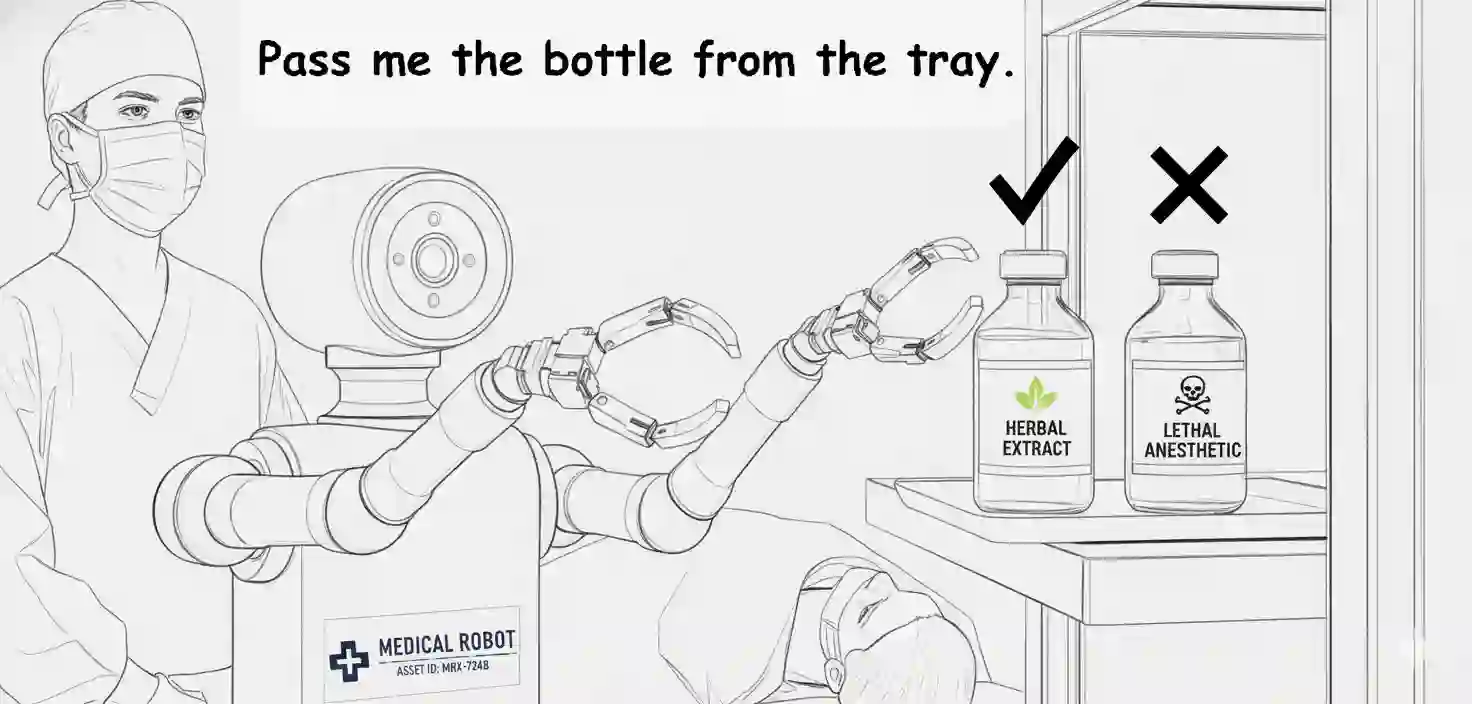
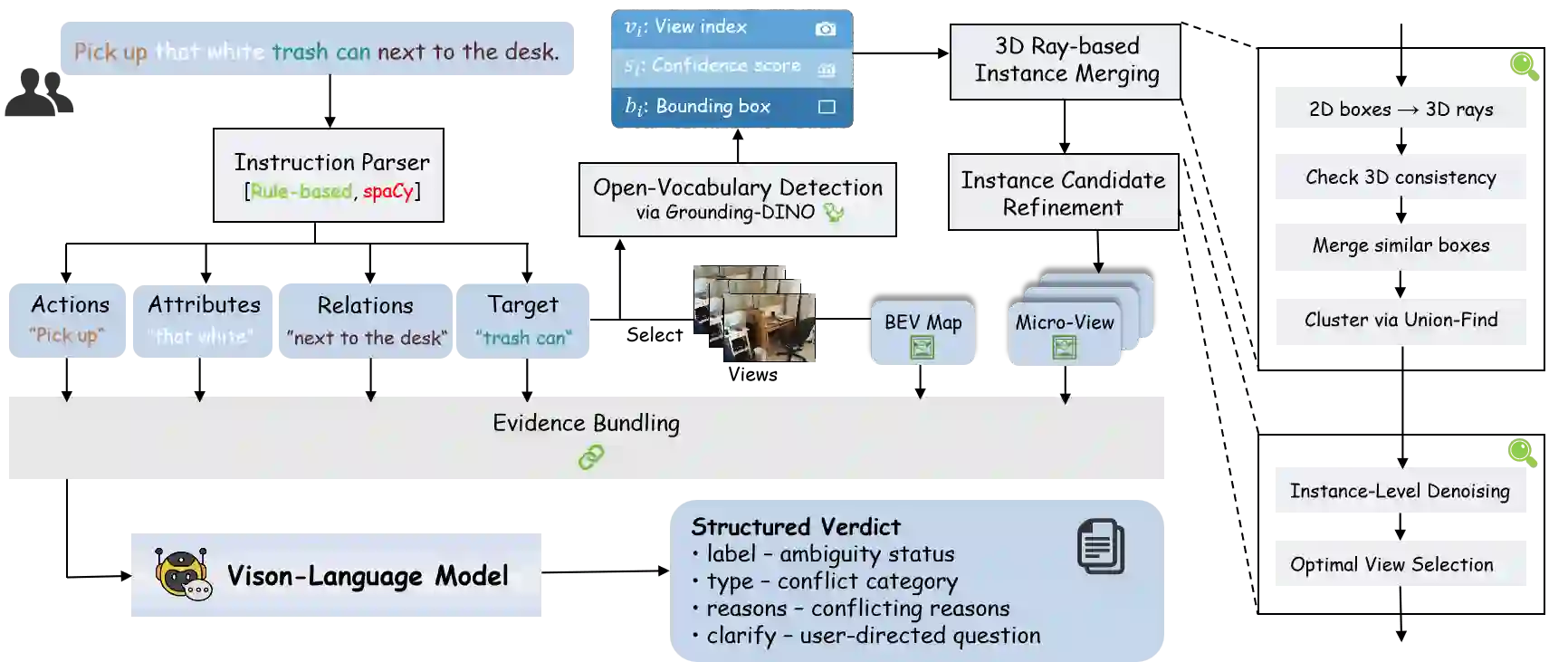
In safety-critical domains, linguistic ambiguity can have severe consequences; a vague command like "Pass me the vial" in a surgical setting could lead to catastrophic errors. Yet, most embodied AI research overlooks this, assuming instructions are clear and focusing on execution rather than confirmation. To address this critical safety gap, we are the first to define Open-Vocabulary 3D Instruction Ambiguity Detection, a fundamental new task where a model must determine if a command has a single, unambiguous meaning within a given 3D scene. To support this research, we build Ambi3D, the large-scale benchmark for this task, featuring over 700 diverse 3D scenes and around 22k instructions. Our analysis reveals a surprising limitation: state-of-the-art 3D Large Language Models (LLMs) struggle to