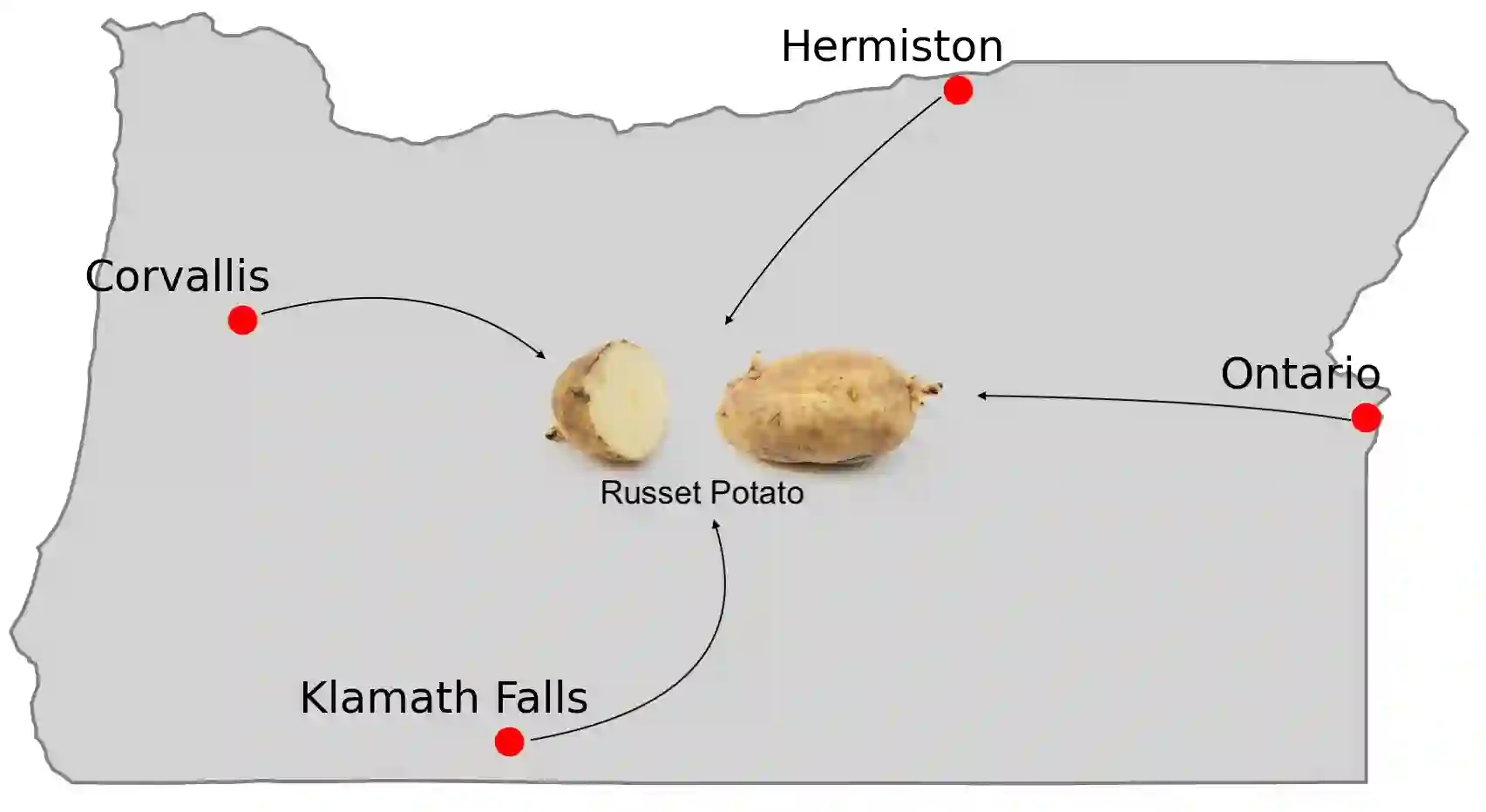
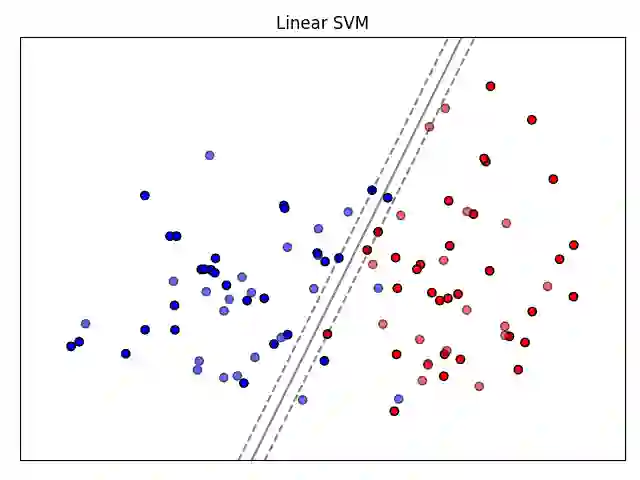
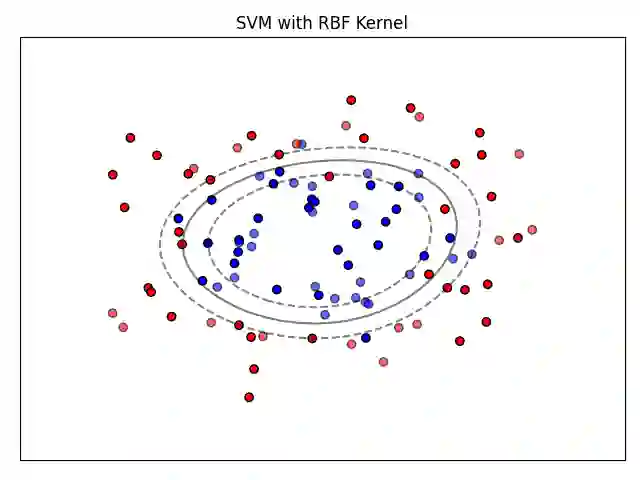
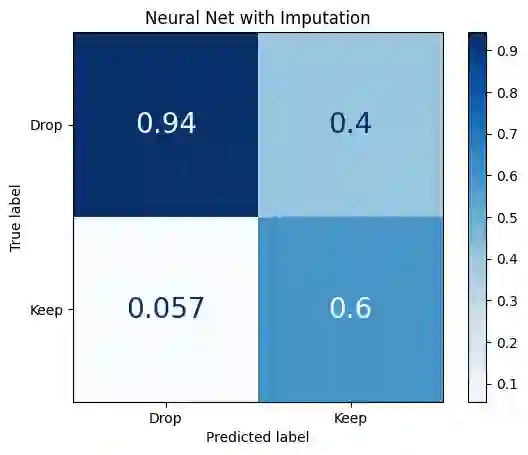
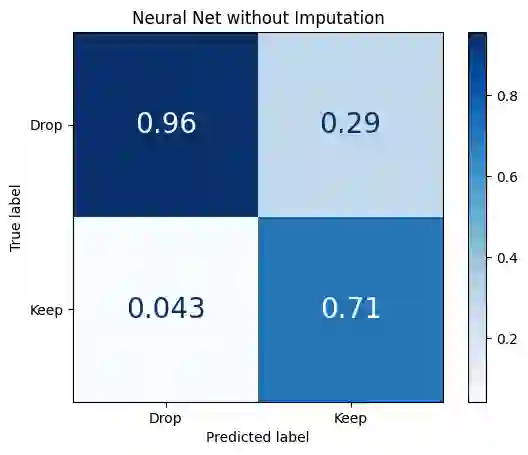
We explore the application of machine learning algorithms specifically to enhance the selection process of Russet potato clones in breeding trials by predicting their suitability for advancement. This study addresses the challenge of efficiently identifying high-yield, disease-resistant, and climate-resilient potato varieties that meet processing industry standards. Leveraging manually collected data from trials in the state of Oregon, we investigate the potential of a wide variety of state-of-the-art binary classification models. The dataset includes 1086 clones, with data on 38 attributes recorded for each clone, focusing on yield, size, appearance, and frying characteristics, with several control varieties planted consistently across four Oregon regions from 2013-2021. We conduct a comprehensive analysis of the dataset that includes preprocessing, feature engineering, and imputation to address missing values. We focus on several key metrics such as accuracy, F1-score, and Matthews correlation coefficient (MCC) for model evaluation. The top-performing models, namely a neural network classifier (Neural Net), histogram-based gradient boosting classifier (HGBC), and a support vector machine classifier (SVM), demonstrate consistent and significant results. To further validate our findings, we conduct a simulation study. By simulating different data-generating scenarios, we assess model robustness and performance through true positive, true negative, false positive, and false negative distributions, area under the receiver operating characteristic curve (AUC-ROC) and MCC. The simulation results highlight that non-linear models like SVM and HGBC consistently show higher AUC-ROC and MCC than logistic regression (LR), thus outperforming the traditional linear model across various distributions, and emphasizing the importance of model selection and tuning in agricultural trials.
翻译:本研究探索了机器学习算法在育种试验中通过预测其适宜性来优化Russet马铃薯克隆筛选过程的具体应用。该研究旨在应对高效识别符合加工行业标准的高产、抗病、气候适应性强的马铃薯品种的挑战。利用从俄勒冈州试验中手动收集的数据,我们研究了多种先进二元分类模型的潜力。数据集包含1086个克隆,每个克隆记录了38个属性数据,重点关注产量、大小、外观和油炸特性,其中多个对照品种在2013年至2021年间持续种植于俄勒冈州的四个区域。我们对数据集进行了全面分析,包括预处理、特征工程和缺失值插补。模型评估重点关注准确率、F1分数和马修斯相关系数等关键指标。性能最佳的模型,即神经网络分类器、基于直方图的梯度提升分类器以及支持向量机分类器,均展现出稳定且显著的结果。为进一步验证我们的发现,我们进行了一项模拟研究。通过模拟不同的数据生成场景,我们通过真阳性、真阴性、假阳性、假阴性分布、接收者操作特征曲线下面积和马修斯相关系数来评估模型的稳健性和性能。模拟结果表明,像支持向量机和基于直方图的梯度提升分类器这样的非线性模型,其接收者操作特征曲线下面积和马修斯相关系数始终高于逻辑回归,因此在各种分布下均优于传统的线性模型,这强调了在农业试验中进行模型选择和调优的重要性。