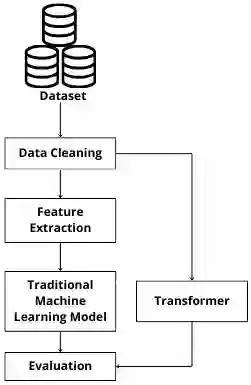
The identification of hope speech has become a promised NLP task, considering the need to detect motivational expressions of agency and goal-directed behaviour on social media platforms. This proposal evaluates traditional machine learning models and fine-tuned transformers for a previously split hope speech dataset as train, development and test set. On development test, a linear-kernel SVM and logistic regression both reached a macro-F1 of 0.78; SVM with RBF kernel reached 0.77, and Na\"ive Bayes hit 0.75. Transformer models delivered better results, the best model achieved weighted precision of 0.82, weighted recall of 0.80, weighted F1 of 0.79, macro F1 of 0.79, and 0.80 accuracy. These results suggest that while optimally configured traditional machine learning models remain agile, transformer architectures detect some subtle semantics of hope to achieve higher precision and recall in hope speech detection, suggesting that larges transformers and LLMs could perform better in small datasets.
翻译:希望言论的识别已成为一项备受关注的自然语言处理任务,这源于在社交媒体平台上检测具有能动性和目标导向行为的激励性表达的需求。本研究评估了传统机器学习模型与微调后的Transformer模型在一个预先划分为训练集、开发集和测试集的希望言论数据集上的表现。在开发集测试中,线性核支持向量机与逻辑回归模型的宏平均F1分数均达到0.78;采用径向基核函数的支持向量机得分为0.77,朴素贝叶斯模型为0.75。Transformer模型取得了更优的结果,最佳模型的加权精确率为0.82,加权召回率为0.80,加权F1分数为0.79,宏平均F1分数为0.79,准确率为0.80。这些结果表明,尽管经过优化配置的传统机器学习模型仍具灵活性,但Transformer架构能够捕捉希望言论中某些细微的语义特征,从而在检测中实现更高的精确率与召回率,这暗示大型Transformer模型及大语言模型在小型数据集上可能具有更优越的性能。