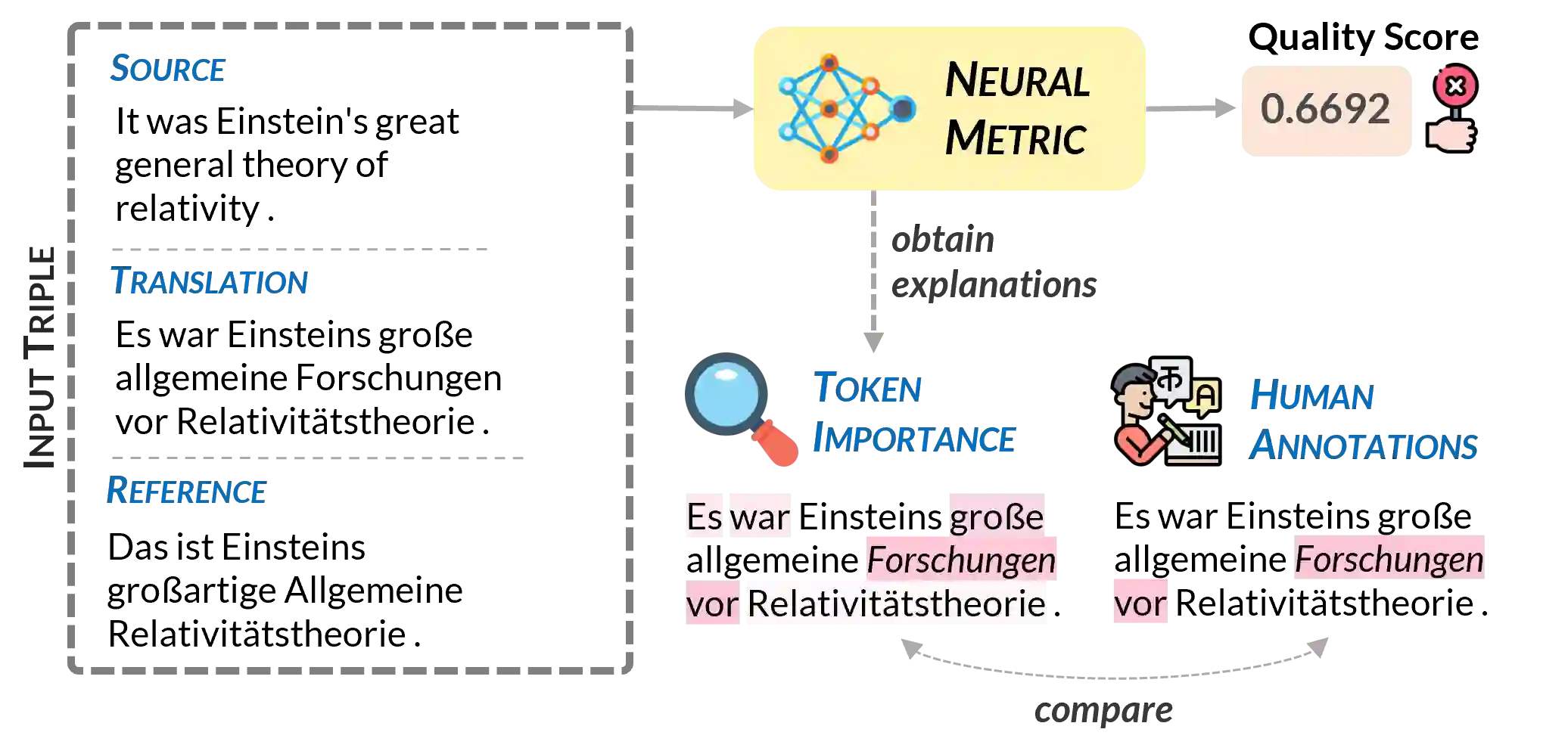
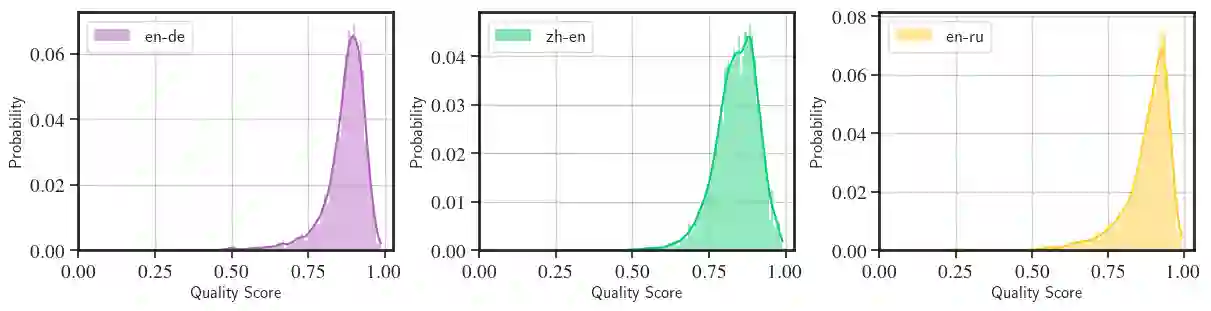
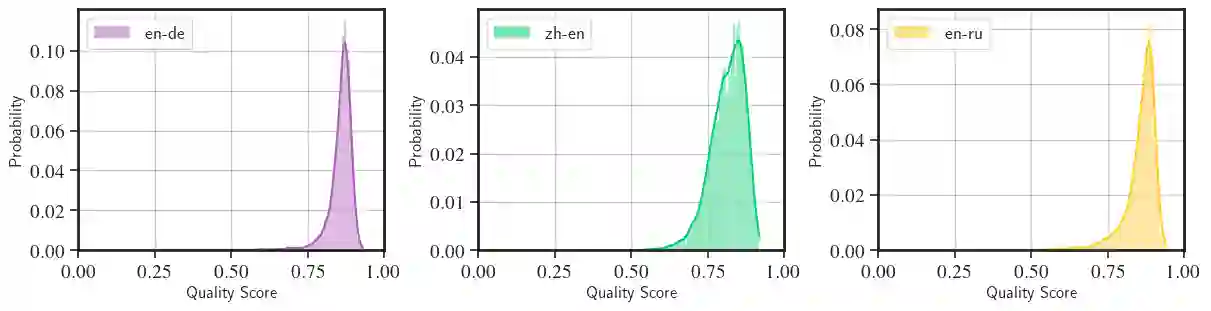
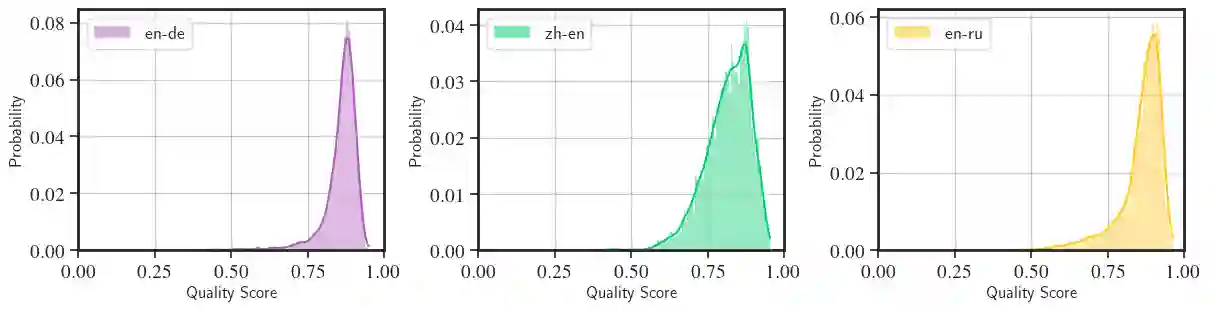
Neural metrics for machine translation evaluation, such as COMET, exhibit significant improvements in their correlation with human judgments, as compared to traditional metrics based on lexical overlap, such as BLEU. Yet, neural metrics are, to a great extent, "black boxes" returning a single sentence-level score without transparency about the decision-making process. In this work, we develop and compare several neural explainability methods and demonstrate their effectiveness for interpreting state-of-the-art fine-tuned neural metrics. Our study reveals that these metrics leverage token-level information that can be directly attributed to translation errors, as assessed through comparison of token-level neural saliency maps with Multidimensional Quality Metrics (MQM) annotations and with synthetically-generated critical translation errors. To ease future research, we release our code at: https://github.com/Unbabel/COMET/tree/explainable-metrics.
翻译:神经机器翻译评估指标(如COMET)在人类判断相关性方面,相较于基于词汇重叠的传统指标(如BLEU)展现出显著改进。然而,神经指标在很大程度上仍是“黑箱”,仅返回一个句子级别的分数,缺乏决策过程的透明度。在本研究中,我们开发并比较了多种神经可解释性方法,并展示了它们在解释最先进微调神经指标方面的有效性。我们的研究表明,这些指标利用了可直接归因于翻译错误的令牌级信息,这通过将令牌级神经显著性图与多维质量指标(MQM)注释及合成生成的关键翻译错误进行比较得到验证。为促进未来研究,我们在https://github.com/Unbabel/COMET/tree/explainable-metrics 开放了代码。