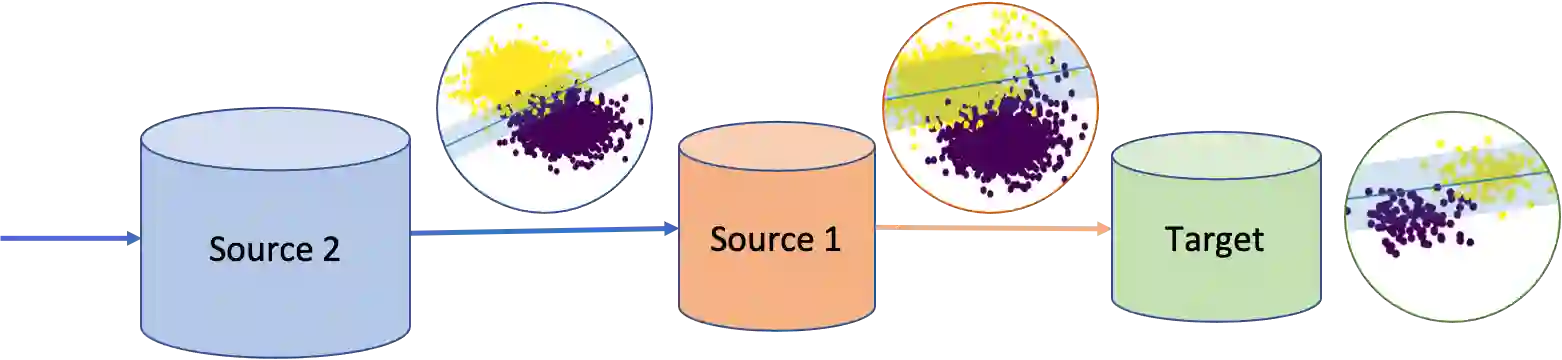
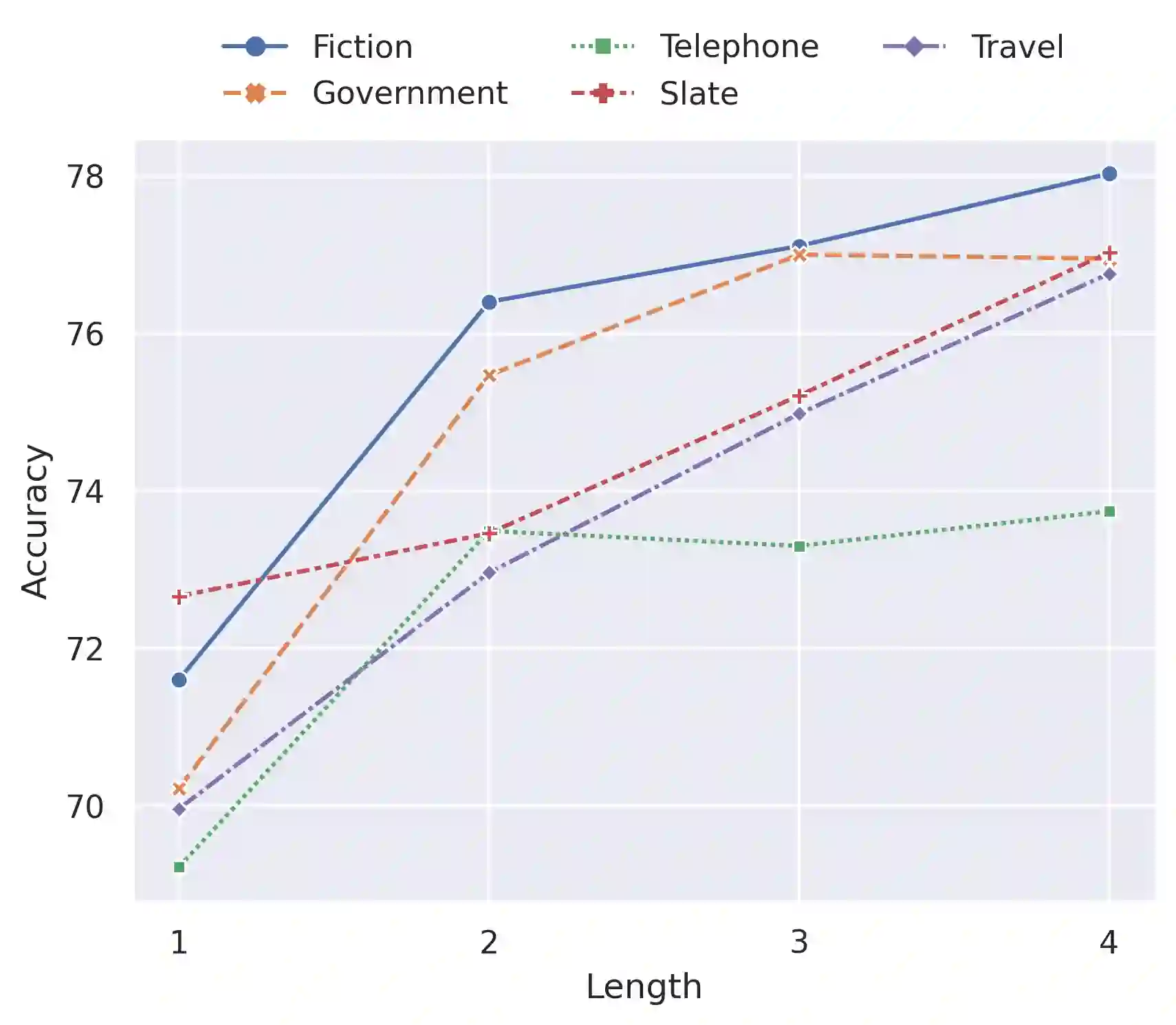
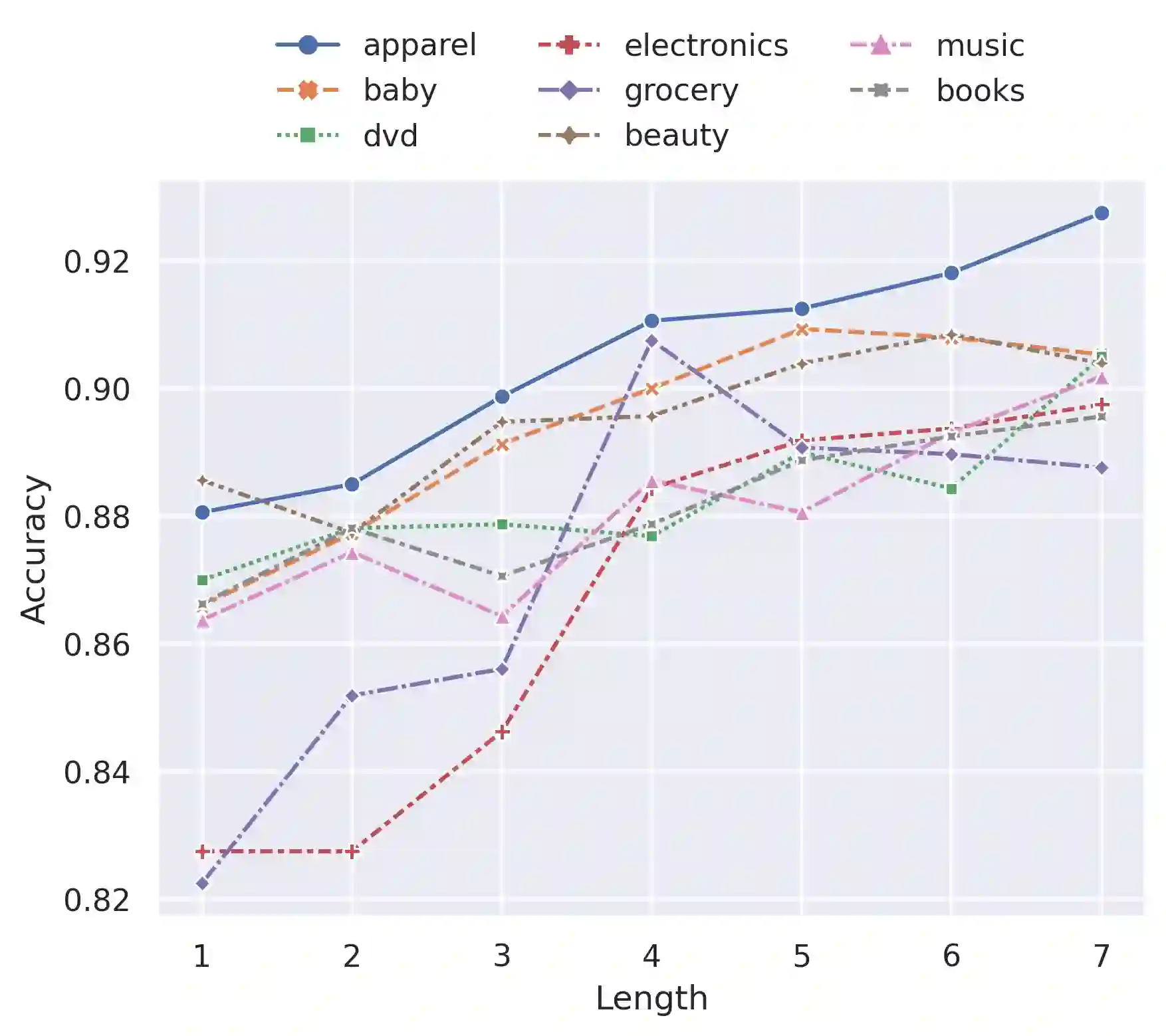
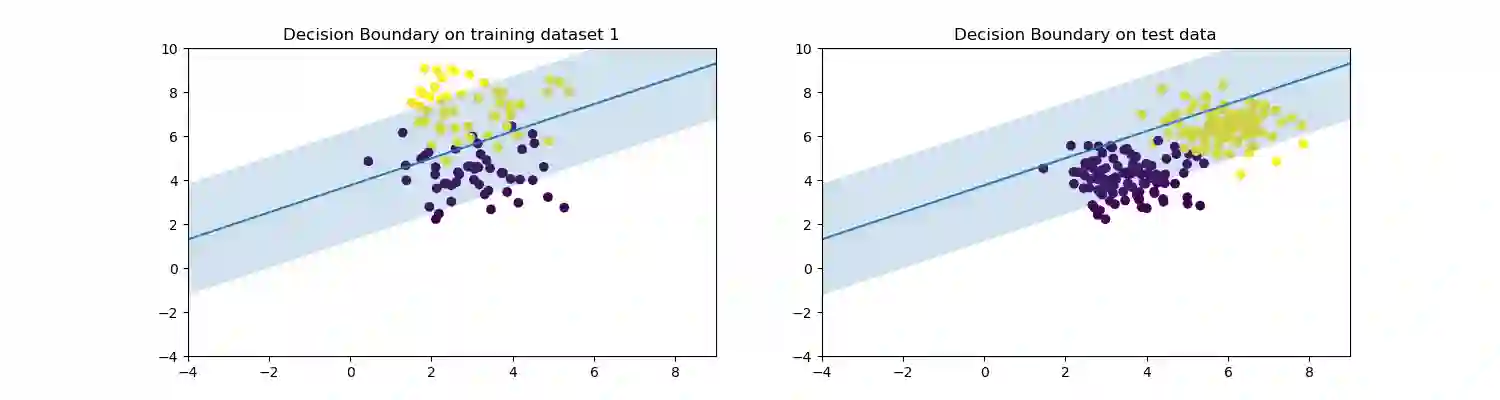
Multi-source unsupervised domain adaptation aims to leverage labeled data from multiple source domains for training a machine learning model to generalize well on a target domain without labels. Source domain selection plays a crucial role in determining the model's performance. It relies on the similarities amongst source and target domains. Nonetheless, existing work for source domain selection often involves heavyweight computational