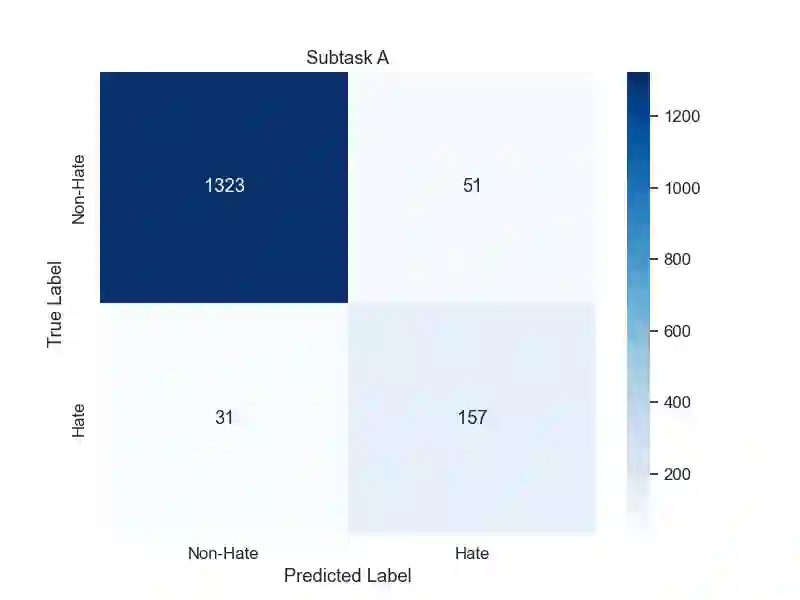
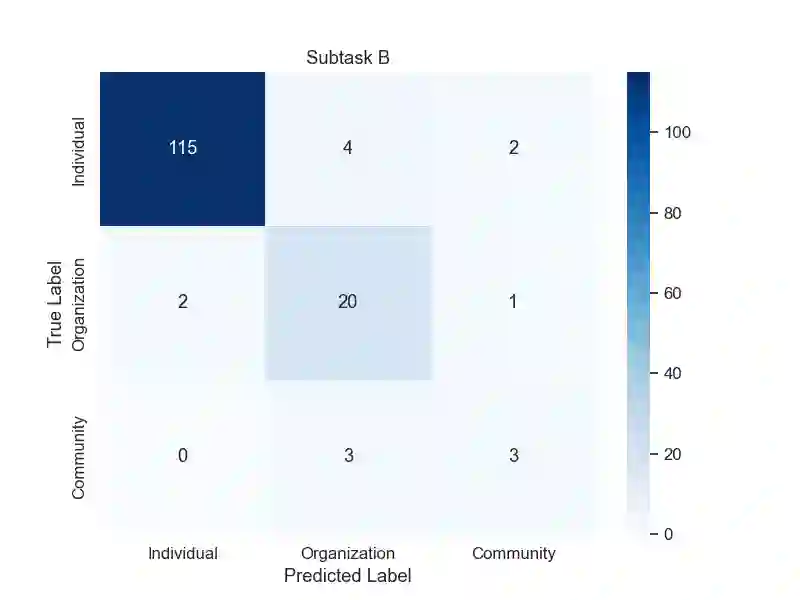
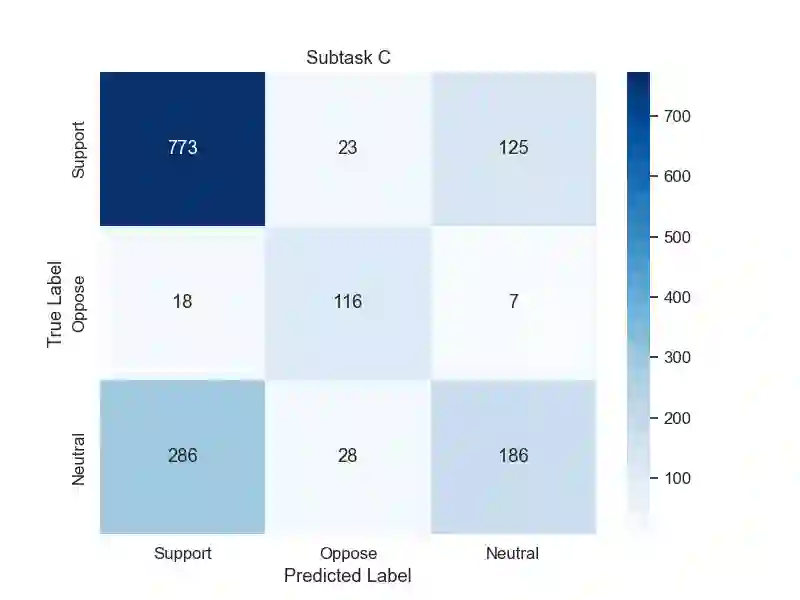
This study details our approach for the CASE 2024 Shared Task on Climate Activism Stance and Hate Event Detection, focusing on Hate Speech Detection, Hate Speech Target Identification, and Stance Detection as classification challenges. We explored the capability of Large Language Models (LLMs), particularly GPT-4, in zero- or few-shot settings enhanced by retrieval augmentation and re-ranking for Tweet classification. Our goal was to determine if LLMs could match or surpass traditional methods in this context. We conducted an ablation study with LLaMA for comparison, and our results indicate that our models significantly outperformed the baselines, securing second place in the Target Detection task. The code for our submission is available at https://github.com/NaiveNeuron/bryndza-case-2024
翻译:本研究详细阐述了我们参与CASE 2024共享任务(气候行动主义立场与仇恨事件检测)的方法,重点解决仇恨言论检测、仇恨言论目标识别及立场检测等分类挑战。我们探索了大语言模型(LLMs),特别是GPT-4,在零样本或少样本场景下通过检索增强与重排序技术进行推特分类的能力。我们的目标是评估在此场景中,LLM能否媲美甚至超越传统方法。我们通过LLaMA模型进行了消融实验对比,结果表明我们的模型显著优于基线模型,并在目标检测任务中获得第二名。提交的代码发布于https://github.com/NaiveNeuron/bryndza-case-2024。