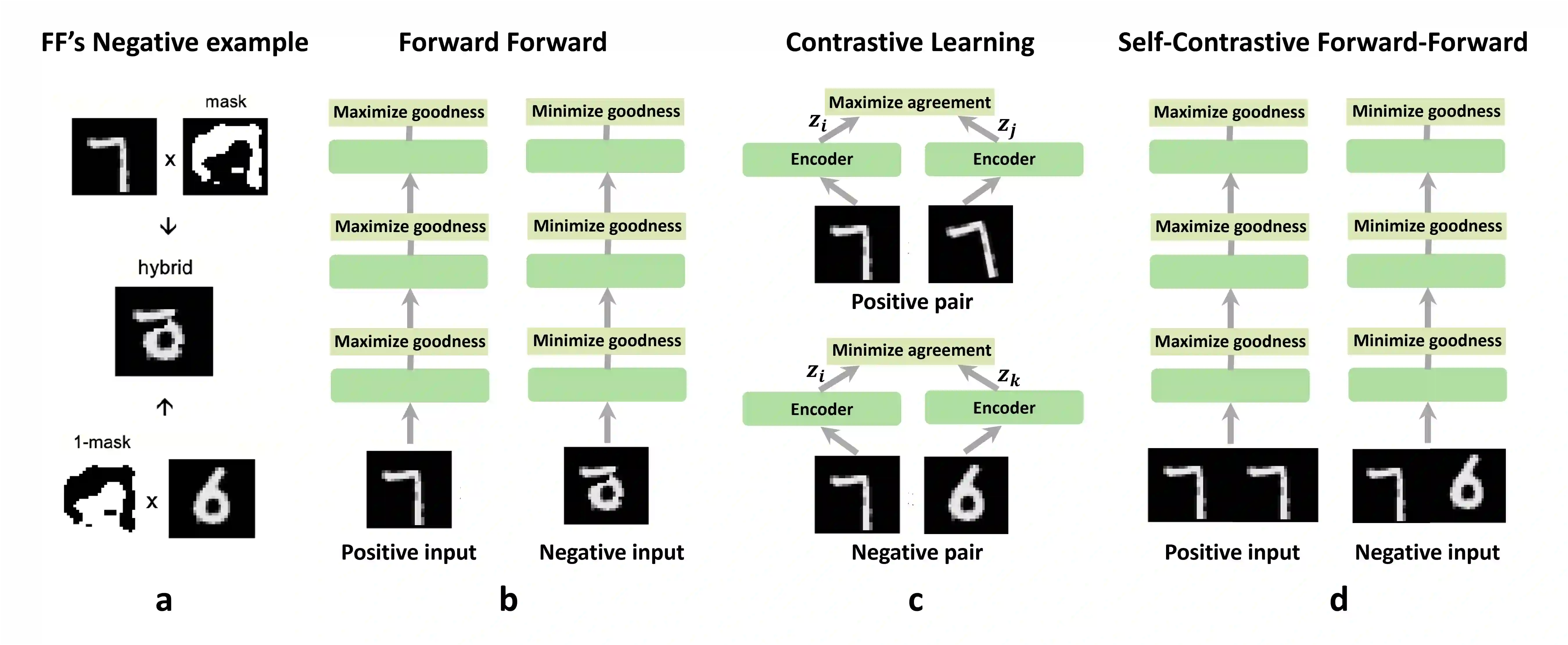
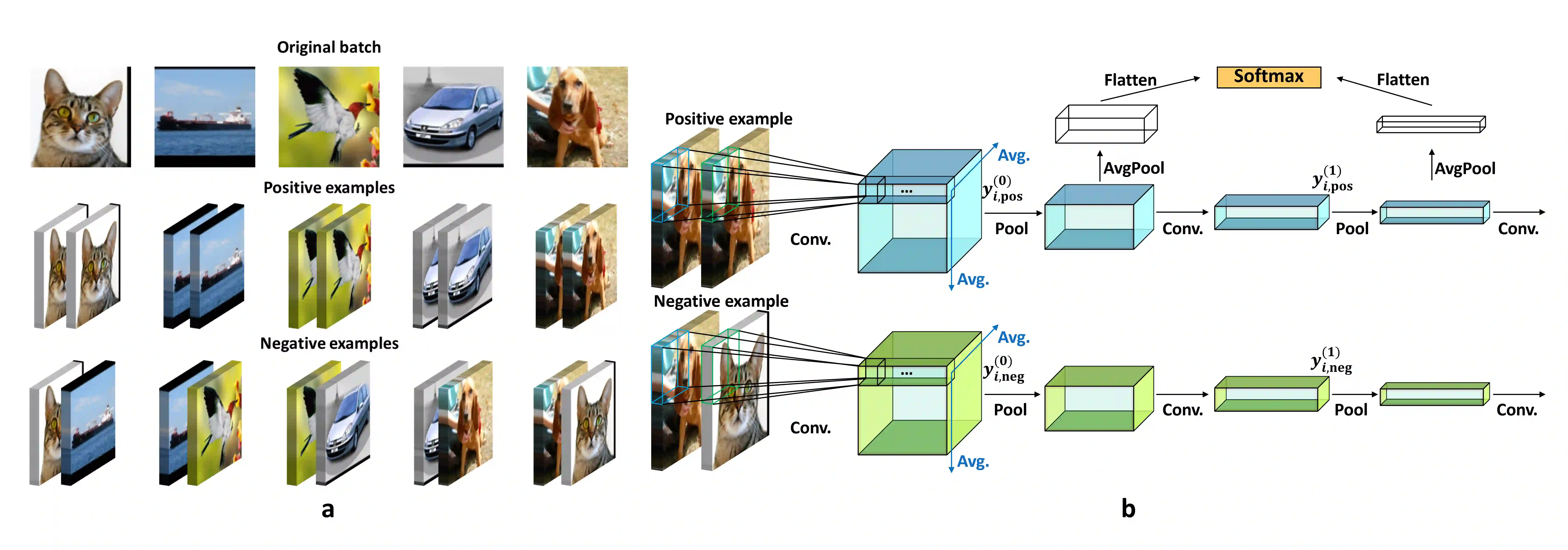
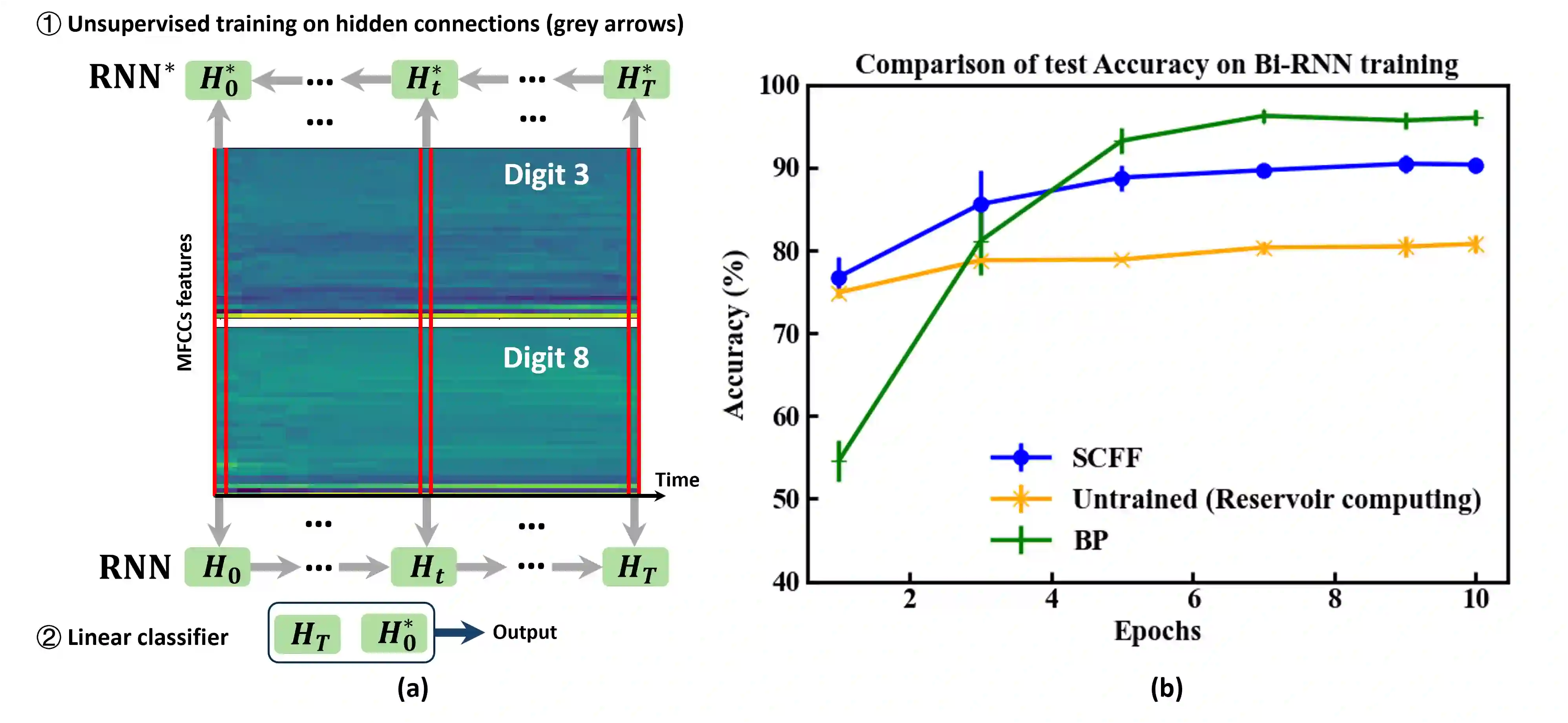
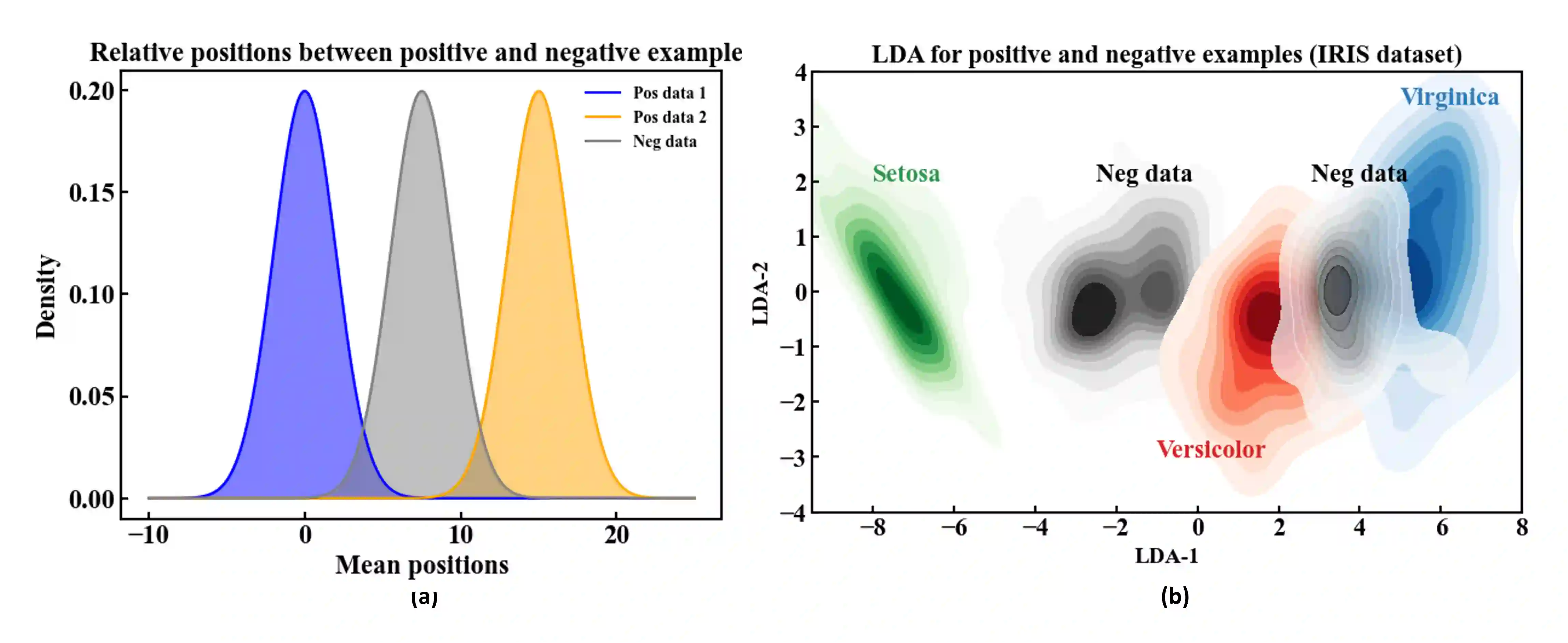
Agents that operate autonomously benefit from lifelong learning capabilities. However, compatible training algorithms must comply with the decentralized nature of these systems, which imposes constraints on both the parameter counts and the computational resources. The Forward-Forward (FF) algorithm is one of these. FF relies only on feedforward operations, the same used for inference, for optimizing layer-wise objectives. This purely forward approach eliminates the need for transpose operations required in