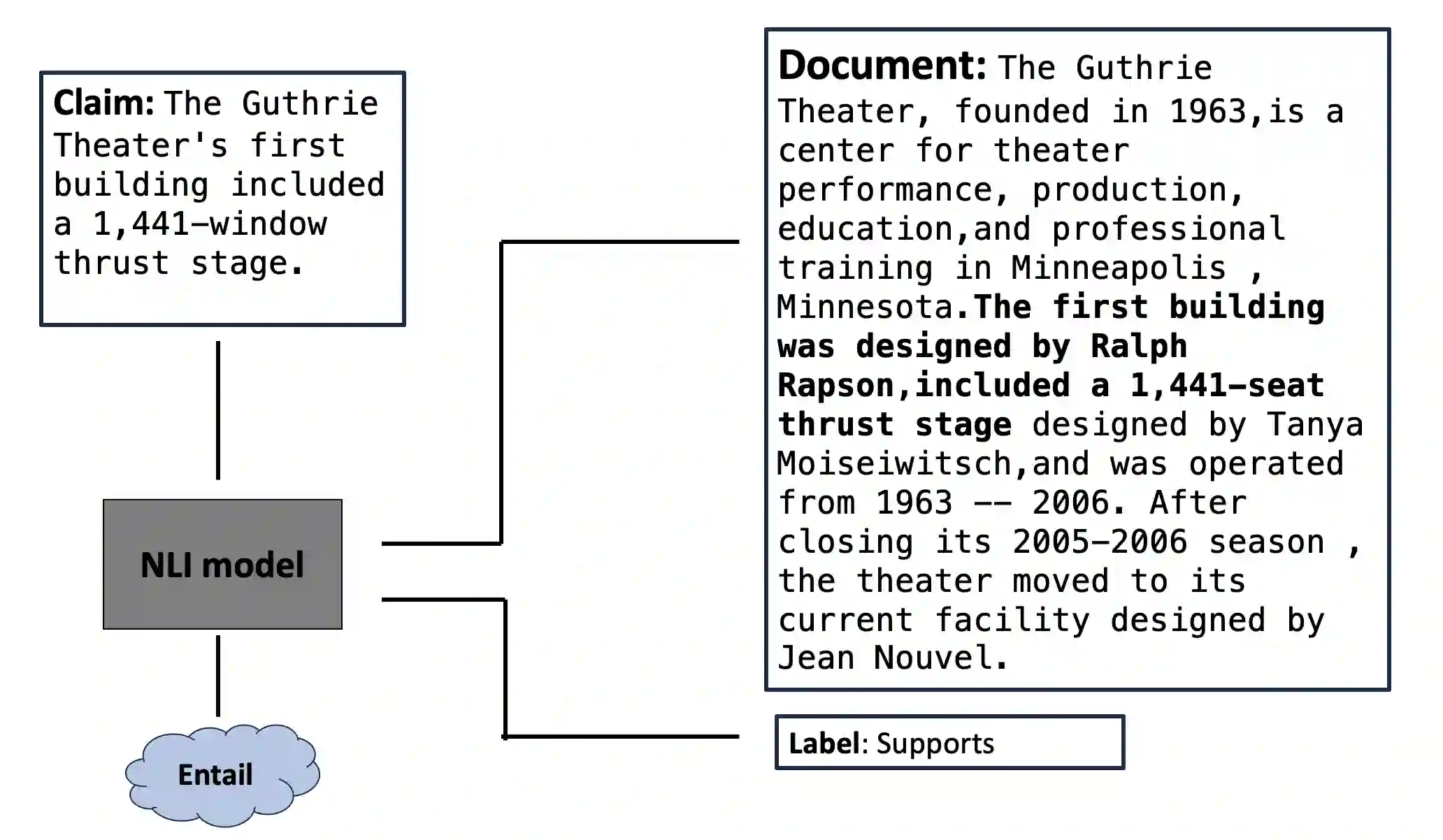
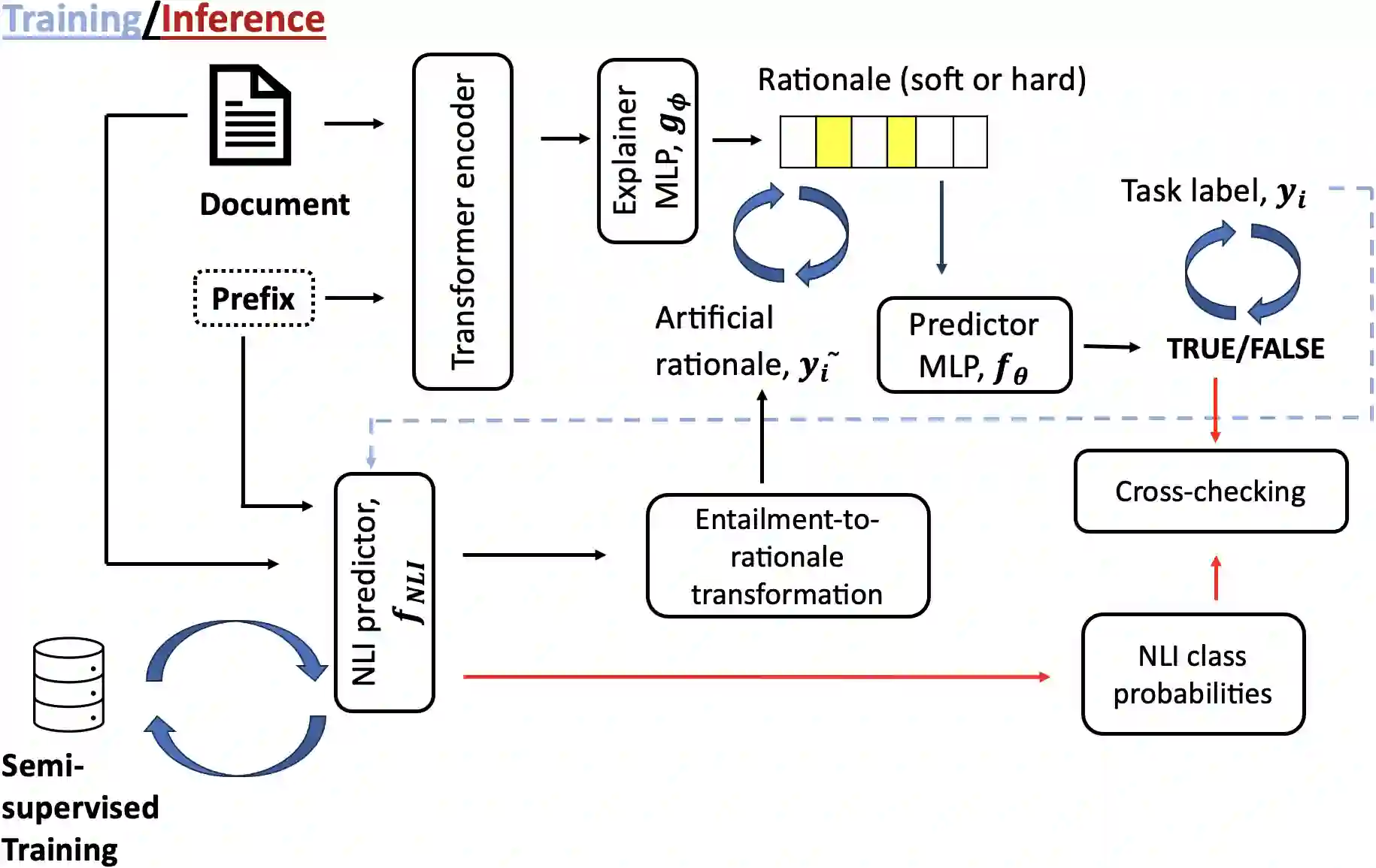
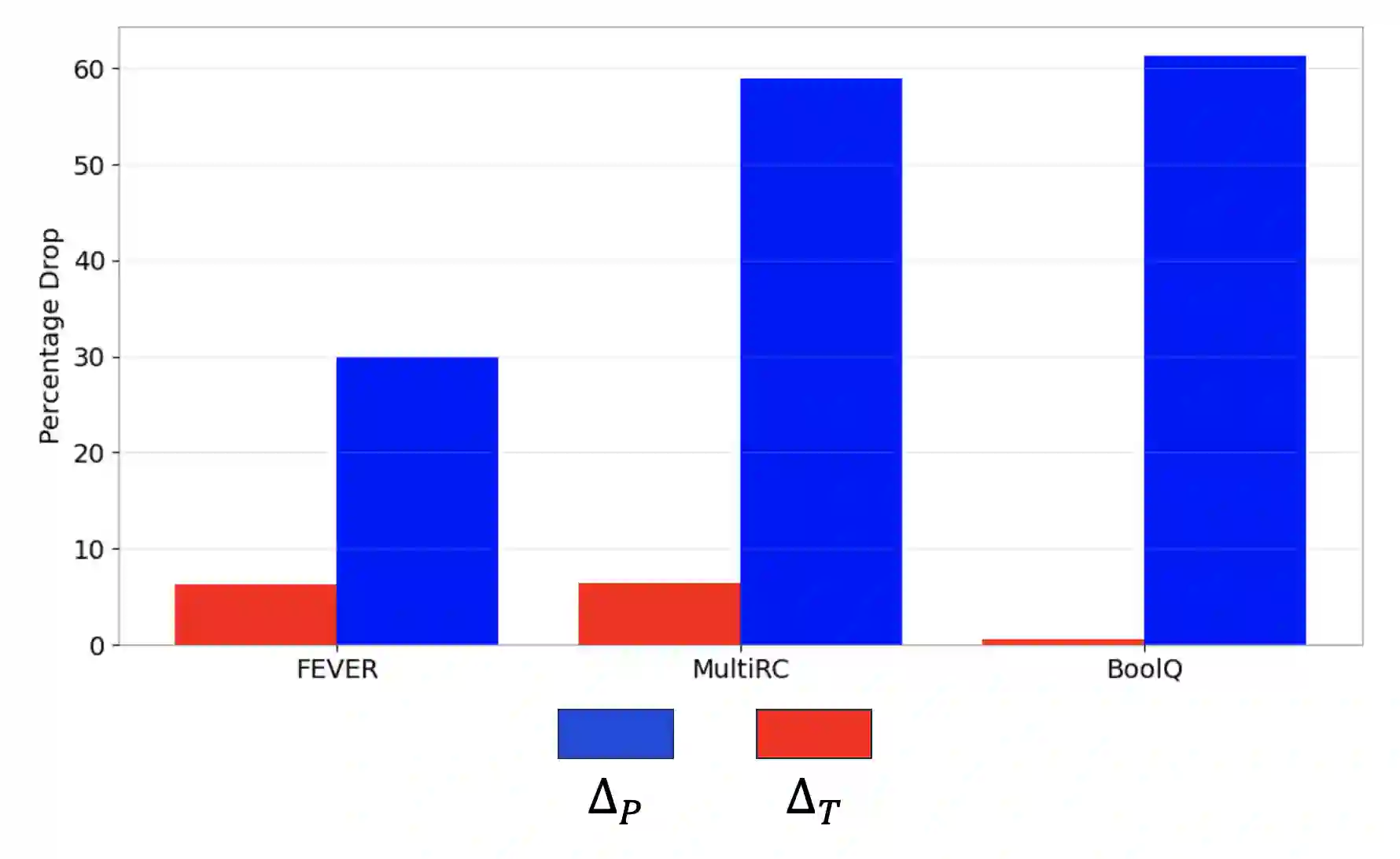
The increasing use of complex and opaque black box models requires the adoption of interpretable measures, one such option is extractive rationalizing models, which serve as a more interpretable alternative. These models, also known as Explain-Then-Predict models, employ an explainer model to extract rationales and subsequently condition the predictor with the extracted information. Their primary objective is to provide precise and