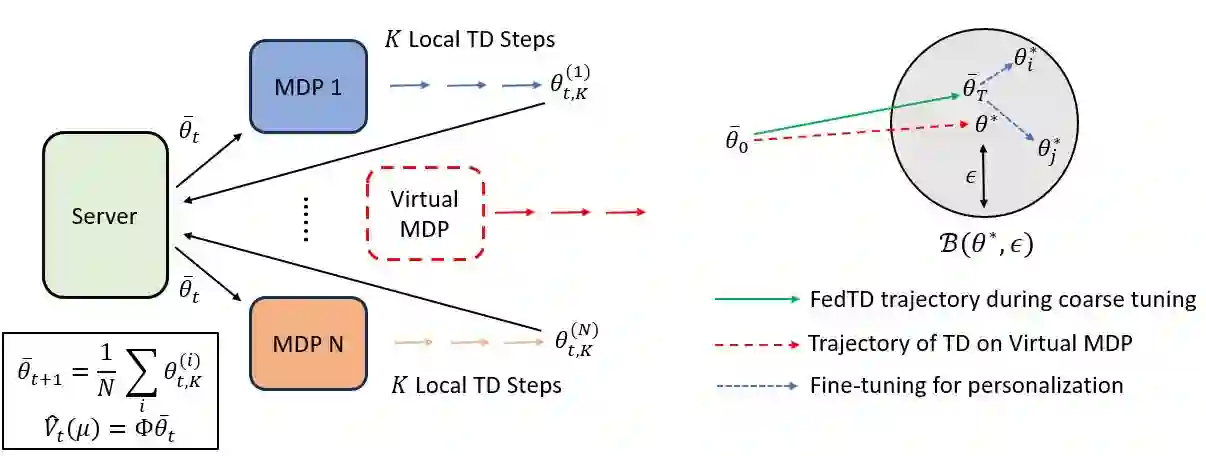
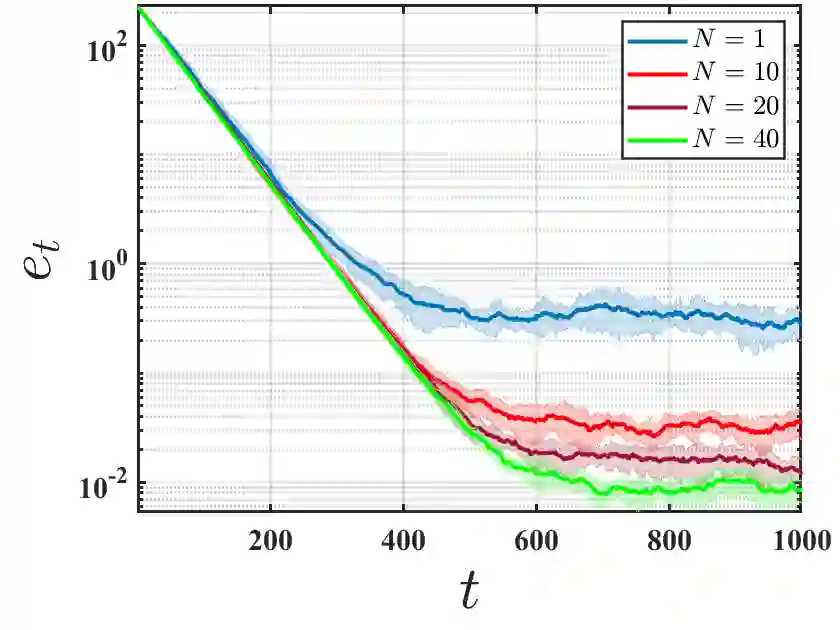
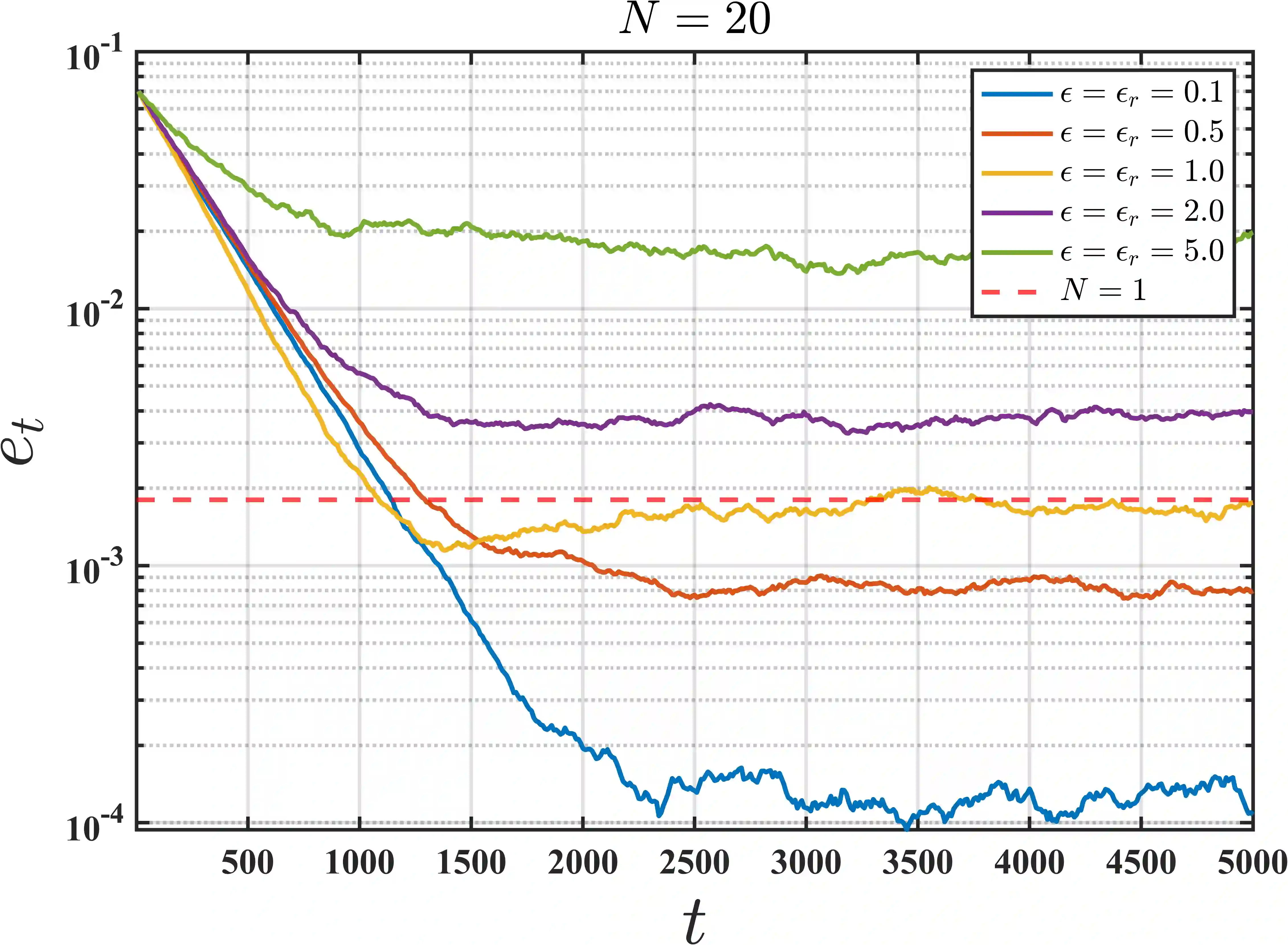
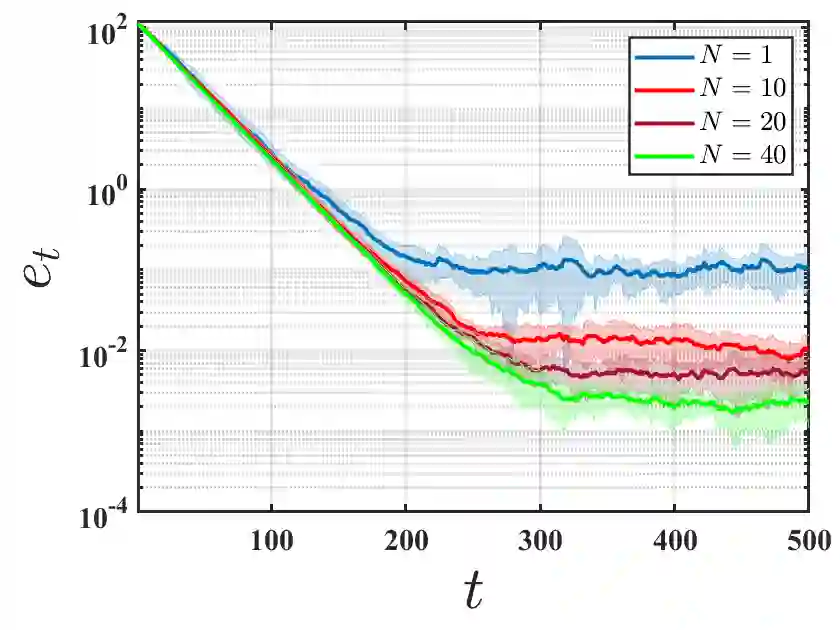
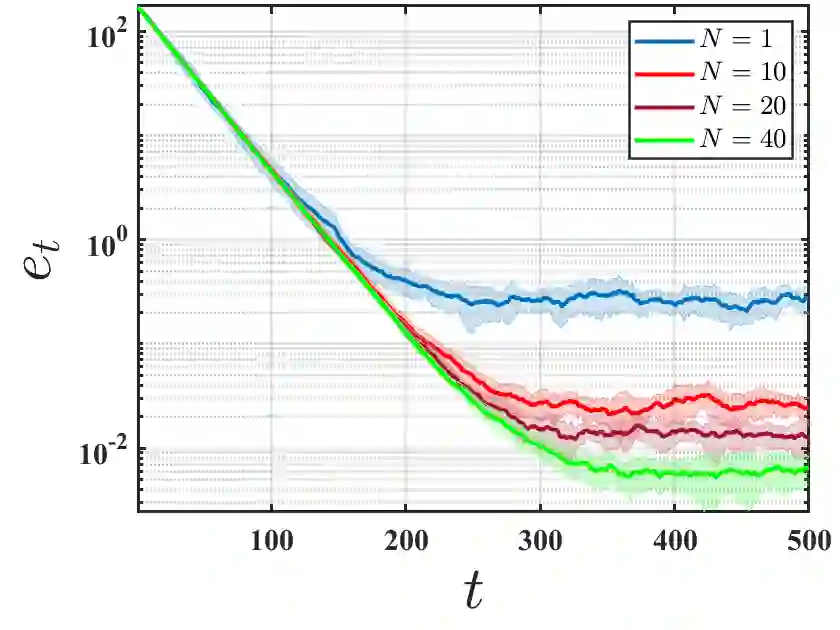
We initiate the study of federated reinforcement learning under environmental heterogeneity by considering a policy evaluation problem. Our setup involves $N$ agents interacting with environments that share the same state and action space but differ in their reward functions and state transition kernels. Assuming agents can communicate via a central server, we ask: Does exchanging information expedite the process of evaluating a common