is particularly impactful for smaller eCommerce businesses who are unable to maintain the high-quality text descriptions necessary to effectively perform item retrieval for search and recommendation use cases. We evaluate the searchability of ground-truth text, image-generated text, and combinations of both texts on several subsets of Amazon's publicly available ESCI dataset. The results demonstrate the dual capability of our proposed models to enhance the retrieval of existing text and generate highly-searchable standalone descriptions.
翻译:摘要:本文探索了利用多模态图像到文本模型增强基于文本的物品检索方法。我们提出使用预训练的图像描述和标注模型(如instructBLIP和CLIP)生成文本型产品描述,并将其与现有文本描述相结合。本研究尤其适用于无法维护高质量文本描述的小型电商企业,这类描述对于实现搜索和推荐场景中的物品检索至关重要。基于亚马逊公开的ESCI数据集多个子集,我们评估了真实文本、图像生成文本及两者组合文本的可检索性。结果表明,所提出的模型具有双重能力:既能增强现有文本的检索性能,又能生成高可检索性的独立描述。