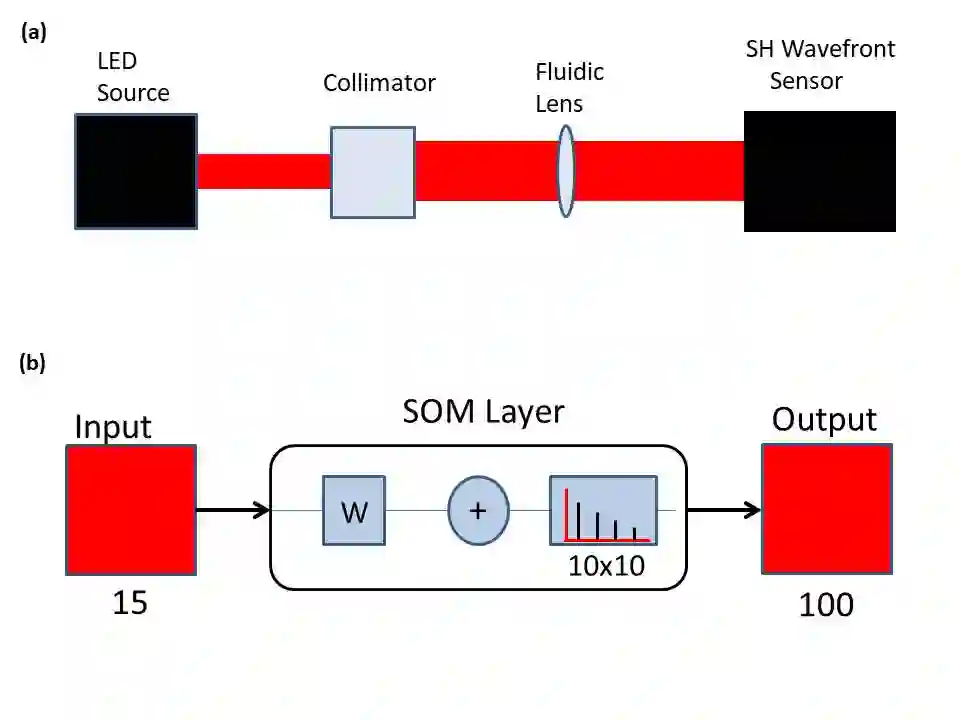
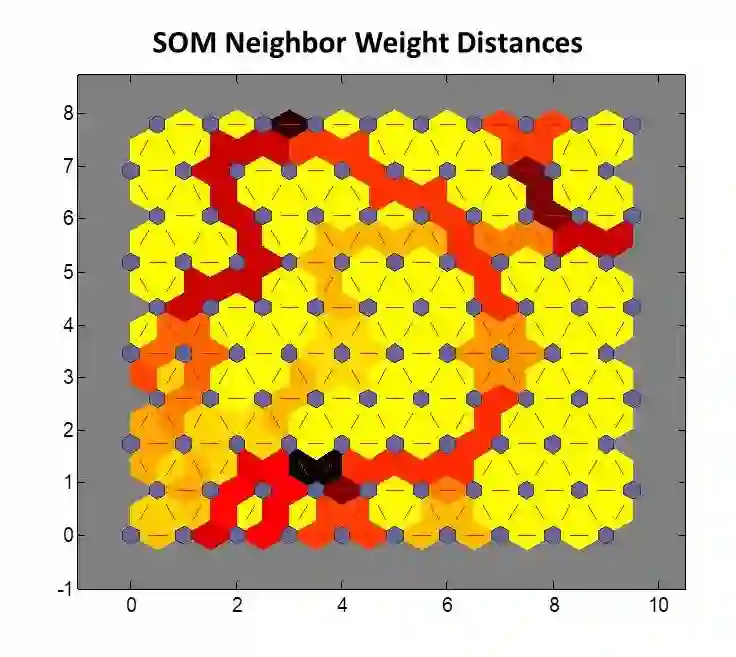
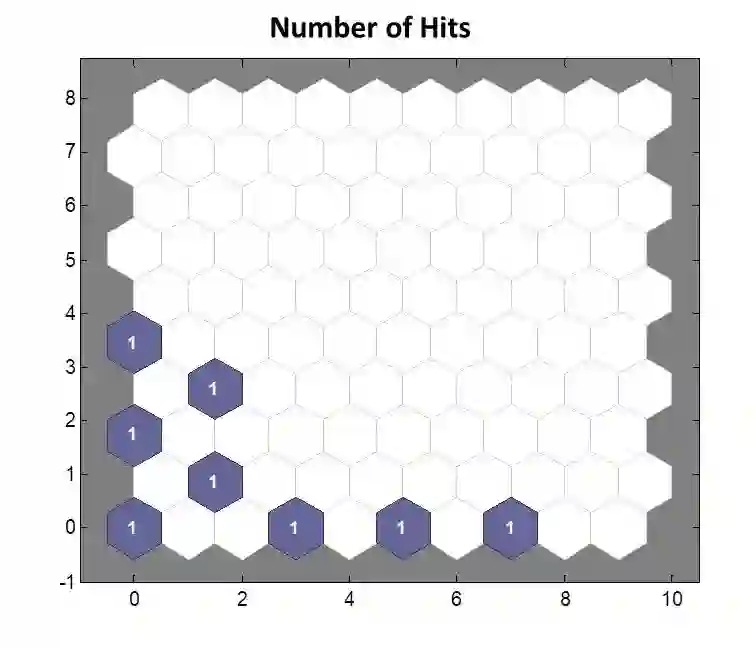
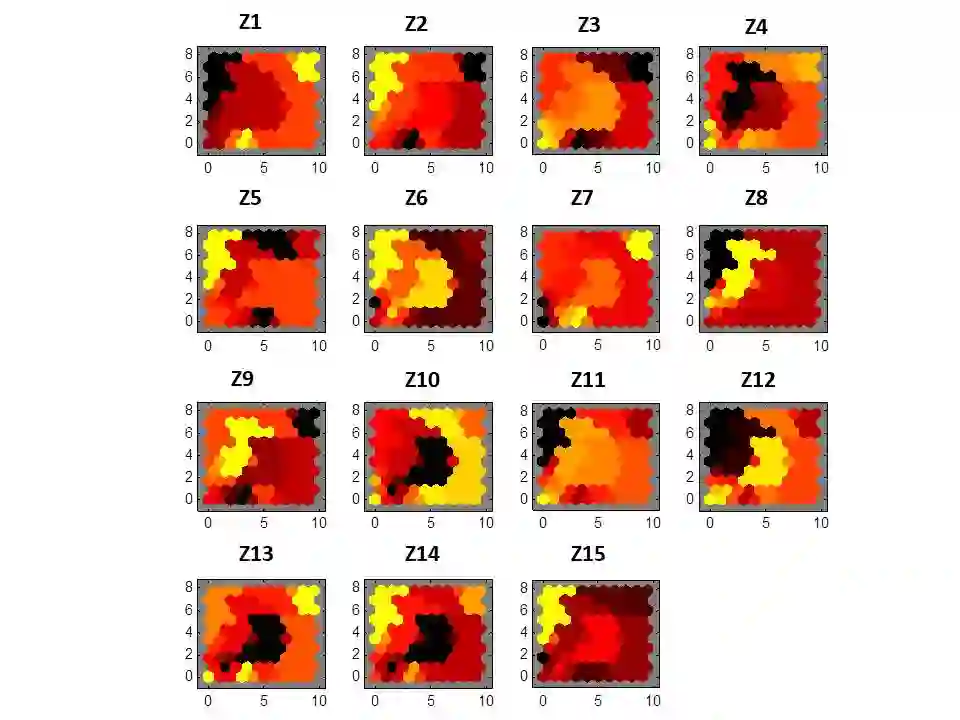
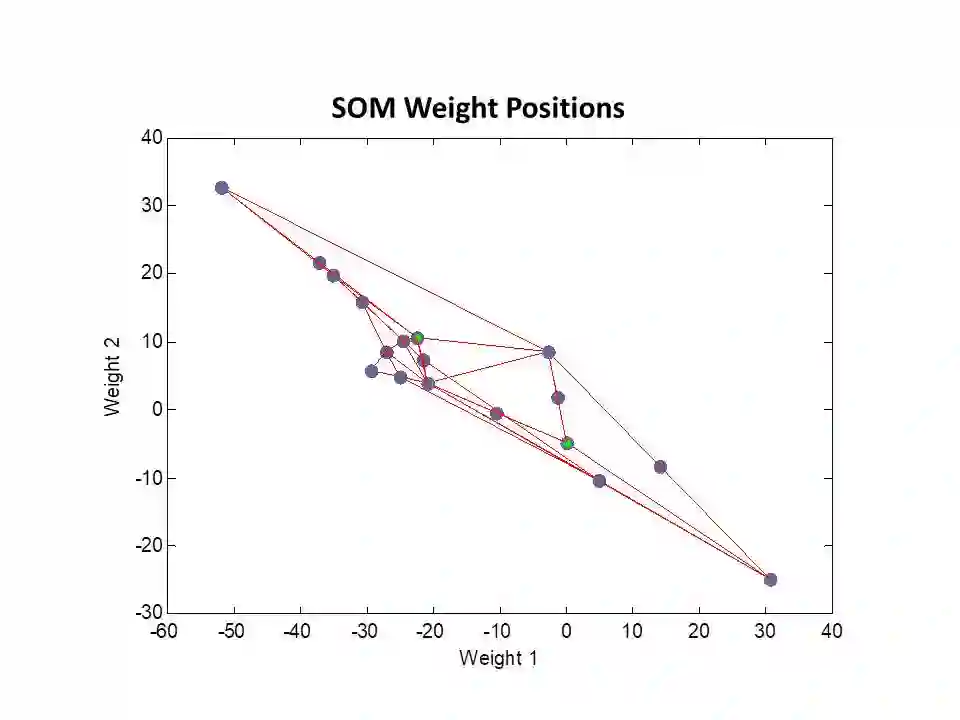
A comparison between neural network clustering (NNC), hierarchical clustering (HC) and K-means clustering (KMC) is performed to evaluate the computational superiority of these three machine learning (ML) techniques for organizing large datasets into clusters. For NNC, a self-organizing map (SOM) training was applied to a collection of wavefront sensor reconstructions, decomposed in terms of 15 Zernike coefficients, characterizing the optical aberrations of the phase front transmitted by fluidic lenses. In order to understand the distribution and structure of the 15 Zernike variables within an input space, SOM-neighboring weight