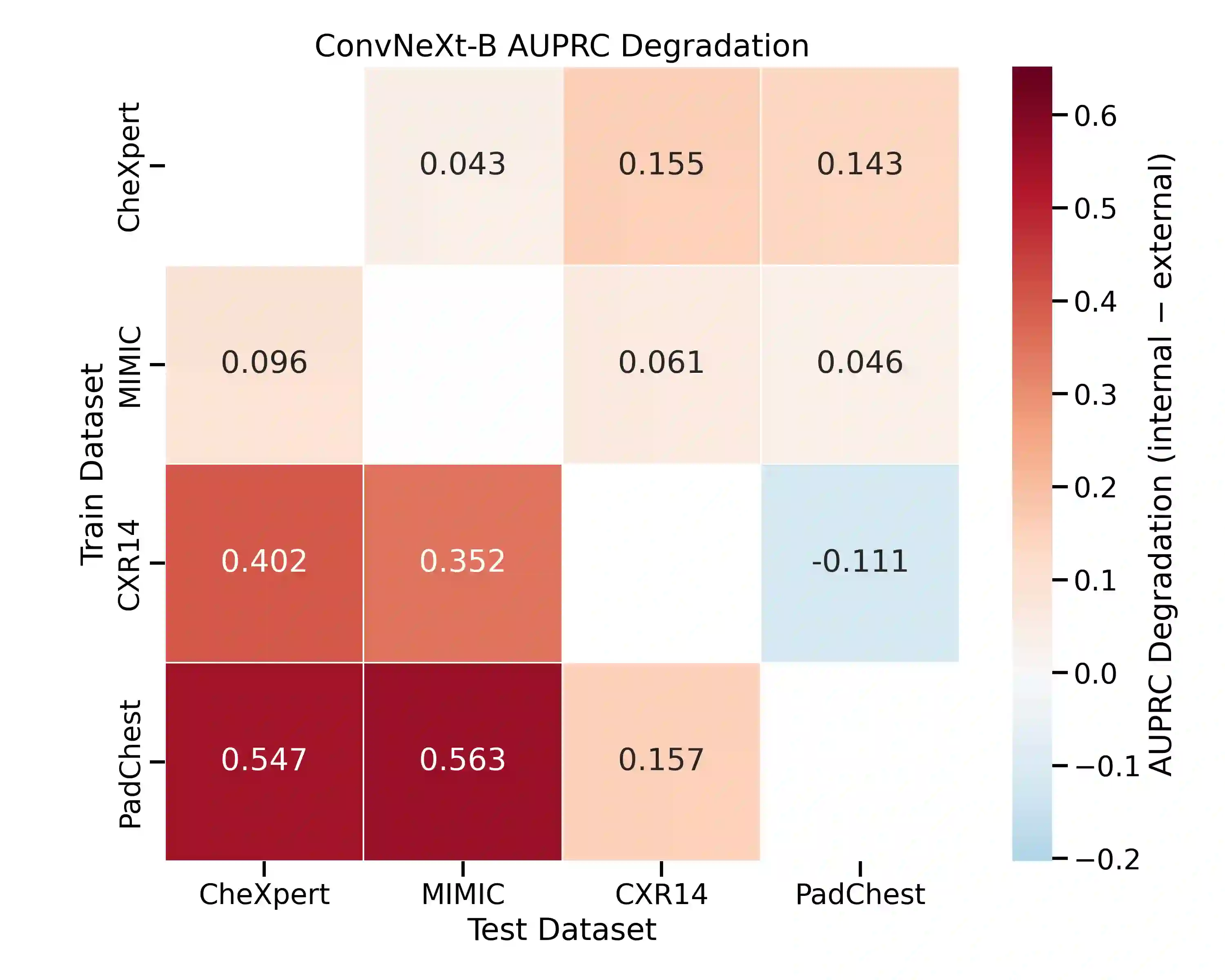
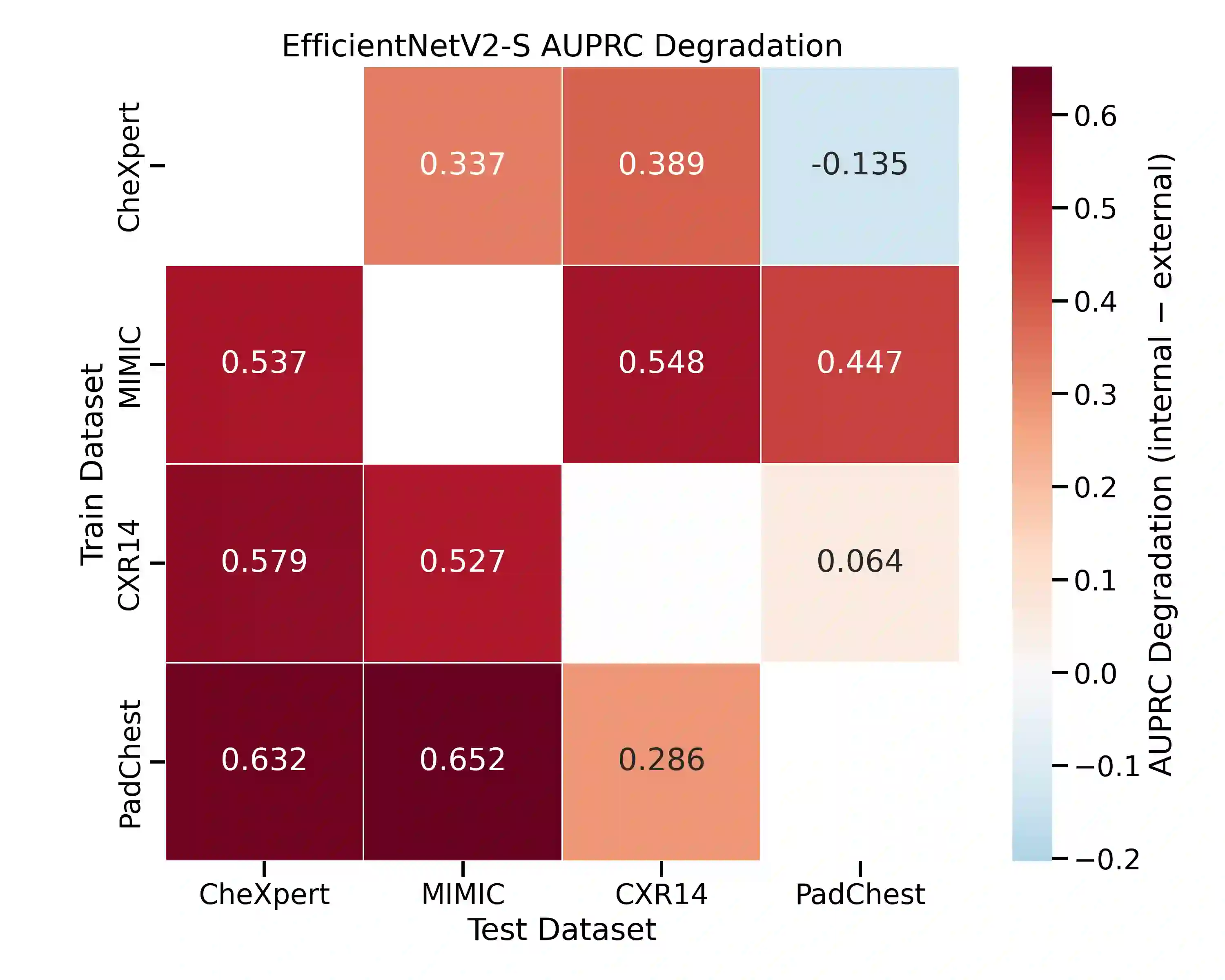
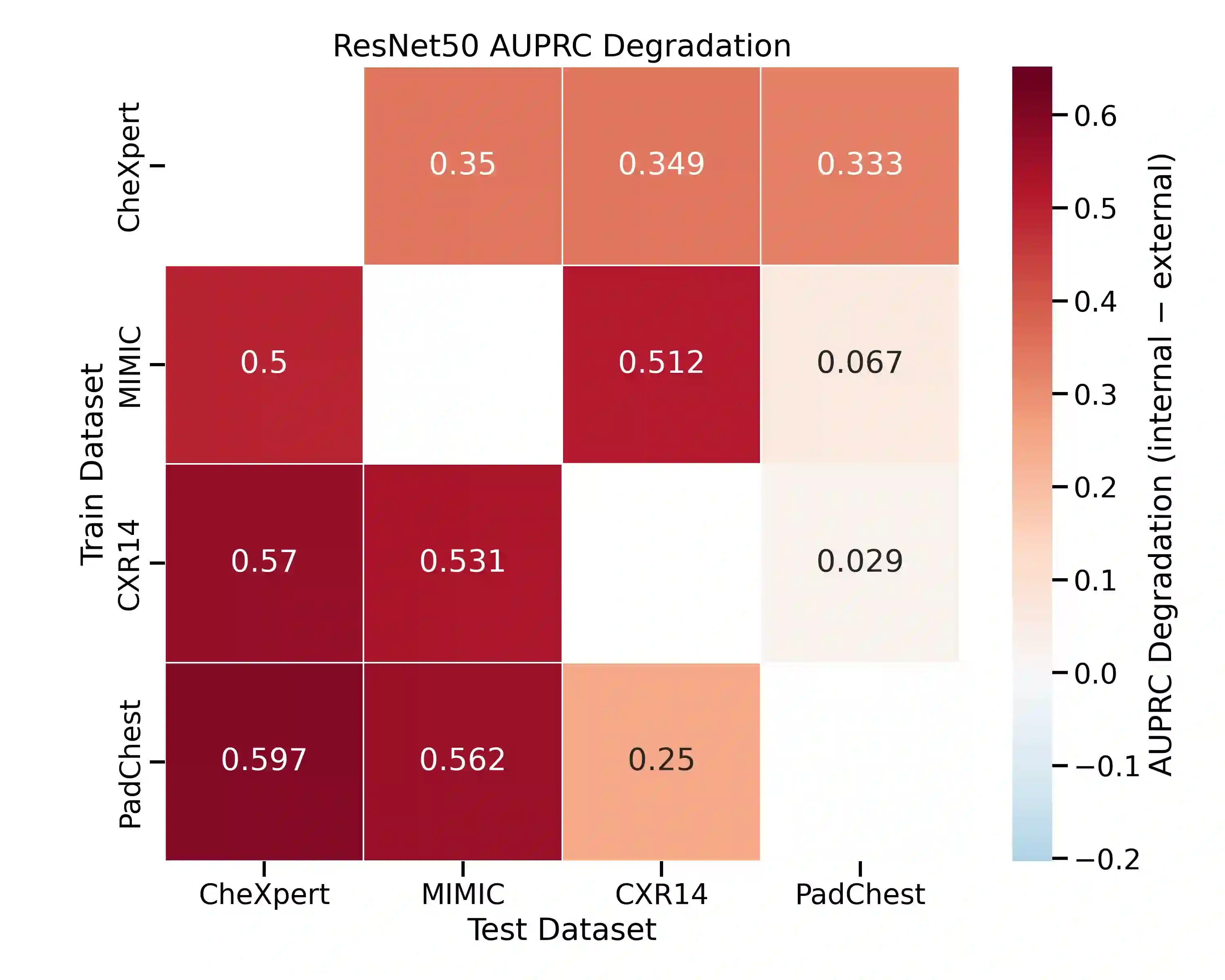
Artificial intelligence has shown significant promise in chest radiography, where deep learning models can approach radiologist-level diagnostic performance. Progress has been accelerated by large public datasets such as MIMIC-CXR, ChestX-ray14, PadChest, and CheXpert, which provide hundreds of thousands of labelled images with pathology annotations. However, these datasets also present important limitations. Automated label extraction from radiology reports introduces errors, particularly in handling uncertainty and negation, and radiologist review frequently disagrees with assigned labels. In