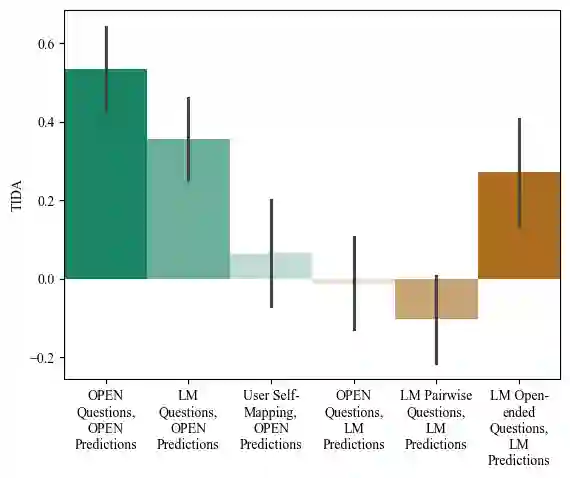
Aligning AI systems to users' interests requires understanding and incorporating humans' complex values and preferences. Recently, language models (LMs) have been used to gather information about the preferences of human users. This preference data can be used to fine-tune or guide other LMs and/or AI systems. However, LMs have been shown to struggle with crucial aspects of preference learning: quantifying uncertainty, modeling human mental states, and asking informative questions. These challenges have been addressed in other areas of machine learning, such as Bayesian Optimal Experimental Design (BOED), which focus on designing informative queries within a well-defined feature space. But these methods, in turn, are difficult to scale and apply to real-world problems where simply identifying the relevant features can be difficult. We introduce OPEN (Optimal Preference Elicitation with Natural language) a framework that uses BOED to guide the choice of informative questions and an LM to extract features and translate abstract BOED queries into natural language questions. By combining the flexibility of LMs with the rigor of BOED, OPEN can optimize the informativity of queries while remaining adaptable to real-world domains. In user studies, we find that OPEN outperforms existing LM- and BOED-based methods for preference elicitation.
翻译:将人工智能系统与用户兴趣对齐,需要理解并融合人类复杂的价值观和偏好。近期,语言模型(LMs)被用于收集人类用户的偏好信息。这类偏好数据可用于微调其他语言模型和/或人工智能系统。然而,研究表明语言模型在偏好学习的三个关键方面存在不足:量化不确定性、建模人类心理状态及提出信息性问题。这些问题在机器学习其他领域(如贝叶斯最优实验设计(BOED))中已得到解决,其核心是在明确定义的特征空间内设计信息性查询。但这类方法难以扩展,且难以应用于需要识别相关特征的现实问题。我们提出OPEN(基于自然语言的最优偏好获取)框架,该框架利用BOED指导信息性问题的选择,并通过语言模型提取特征,将抽象的BOED查询转化为自然语言问题。通过融合语言模型的灵活性与BOED的严谨性,OPEN可在保持现实领域适应性的同时,优化查询的信息性。在用户研究中,我们发现OPEN在偏好获取任务上优于现有基于语言模型和BOED的方法。