faithful explanations, represented by the extracted rationales. In this paper, we take a semi-supervised approach to optimize for the plausibility of extracted rationales. We adopt a pre-trained natural language inference (NLI) model and further fine-tune it on a small set of supervised rationales ($10\%$). The NLI predictor is leveraged as a source of supervisory signals to the explainer via entailment alignment. We show that, by enforcing the alignment agreement between the explanation and answer in a question-answering task, the performance can be improved without access to ground truth labels. We evaluate our approach on the ERASER dataset and show that our approach achieves comparable results with supervised extractive models and outperforms unsupervised approaches by $> 100\%$.
翻译:随着复杂且不透明的黑箱模型日益普及,亟需采用可解释性方法,其中抽取式解释模型作为一种更易解释的替代方案备受关注。此类模型(亦称"先解释后预测"模型)通过解释器模块提取解释性文本片段,并以此约束预测器的条件推断。其核心目标在于提供由提取片段表征的精确且忠实的解释。本文采用半监督方法优化所提取解释的似然性。我们利用预训练的自然语言推理(NLI)模型,并在少量有监督解释样本(占数据集的10%)上进行微调。通过蕴含对齐机制,将NLI预测器作为解释器的监督信号源。实验表明,在问答任务中实施解释与答案之间的对齐一致性约束后,无需真实标签即可提升模型性能。在ERASER数据集上的评估显示,本方法性能与有监督抽取式模型相当,且相较无监督方法提升超过100%。