distances, SOM-sample hits, SOM-weight positions and SOM-weight planes were analyzed to form a visual interpretation of the system's structural properties. In the case of HC, the data was partitioned using a combined dissimilarity-linkage matrix computation. The effectiveness of this method was confirmed by a high cophenetic correlation coefficient value (c=0.9651). Additionally, a maximum number of clusters was established by setting an inconsistency cutoff of 0.8, yielding a total of 7 clusters for system segmentation. In addition, a KMC approach was employed to establish a quantitative measure of clustering segmentation efficiency, obtaining a sillhoute average value of 0.905 for data segmentation into K=5 non-overlapping clusters. On the other hand, the NNC analysis revealed that the 15 variables could be characterized through the collective influence of 8 clusters. It was established that the formation of clusters through the combined linkage and dissimilarity algorithms of HC alongside KMC is a more dependable clustering solution than separate assessment via NNC or HC, where altering the SOM size or inconsistency cutoff can lead to completely new clustering configurations.
翻译:本文对神经网络聚类、层次聚类与K均值聚类进行了比较研究,旨在评估这三种机器学习技术在将大型数据集组织为聚类时的计算优越性。针对神经网络聚类,本研究将自组织映射训练应用于一组波前传感器重构数据,这些数据通过15项泽尼克系数进行分解,用以表征流体透镜透射相位波前的光学像差。为理解15个泽尼克变量在输入空间中的分布与结构,通过分析SOM相邻权重距离、SOM样本命中率、SOM权重位置及SOM权重平面,形成了对系统结构特性的可视化解读。在层次聚类方面,采用相异度-连接矩阵联合计算对数据进行划分,该方法有效性通过较高的同表型相关系数值(c=0.9651)得以验证。此外,通过设定0.8的不一致性阈值确定最大聚类数量,最终获得7个聚类用于系统分割。同时,采用K均值聚类方法建立聚类分割效率的量化指标,在将数据分割为K=5个非重叠聚类时获得0.905的平均轮廓系数值。另一方面,神经网络聚类分析表明15个变量可通过8个聚类的集体影响进行表征。研究证实,结合层次聚类的连接算法与相异度算法以及K均值聚类所形成的聚类方案,相较于单独通过神经网络聚类或层次聚类的评估更为可靠,因为改变SOM规模或不一致性阈值可能导致全新的聚类构型。