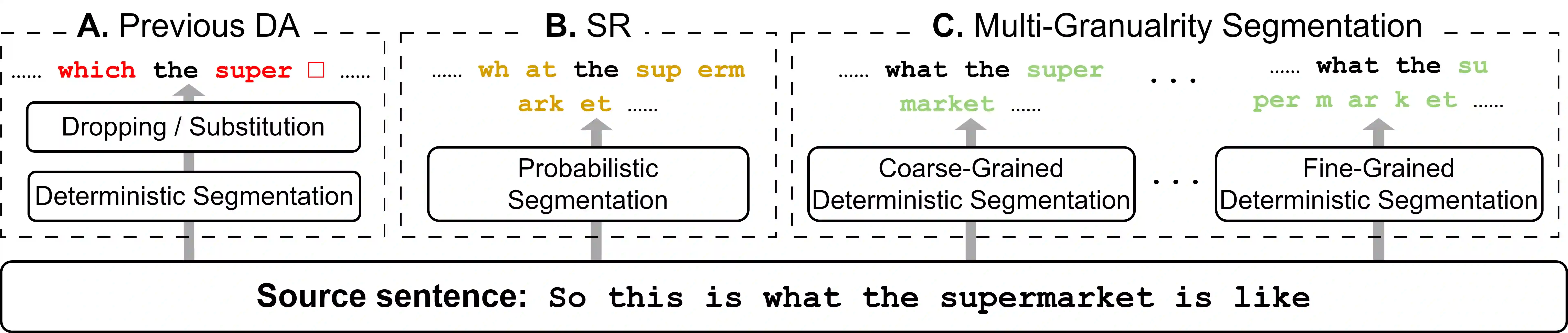
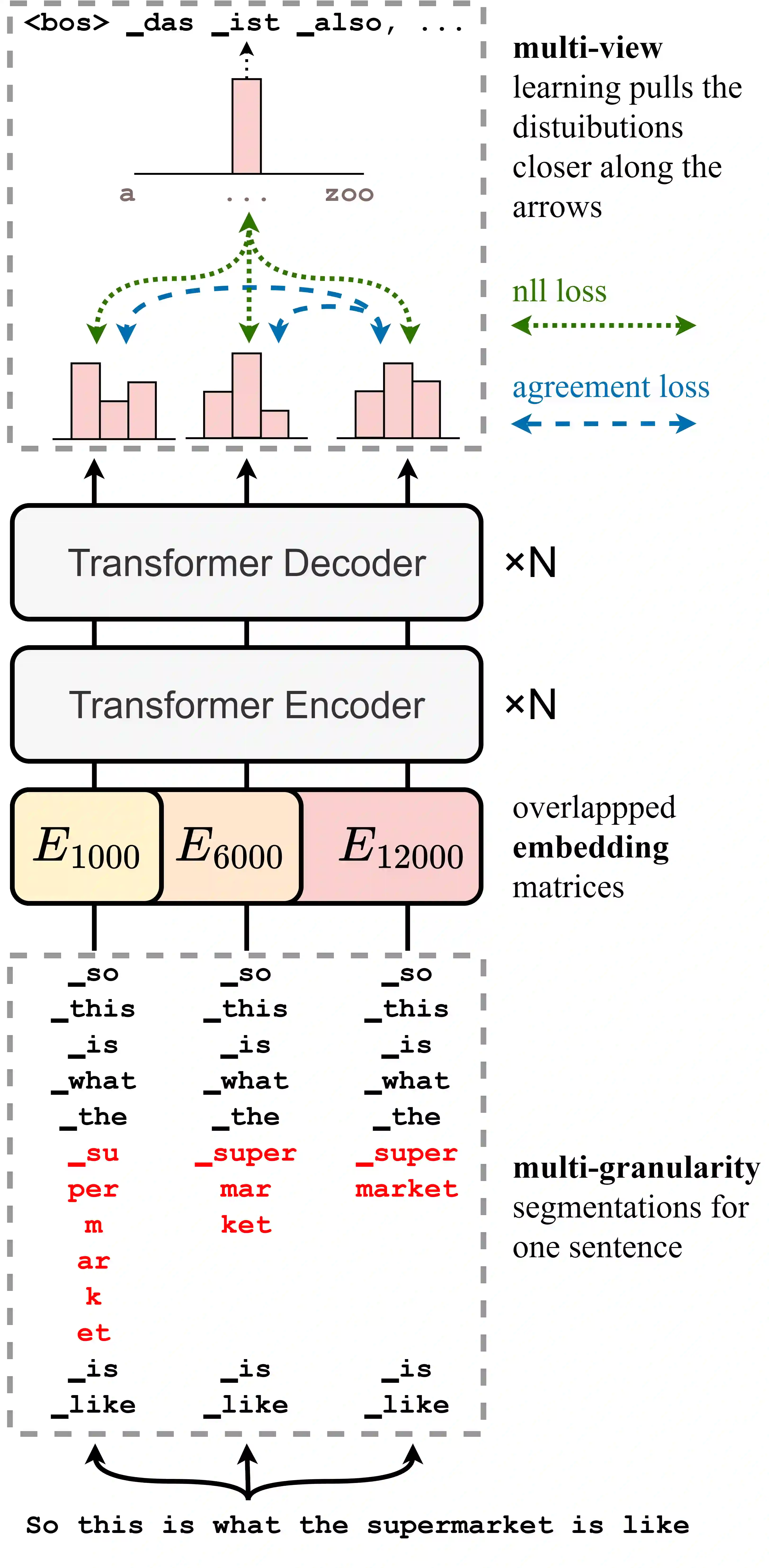
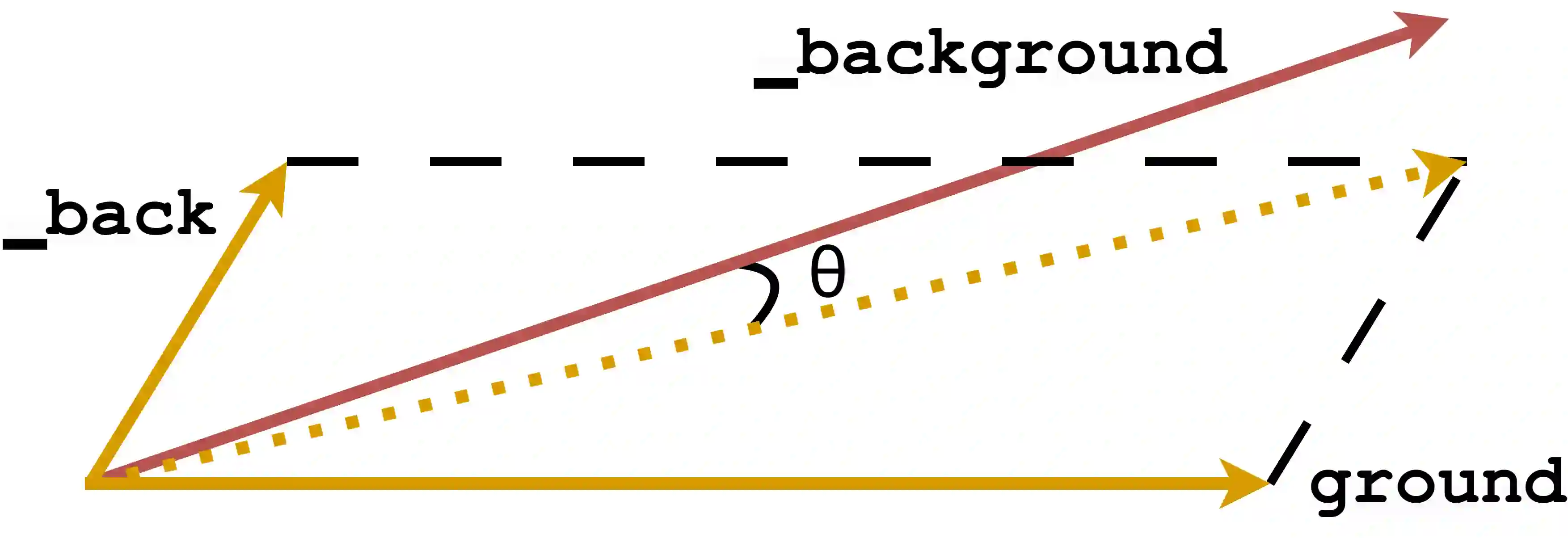
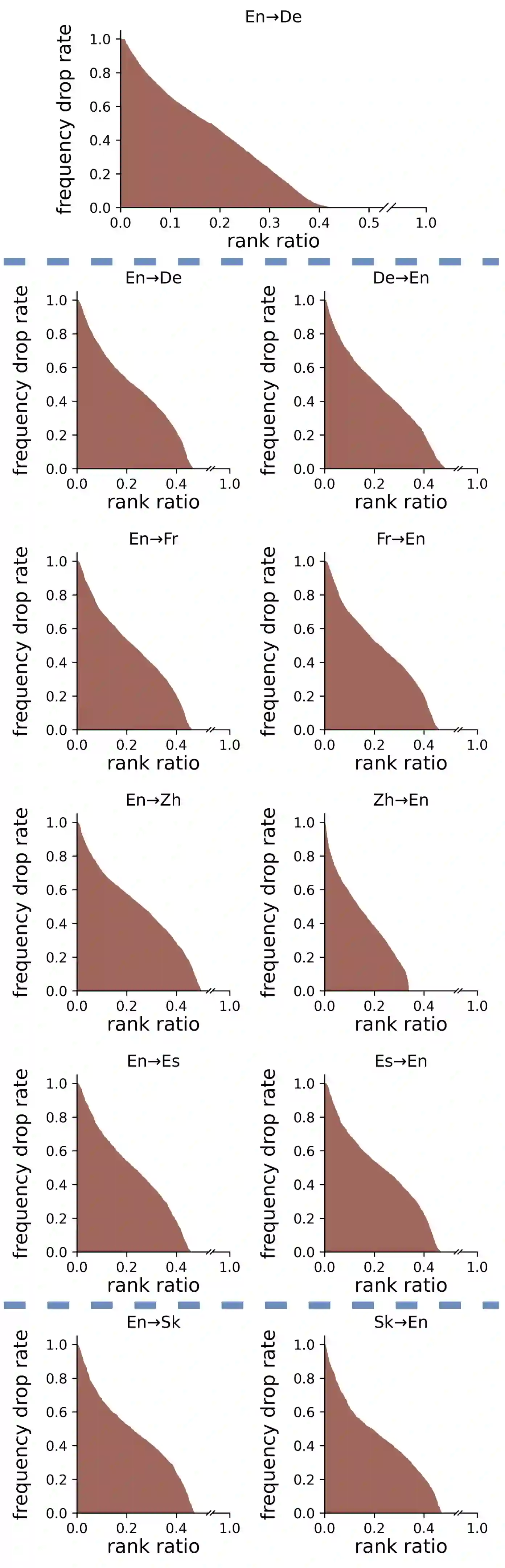
Data augmentation is an effective way to diversify corpora in machine translation, but previous methods may introduce semantic inconsistency between original and augmented data because of irreversible operations and random subword sampling procedures. To generate both symbolically diverse and semantically consistent augmentation data, we propose Deterministic Reversible Data Augmentation (DRDA), a simple but effective data augmentation method for neural machine translation. DRDA adopts deterministic segmentations and reversible operations to generate multi-granularity subword representations and pulls them closer together with multi-view techniques. With no extra corpora or model changes required, DRDA outperforms strong baselines on several translation tasks with a clear margin (up to 4.3 BLEU gain over Transformer) and exhibits good robustness in noisy, low-resource, and cross-domain datasets.
翻译:数据增强是机器翻译中扩充语料多样性的有效方法,但以往方法可能因不可逆操作和随机子词采样过程导致原始数据与增强数据间出现语义不一致。为生成符号多样且语义一致的增强数据,我们提出确定性可逆数据增强(DRDA),这是一种简单而有效的神经机器翻译数据增强方法。DRDA采用确定性分词和可逆操作生成多粒度子词表示,并通过多视图技术使它们相互靠近。该方法无需额外语料或模型改动,在多项翻译任务上以显著优势超越强基线模型(较Transformer最高提升4.3 BLEU值),并在噪声数据、低资源及跨领域数据集中展现出良好的鲁棒性。