
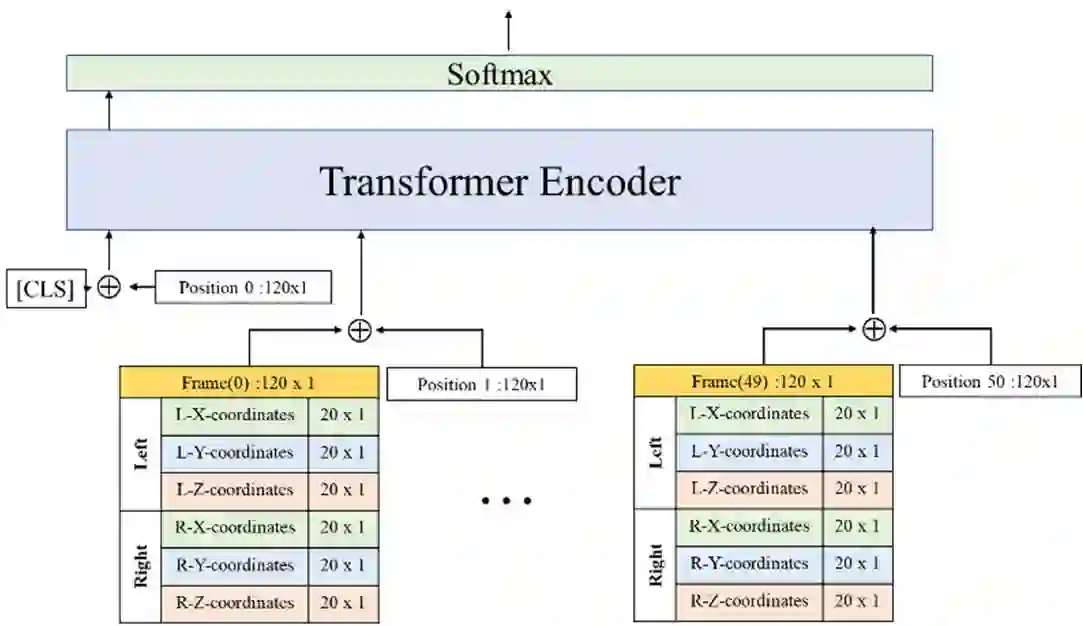
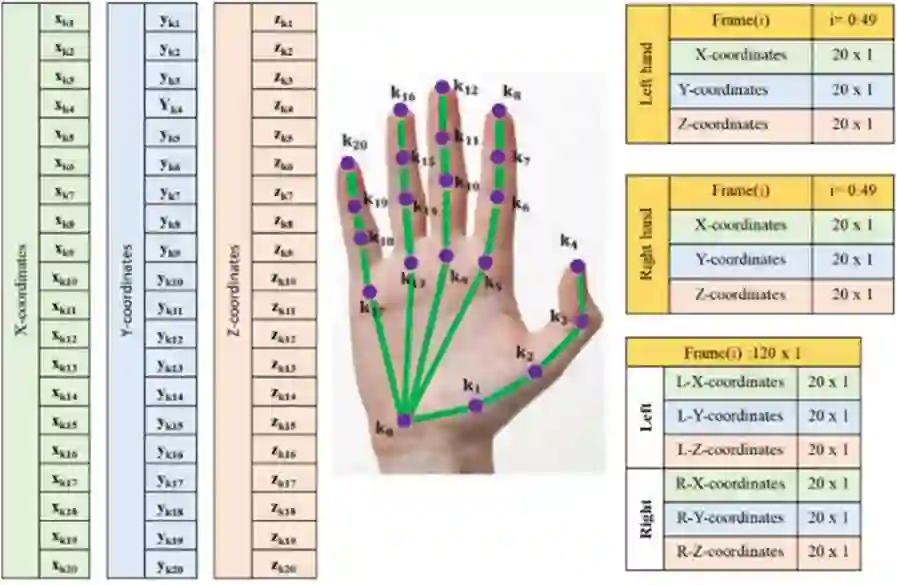
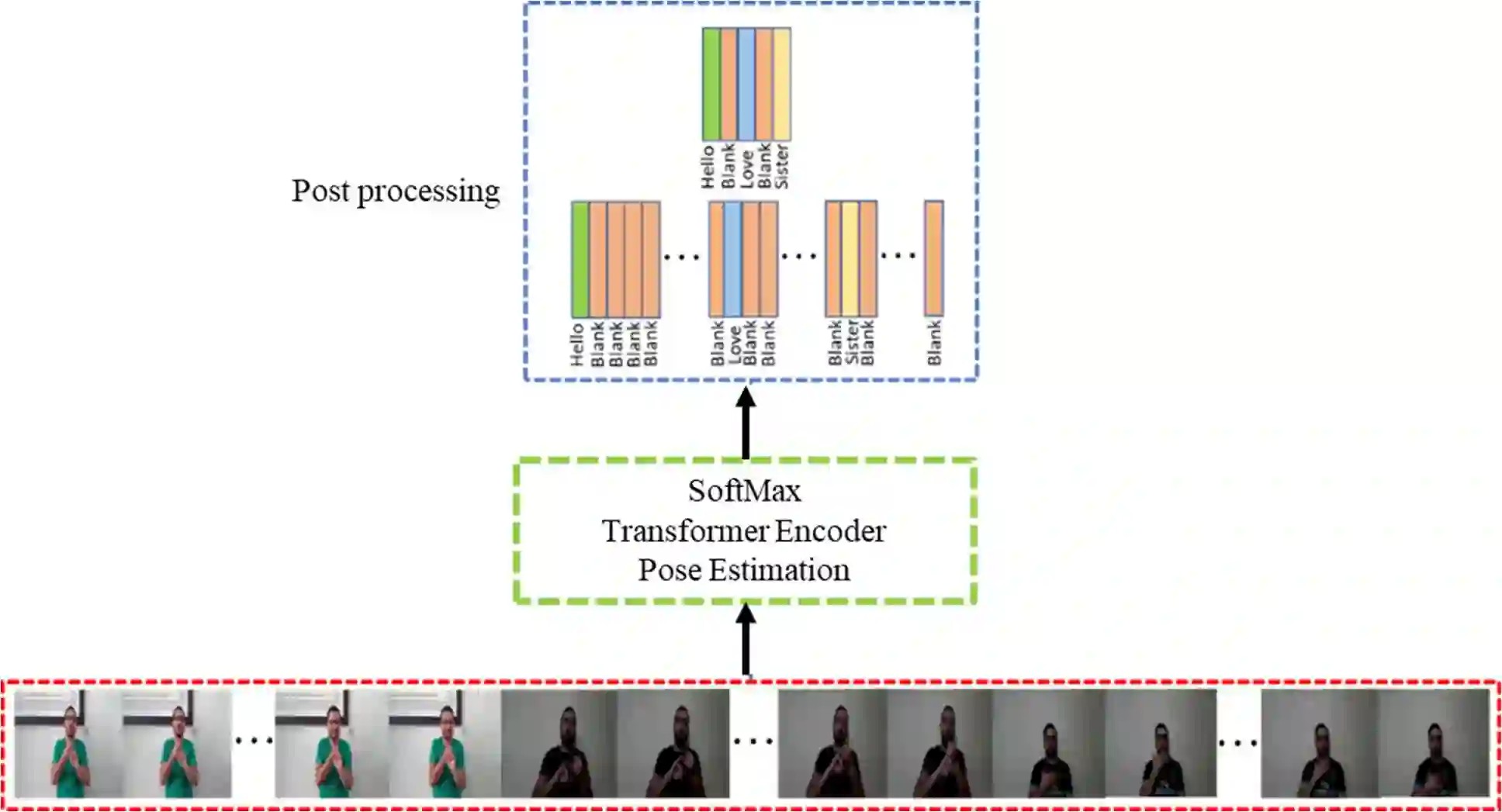
Sign Language Recognition (SLR) has garnered significant attention from researchers in recent years, particularly the intricate domain of Continuous Sign Language Recognition (CSLR), which presents heightened complexity compared to Isolated Sign Language Recognition (ISLR). One of the prominent challenges in CSLR pertains to accurately detecting the boundaries of isolated signs within a continuous video stream. Additionally, the reliance on handcrafted features in existing models poses a challenge to achieving optimal accuracy. To surmount these challenges, we propose a novel approach utilizing a Transformer-based model. Unlike traditional models, our approach focuses on enhancing accuracy while eliminating the need for handcrafted features. The Transformer model is employed for both ISLR and CSLR. The training