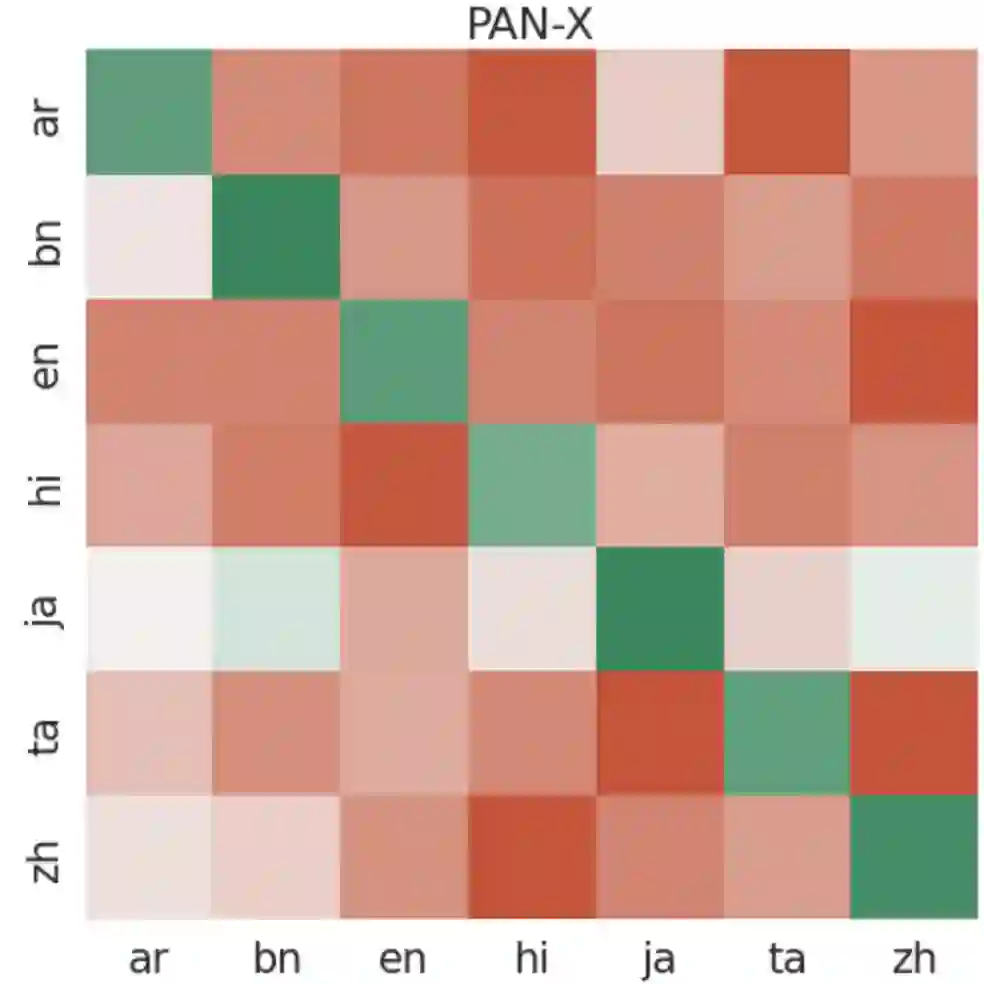
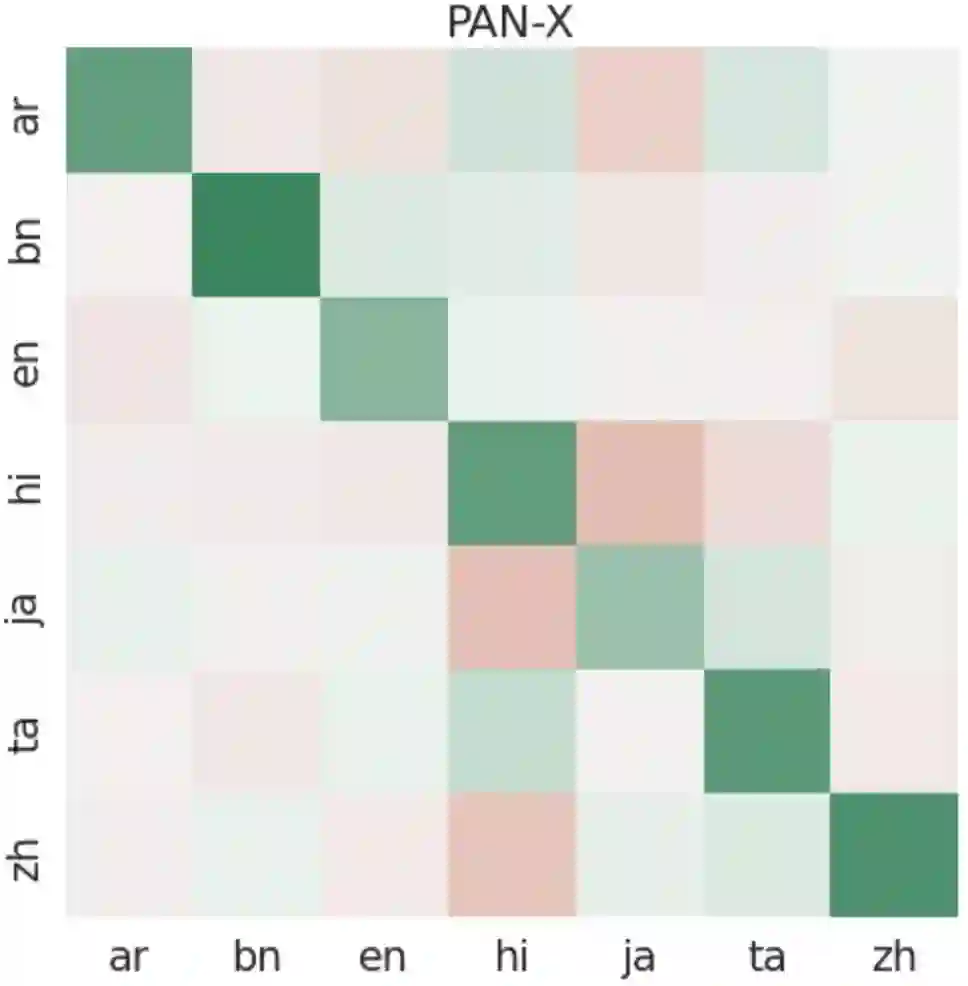
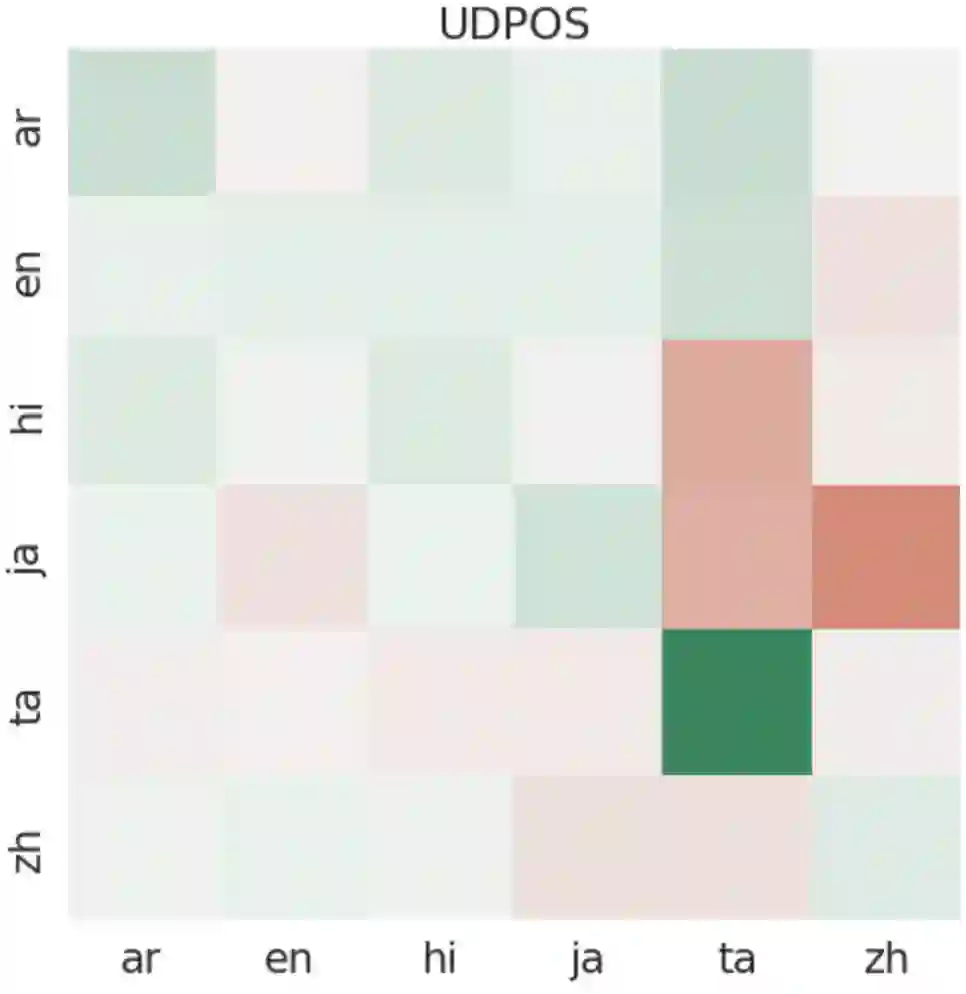
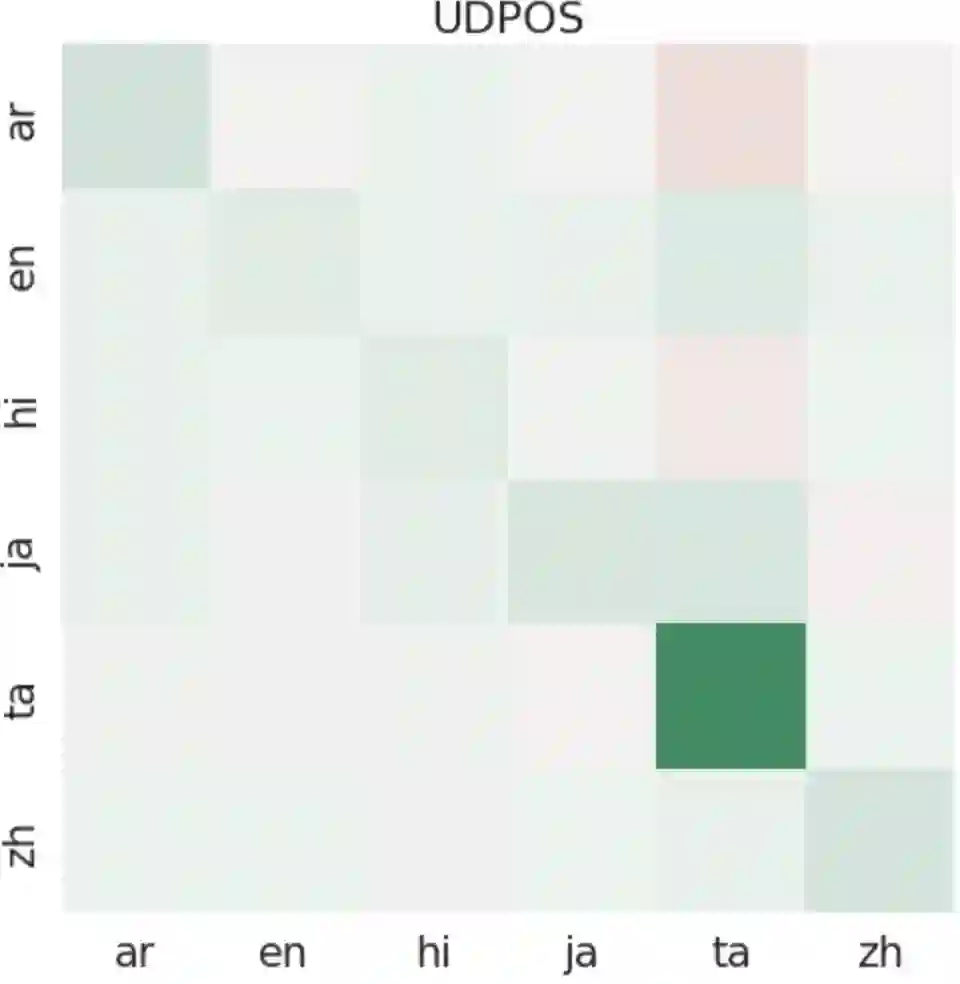
We introduce and study the problem of Continual Multilingual Learning (CML) where a previously trained multilingual model is periodically updated using new data arriving in stages. If the new data is present only in a subset of languages, we find that the resulting model shows improved performance only on the languages included in the latest update (and a few closely related languages) while its performance on all the remaining languages degrade significantly. We address this challenge by proposing LAFT-URIEL, a parameter-efficient finetuning strategy which aims to increase the number of languages on which the model improves after an update, while reducing the magnitude of loss in performance for the remaining languages. LAFT-URIEL uses linguistic knowledge to balance overfitting and knowledge sharing across languages, allowing for an additional 25% of task languages to see an improvement in performance after an update, while also reducing the average magnitude of losses on the remaining languages by 78% relative.
翻译:我们提出并研究了持续多语言学习(CML)问题,即预先训练的多语言模型需定期使用分阶段到达的新数据进行更新。当新数据仅存在于部分语言中时,我们发现更新后的模型仅在这些语言(及少数密切相关的语言)上性能提升,而在其余所有语言上的性能显著下降。为应对这一挑战,我们提出了LAFT-URIEL——一种参数高效微调策略,旨在增加更新后性能提升的语言数量,同时降低其余语言性能损失的幅度。LAFT-URIEL利用语言学知识平衡跨语言的过拟合与知识共享,使得更新后额外25%的任务语言性能得到提升,同时将剩余语言的平均损失幅度相对降低78%。