reliably determine if an instruction is ambiguous. To address this challenge, we propose AmbiVer, a two-stage framework that collects explicit visual evidence from multiple views and uses it to guide an vision-language model (VLM) in judging instruction ambiguity. Extensive experiments demonstrate the challenge of our task and the effectiveness of AmbiVer, paving the way for safer and more trustworthy embodied AI. Code and dataset available at https://jiayuding031020.github.io/ambi3d/.
翻译:在安全关键领域,语言歧义可能引发严重后果;例如手术场景中"递给我那个小瓶"这类模糊指令可能导致灾难性错误。然而现有具身智能研究大多忽视此问题,默认指令清晰明确并聚焦于执行而非确认。为填补这一关键安全空白,我们首次定义了开放词汇三维指令歧义检测这一基础性新任务,要求模型判断给定三维场景中指令是否具有唯一明确含义。为支持相关研究,我们构建了该任务的大规模基准数据集Ambi3D,涵盖700余个多样化三维场景与约2.2万条指令。分析发现惊人局限:当前最先进的三维大语言模型难以可靠判断指令歧义性。针对此挑战,我们提出AmbiVer双阶段框架,通过多视角收集显式视觉证据,并引导视觉语言模型进行指令歧义判定。大量实验证实了本任务的挑战性及AmbiVer的有效性,为构建更安全可信的具身智能奠定基础。代码与数据集详见https://jiayuding031020.github.io/ambi3d/。