procedures, especially when dealing with numerous source domains and the need to identify the best ones from them. In this paper, we introduce a framework for gradual fine tuning (GFT) of machine learning models on multiple source domains. We represent multiple source domains as an undirected weighted graph. We then give a new generalization error bound for GFT along any path within the graph, which is used to determine the optimal path corresponding to the optimal training order. With this formulation, we introduce three lightweight graph-routing strategies which tend to minimize the error bound. Our best strategy improves $2.3\%$ of accuracy over the state-of-the-art on Natural Language Inference (NLI) task and achieves competitive performance on Sentiment Analysis (SA) task, especially a $3.9\%$ improvement on a more diverse subset of data we use for SA.
翻译:多源无监督域自适应旨在利用来自多个源域的标记数据训练机器学习模型,使其能在无标记的目标域上取得良好的泛化性能。源域选择对模型性能具有决定性影响,其依据是源域与目标域之间的相似性。然而,现有的源域选择方法通常涉及高计算复杂度的流程,尤其在处理大量源域并需从中筛选最优域时更为突出。本文提出一种在多源域上对机器学习模型进行渐进式微调(GFT)的框架。我们将多个源域表示为无向加权图,进而给出GFT沿图中任意路径的泛化误差新上界,该上界用于确定对应最优训练顺序的最优路径。基于此理论框架,我们提出三种轻量级图路由策略,以最小化误差上界为目标。在自然语言推理(NLI)任务中,我们提出的最优策略相比现有最优方法准确率提升2.3%;在情感分析(SA)任务中取得具有竞争力的性能,特别是在我们为SA构建的更具多样性的数据子集上实现了3.9%的性能提升。