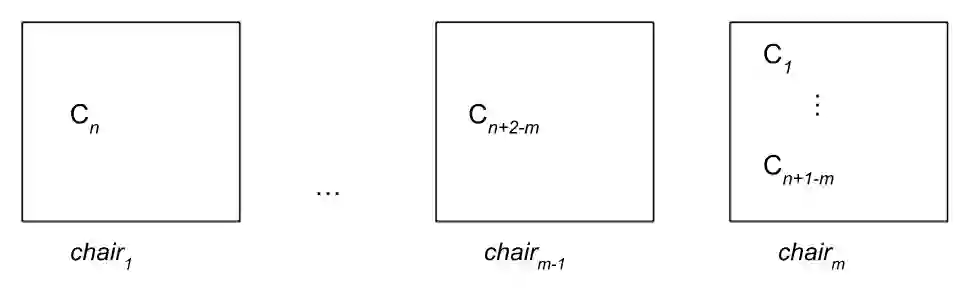
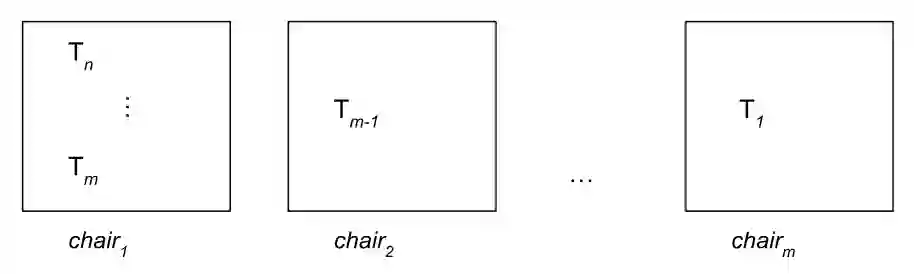
This paper presents a new contribution to the problem of AI evaluation. Much as one might evaluate a machine in terms of its performance at chess, this approach involves evaluating a machine in terms of its performance at a game called "MAD Chairs." At the time of writing, evaluation with this game exposed opportunities to improve Claude, Gemini, ChatGPT, Qwen and DeepSeek. Furthermore, this paper sets a stage for future innovation in game theory and AI safety by providing an example of success with non-standard approaches to each: studying a game beyond the scope of previous game theoretic tools and mitigating a serious AI safety risk in a way that requires neither determination of values nor their enforcement.
翻译:本文针对人工智能评估问题提出了一项新贡献。正如人们可以通过机器在国际象棋中的表现来评估其能力,该方法通过机器在一款名为“MAD Chairs”游戏中的表现进行评估。截至本文撰写时,利用该游戏进行的评估揭示了改进Claude、Gemini、ChatGPT、Qwen和DeepSeek的潜在空间。此外,本文通过提供两个非标准研究路径的成功范例,为未来博弈论与人工智能安全领域的创新奠定了基础:一方面研究超出传统博弈论工具范畴的新型游戏,另一方面以既无需确定价值取向也无需强制执行为前提,有效缓解了重大人工智能安全风险。