policy? To answer this question, we provide the first comprehensive finite-time analysis of a federated temporal difference (TD) learning algorithm with linear function approximation, while accounting for Markovian sampling, heterogeneity in the agents' environments, and multiple local updates to save communication. Our analysis crucially relies on several novel ingredients: (i) deriving perturbation bounds on TD fixed points as a function of the heterogeneity in the agents' underlying Markov decision processes (MDPs); (ii) introducing a virtual MDP to closely approximate the dynamics of the federated TD algorithm; and (iii) using the virtual MDP to make explicit connections to federated optimization. Putting these pieces together, we rigorously prove that in a low-heterogeneity regime, exchanging model estimates leads to linear convergence speedups in the number of agents.
翻译:我们通过考虑一个策略评估问题,首次研究了环境异质性下的联邦强化学习。我们的设置涉及 $N$ 个智能体,它们与共享相同状态和动作空间、但奖励函数和状态转移核不同的环境进行交互。假设智能体可以通过中央服务器进行通信,我们提出疑问:交换信息是否能加速评估共同策略的过程?为了回答这个问题,我们首次对采用线性函数逼近的联邦时序差分学习算法进行了全面的有限时间分析,同时考虑了马尔可夫采样、智能体环境间的异质性以及为节省通信而进行的多次本地更新。我们的分析关键依赖于几个新颖的组成部分:(i) 推导了 TD 不动点的扰动界限,作为智能体底层马尔可夫决策过程异质性的函数;(ii) 引入了一个虚拟 MDP 来紧密逼近联邦 TD 算法的动态;(iii) 利用该虚拟 MDP 建立与联邦优化的显式联系。综合这些部分,我们严格证明了在低异质性状态下,交换模型估计能够带来随智能体数量增长的线性收敛加速。