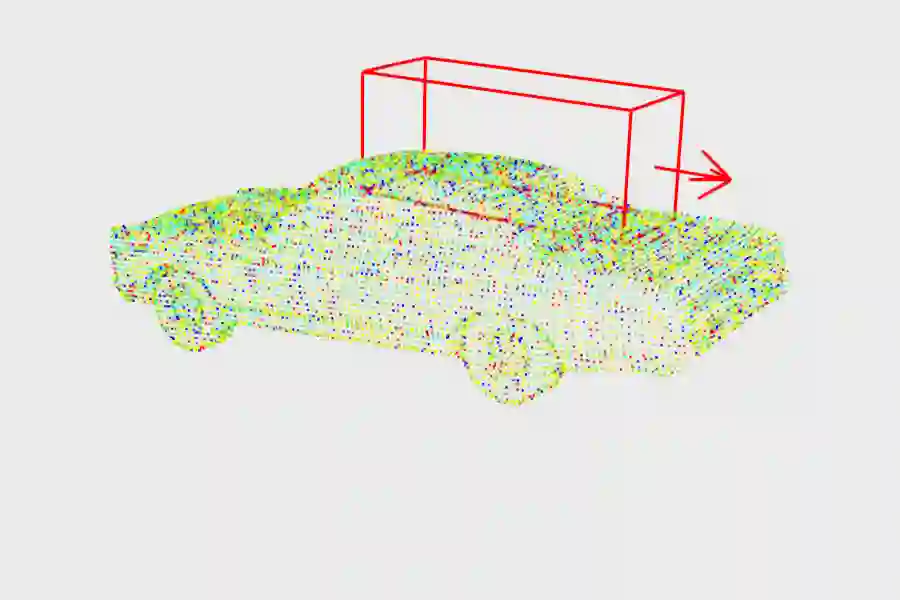
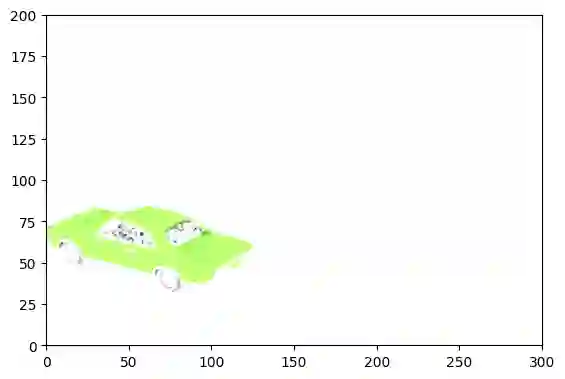
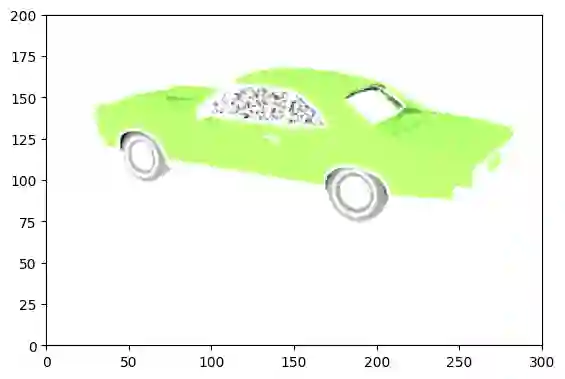
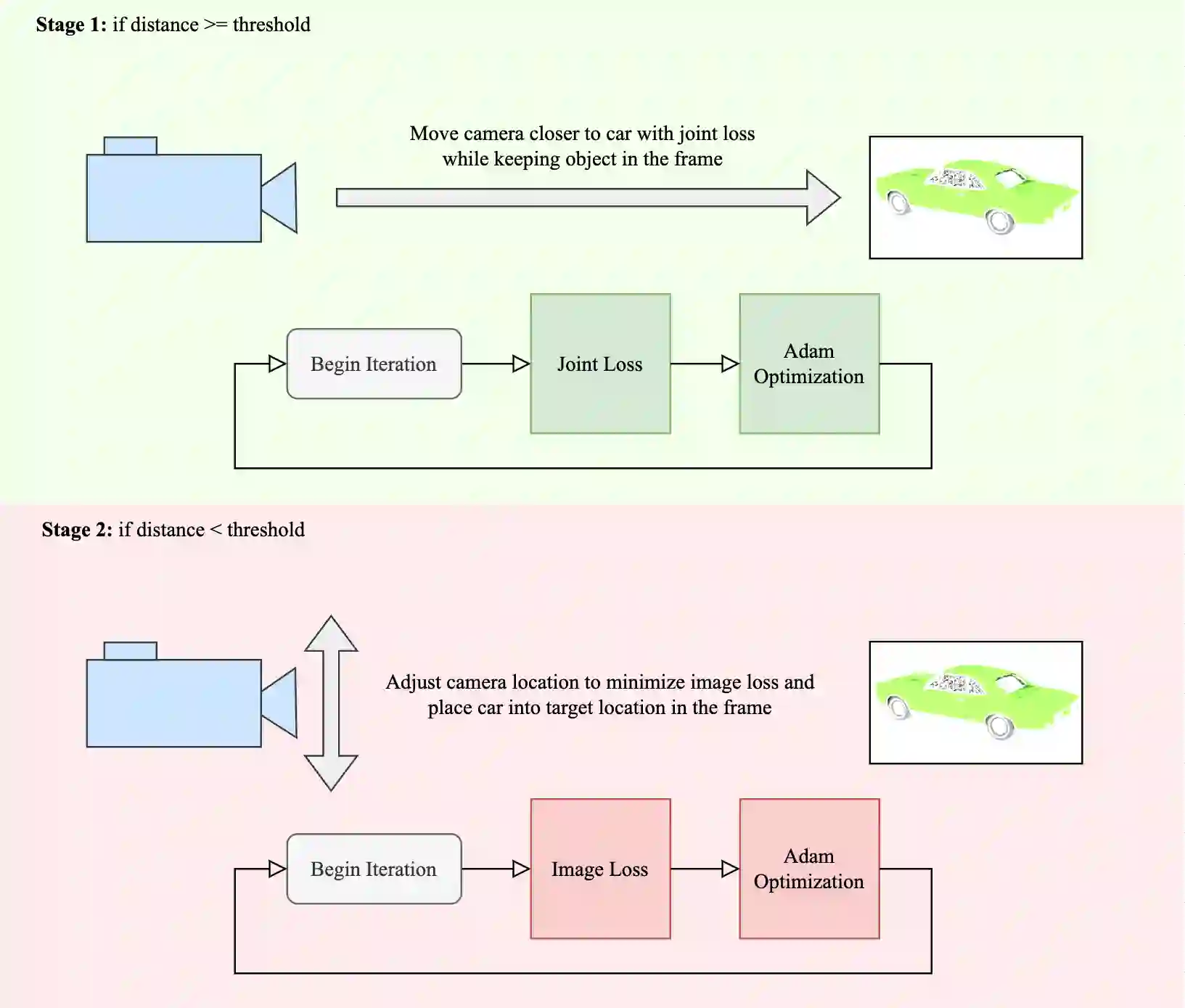
This article describes a multi-modal method using simulated Lidar data via ray tracing and image pixel loss with differentiable rendering to optimize an object's position with respect to an observer or some referential objects in a computer graphics scene. Object position optimization is completed using gradient descent with the loss function being influenced by both modalities. Typical object placement optimization is done using image pixel loss with differentiable rendering only, this work shows the use of a second modality (Lidar) leads to faster convergence. This method of fusing sensor input presents a potential usefulness for autonomous vehicles, as these methods can be used to establish the locations of multiple actors in a scene. This article also presents a method for the simulation of multiple types of data to be used in the training of autonomous vehicles.
翻译:本文提出了一种多模态方法,通过射线追踪模拟激光雷达数据,并结合可微分渲染的图像像素损失,优化计算机图形场景中物体相对于观察者或参考物体的位置。物体位置优化采用梯度下降法完成,其损失函数受两种模态共同影响。典型的物体位置优化仅使用可微分渲染的图像像素损失,而本研究表明,引入第二种模态(激光雷达)可加速收敛。这种传感器输入融合方法对自动驾驶车辆具有潜在应用价值,因为该方法可用于确定场景中多个对象的位置。此外,本文还提出了一种多类型数据模拟方法,可用于自动驾驶车辆的训练。