addition, domain shift and population bias restrict model generalisability, while evaluation practices often overlook clinically meaningful measures. We conduct a systematic analysis of these challenges, focusing on label quality, dataset bias, and domain shift. Our cross-dataset domain shift evaluation across multiple model architectures revealed substantial external performance degradation, with pronounced reductions in AUPRC and F1 scores relative to internal testing. To assess dataset bias, we trained a source-classification model that distinguished datasets with near-perfect accuracy, and performed subgroup analyses showing reduced performance for minority age and sex groups. Finally, expert review by two board-certified radiologists identified significant disagreement with public dataset labels. Our findings highlight important clinical weaknesses of current benchmarks and emphasise the need for clinician-validated datasets and fairer evaluation frameworks.
翻译:人工智能在胸部X光影像分析领域展现出显著潜力,深度学习模型已能接近放射科医师的诊断水平。MIMIC-CXR、ChestX-ray14、PadChest和CheXpert等大型公共数据集通过提供数十万张带有病理标注的标记图像,加速了该领域的发展。然而,这些数据集也存在重要局限:从放射学报告中自动提取标签会引入误差,尤其在处理不确定性和否定表述时;放射科医师复核结果常与预设标签存在分歧。此外,领域偏移和群体偏见限制了模型的泛化能力,而现行评估方法往往忽略临床意义指标。本文系统分析了标签质量、数据集偏见和领域偏移三大挑战。通过跨数据集的领域偏移评估(涵盖多种模型架构),我们发现模型外部性能显著退化,其AUPRC和F1分数相较于内部测试明显下降。为评估数据集偏见,我们训练了能近乎完美区分数据集的源分类模型,并通过亚组分析发现模型在少数年龄和性别群体中表现下降。最后,两位认证放射科医师的专家复核显示,公共数据集标签存在显著争议。本研究揭示了当前基准数据集的重要临床缺陷,强调需要建立临床医师验证的数据集和更公平的评估框架。