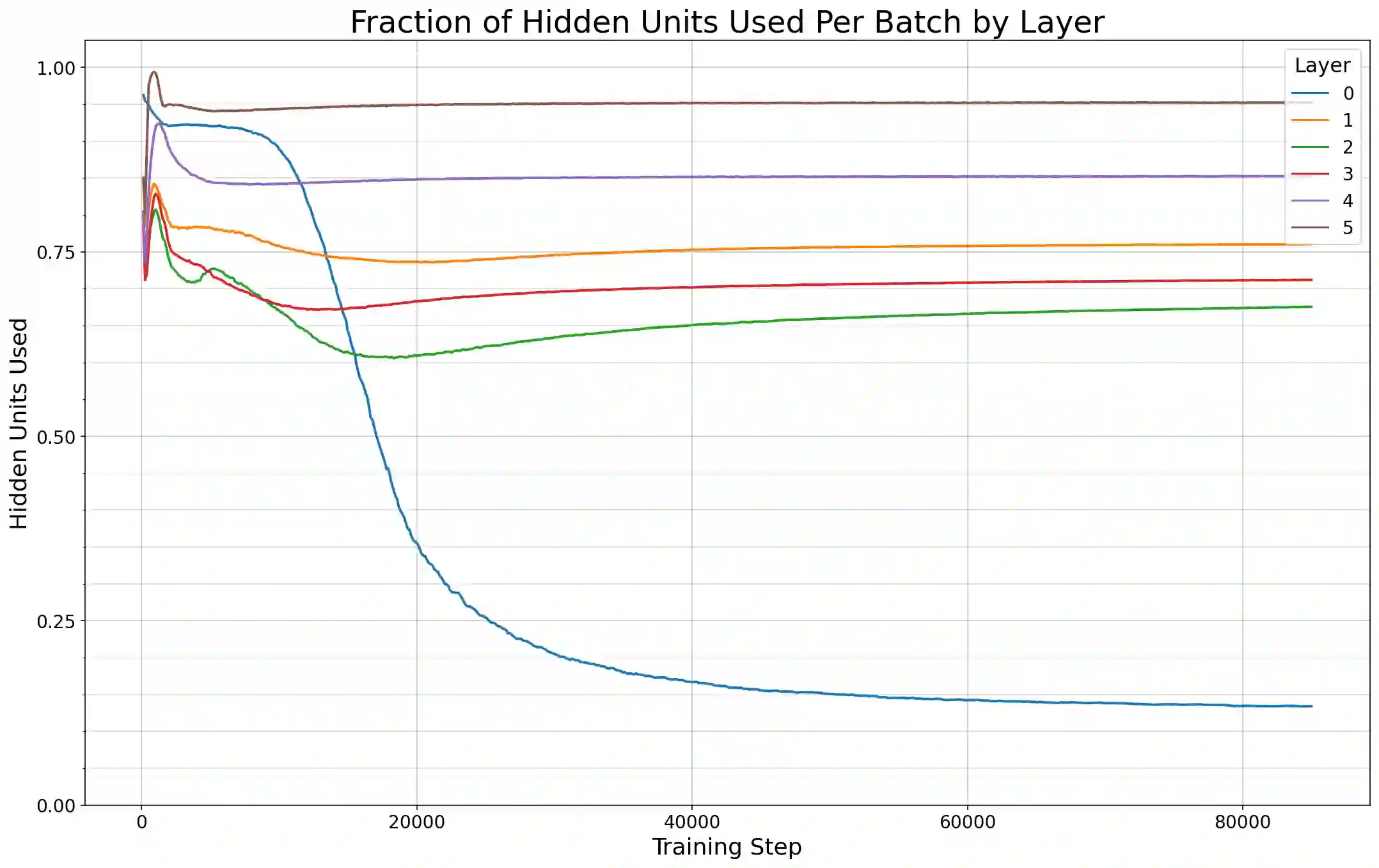
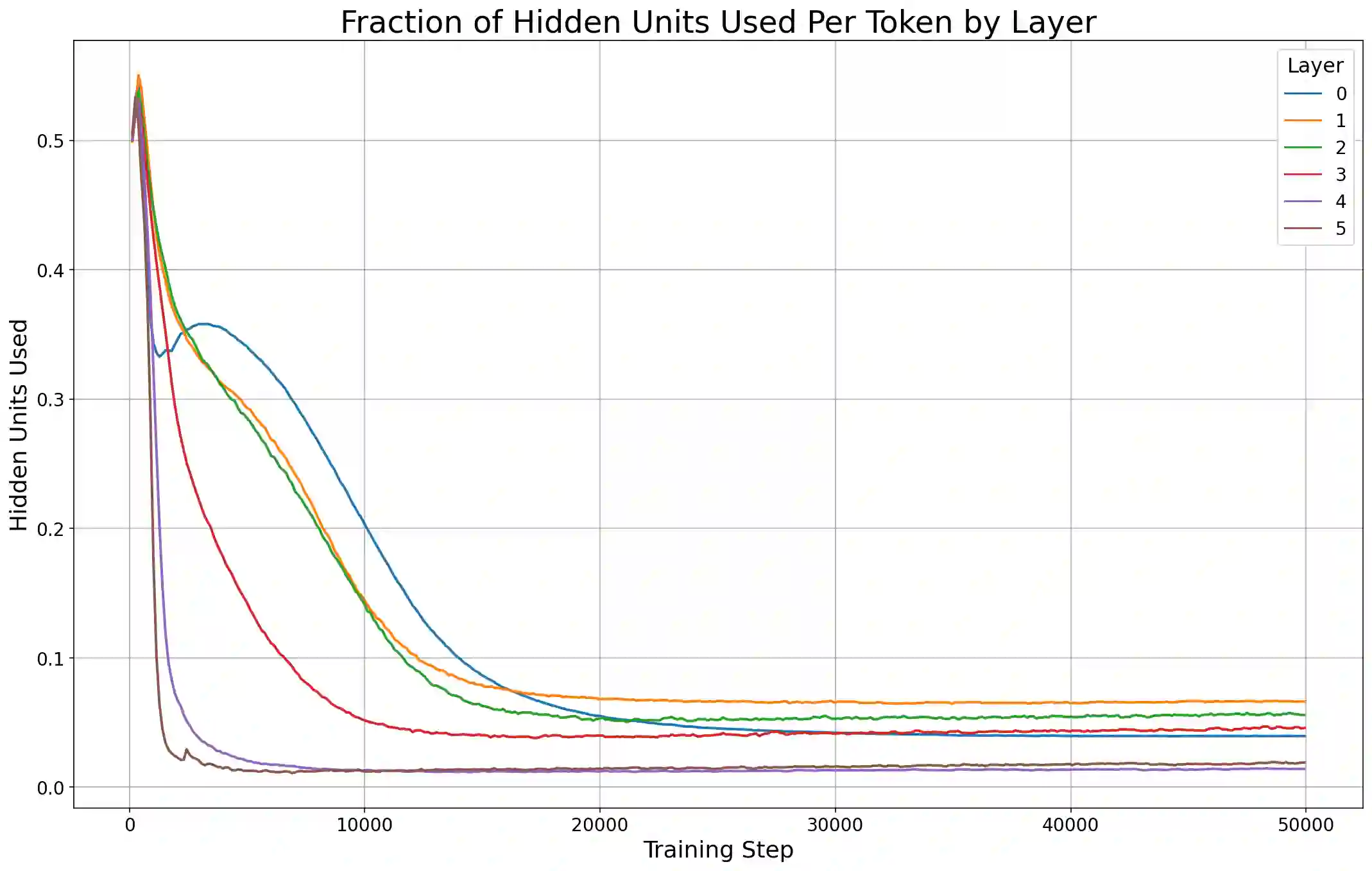
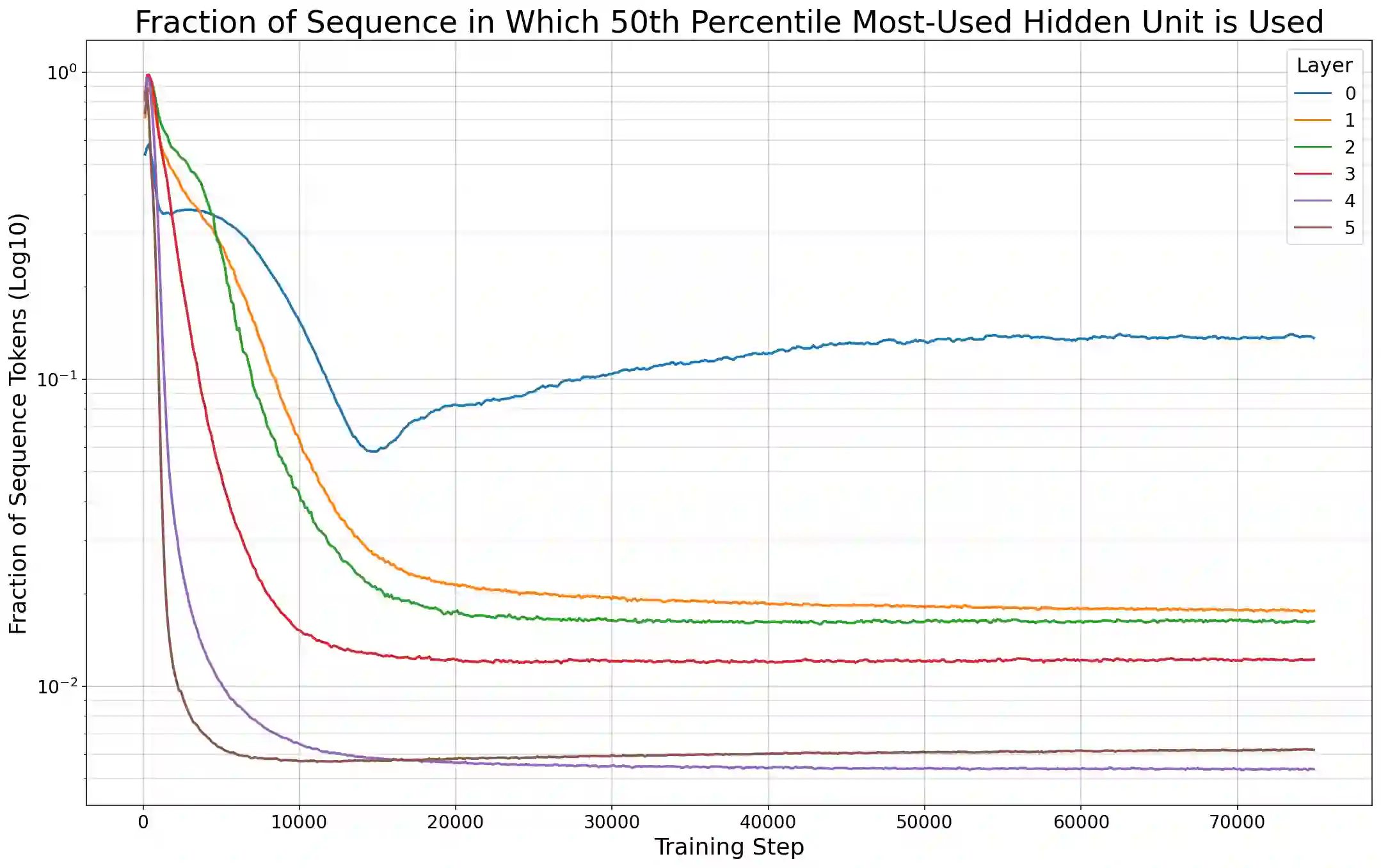
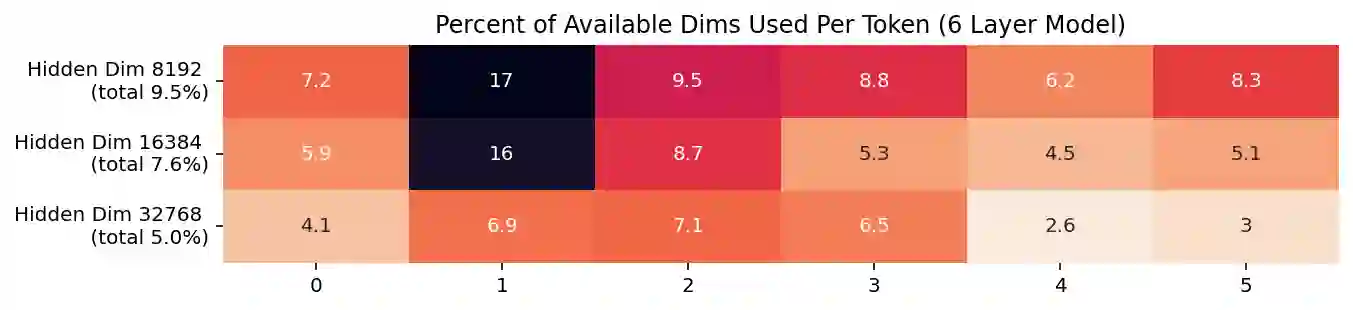
Previous work has demonstrated that MLPs within ReLU Transformers exhibit high levels of sparsity, with many of their activations equal to zero for any given token. We build on that work to more deeply explore how token-level sparsity evolves over the course of training, and how it connects to broader sparsity patterns over the course of a sequence or batch, demonstrating that the different layers within small transformers exhibit distinctly layer-specific patterns on both of these fronts. In particular, we demonstrate that the first and last layer of the network have distinctive and in many ways inverted relationships to sparsity, and explore implications for the structure of feature representations being learned at different depths of the model. We additionally explore the phenomenon of ReLU dimensions "turning off", and show evidence suggesting that "neuron death" is being primarily driven by the dynamics of training, rather than simply occurring randomly or accidentally as a result of outliers.
翻译:先前的研究表明,ReLU Transformer中的多层感知机表现出高度的稀疏性,对于任意给定词元,其多数激活值均为零。本研究在此基础上更深入地探讨了词元级稀疏性在训练过程中的演变规律,以及其如何与序列或批次层面的整体稀疏模式相关联,并证明小型Transformer中不同层级在这两个维度上均表现出明显的层级特异性模式。具体而言,我们论证了网络首尾层与稀疏性存在独特且多维度倒置的关联关系,并探讨了模型不同深度所学习特征表示结构的影响。此外,我们研究了ReLU维度"关闭"现象,并提供证据表明"神经元死亡"主要受训练动态驱动,而非单纯由异常值随机或偶然引发。