traditional backpropagation. Despite its potential, FF has failed to reach state-of-the-art performance on most standard benchmark tasks, in part due to unreliable negative data generation methods for unsupervised learning. In this work, we propose the Self-Contrastive Forward-Forward (SCFF) algorithm, a competitive training method aimed at closing this performance gap. Inspired by standard self-supervised contrastive learning for vision tasks, SCFF generates positive and negative inputs applicable across various datasets. The method demonstrates superior performance compared to existing unsupervised local learning algorithms on several benchmark datasets, including MNIST, CIFAR-10, STL-10, and Tiny ImageNet. We extend FF's application to training recurrent neural networks, expanding its utility to sequential data tasks. These findings pave the way for high-accuracy, real-time learning on resource-constrained edge devices.
翻译:自主运行的智能体受益于终身学习能力。然而,兼容的训练算法必须符合这些系统的去中心化特性,这对参数数量和计算资源都施加了约束。前向-前向算法正是其中之一。该算法仅依赖前馈操作(与推理过程相同)来优化逐层目标函数。这种纯粹的前向方法消除了传统反向传播所需的转置运算。尽管具有潜力,前向-前向算法在多数标准基准任务中尚未达到最先进性能,部分原因在于无监督学习的负样本生成方法不可靠。本研究提出自对比前向-前向算法,这是一种旨在缩小性能差距的竞争性训练方法。受视觉任务中标准自监督对比学习的启发,该方法能生成适用于多种数据集的正面与负面输入。在包括MNIST、CIFAR-10、STL-10和Tiny ImageNet在内的多个基准数据集上,本方法展现出优于现有无监督局部学习算法的性能。我们将前向-前向算法扩展至循环神经网络的训练,从而将其适用性拓展至序列数据任务。这些发现为在资源受限的边缘设备上实现高精度实时学习开辟了道路。