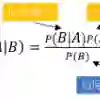
Whether based on models, training data or a combination, classifiers place (possibly complex) input data into one of a relatively small number of output categories. In this paper, we study the structure of the boundary--those points for which a neighbor is classified differently--in the context of an input space that is a graph, so that there is a concept of neighboring inputs, The scientific setting is a model-based naive Bayes classifier for DNA reads produced by Next Generation Sequencers. We show that the boundary is both large and complicated in structure. We create a new measure of uncertainty, called Neighbor Similarity, that compares the result for a point to the distribution of results for its neighbors. This measure not only tracks two inherent uncertainty measures for the Bayes classifier, but also can be implemented, at a computational cost, for classifiers without inherent measures of uncertainty.
翻译:无论是基于模型、训练数据还是两者的结合,分类器都会将(可能复杂的)输入数据归入相对较少的输出类别之一。本文研究了输入空间为图结构时的边界结构(即相邻点被分类不同的那些点),从而引入了相邻输入的概念。科学背景是基于模型的朴素贝叶斯分类器,用于分析下一代测序仪产生的DNA读段。我们证明了该边界不仅规模庞大,而且结构复杂。我们创造了一个新的不确定性度量,称为邻域相似度,它比较某个点的结果与其邻居结果分布之间的差异。该度量不仅能追踪贝叶斯分类器的两种固有不确定性度量,还能在计算成本下应用于没有固有不确定性度量的分类器。