process involves using isolated sign videos, where hand keypoint features extracted from the input video are enriched using the Transformer model. Subsequently, these enriched features are forwarded to the final classification layer. The trained model, coupled with a post-processing method, is then applied to detect isolated sign boundaries within continuous sign videos. The evaluation of our model is conducted on two distinct datasets, including both continuous signs and their corresponding isolated signs, demonstrates promising results.
翻译:近年来,手语识别(SLR)研究受到广泛关注,其中连续手语识别(CSLR)因其相较于孤立手语识别(ISLR)更高的复杂度成为关键研究领域。CSLR面临的主要挑战之一是如何在连续视频流中准确检测孤立手语的边界。此外,现有模型对人工设计特征的依赖也制约了识别精度的提升。为解决上述问题,我们提出了一种基于Transformer模型的新型方法。与传统模型不同,本方法在提升精度的同时消除了对人工设计特征的依赖。该Transformer模型同时应用于ISLR与CSLR任务。训练阶段采用孤立手语视频,通过Transformer模型对输入视频提取的手部关键点特征进行增强,随后将增强特征送入最终分类层。训练后的模型结合后处理方法,可有效检测连续手语视频中孤立手语的边界。在两个包含连续手语及其对应孤立手语的数据集上的评估结果表明,本方法取得了显著成效。


相关内容

Source: Apple - iOS 8


