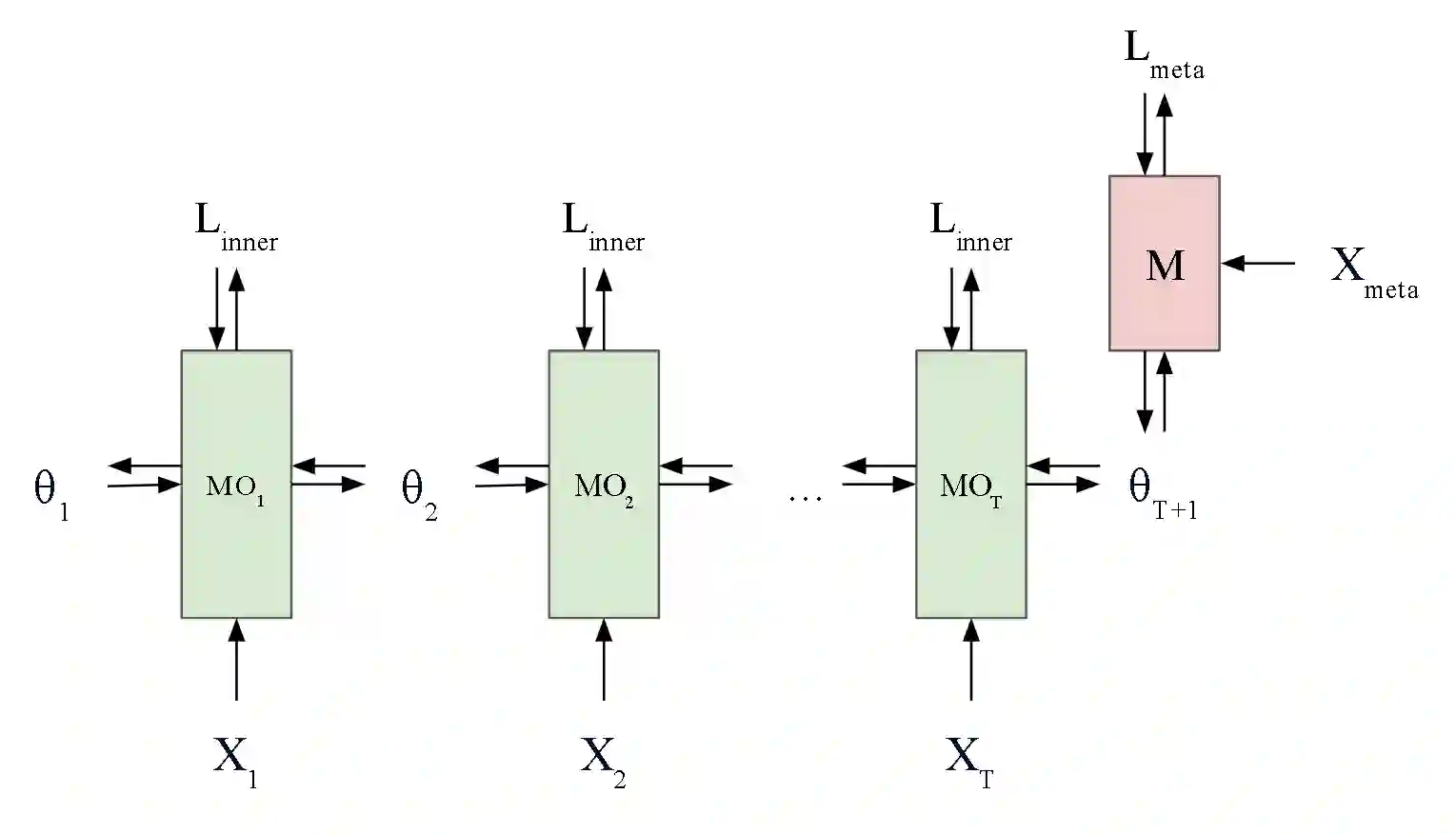
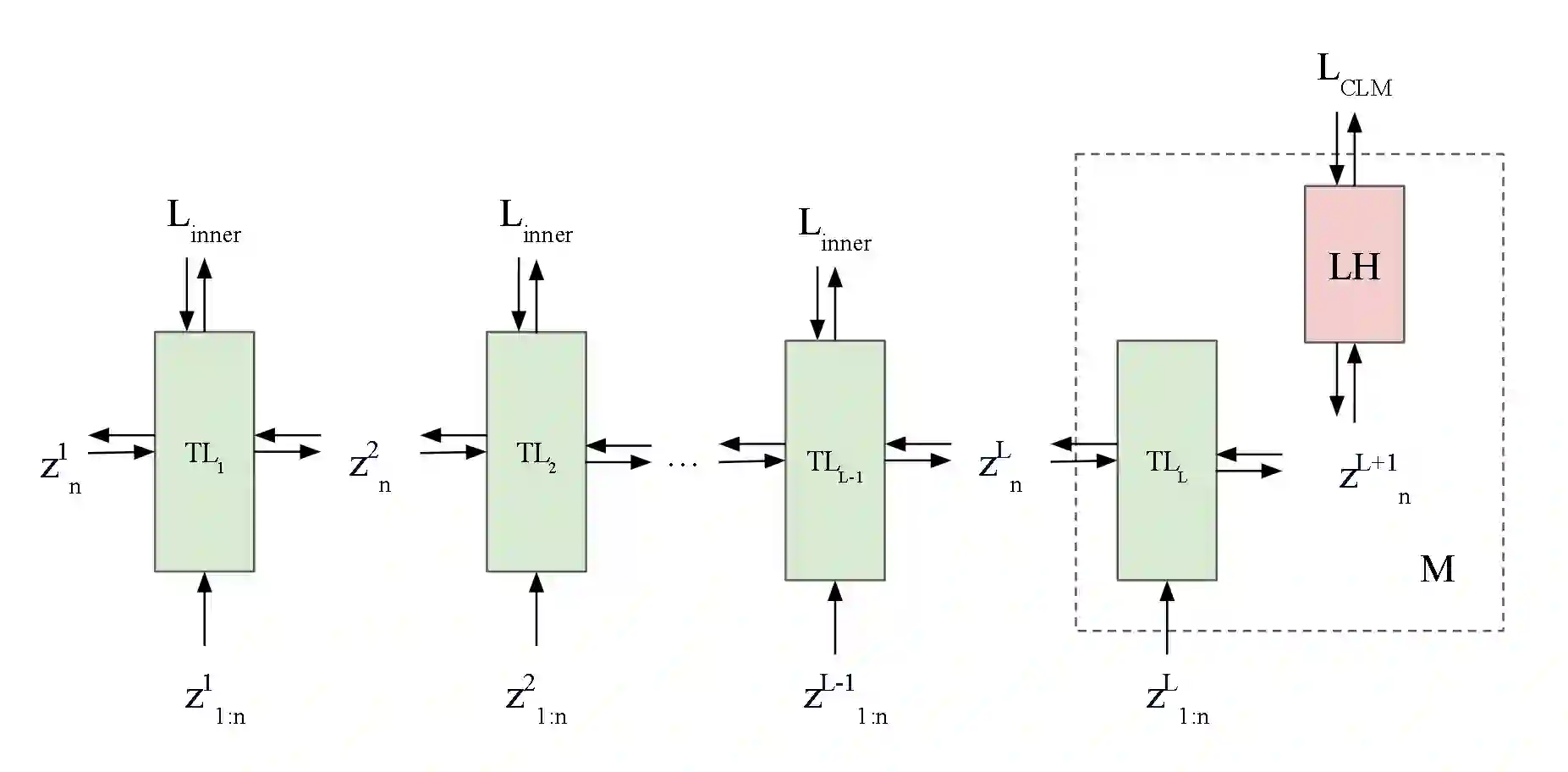
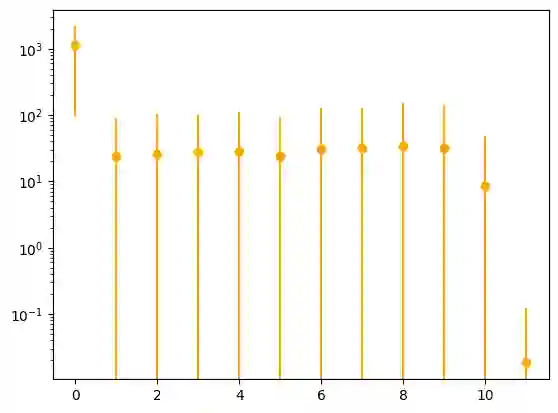
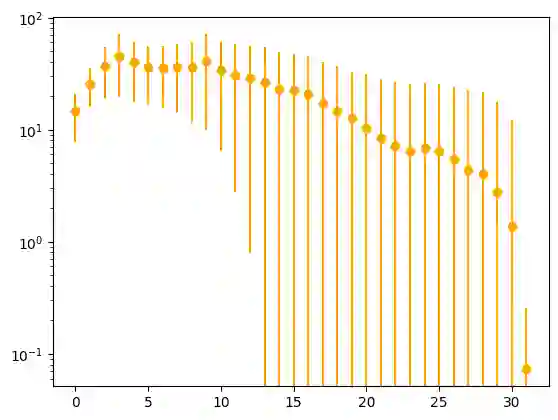
The Transformer architecture has become prominent in developing large causal language models. However, mechanisms to explain its capabilities are not well understood. Focused on the training process, here we establish a meta-learning view of the Transformer architecture when trained for the causal language modeling task, by explicating an inner optimization process that may happen within the Transformer. Further, from within the inner optimization, we discover and theoretically analyze a special characteristic of the norms of learned token representations within Transformer-based causal language models. Our analysis is supported by experiments conducted on pre-trained large language models and real-world data.
翻译:摘要:Transformer架构在大型因果语言模型的开发中已占据主导地位。然而,解释其能力的机制尚未被充分理解。本文聚焦于训练过程,通过阐明Transformer内部可能发生的内层优化过程,为因果语言建模任务训练的Transformer架构建立了元学习视角。进一步地,从该内层优化中,我们发现并理论分析了基于Transformer的因果语言模型中习得词元表示范数的一个特殊特性。我们的分析得到了基于预训练大型语言模型及真实数据进行的实验支持。