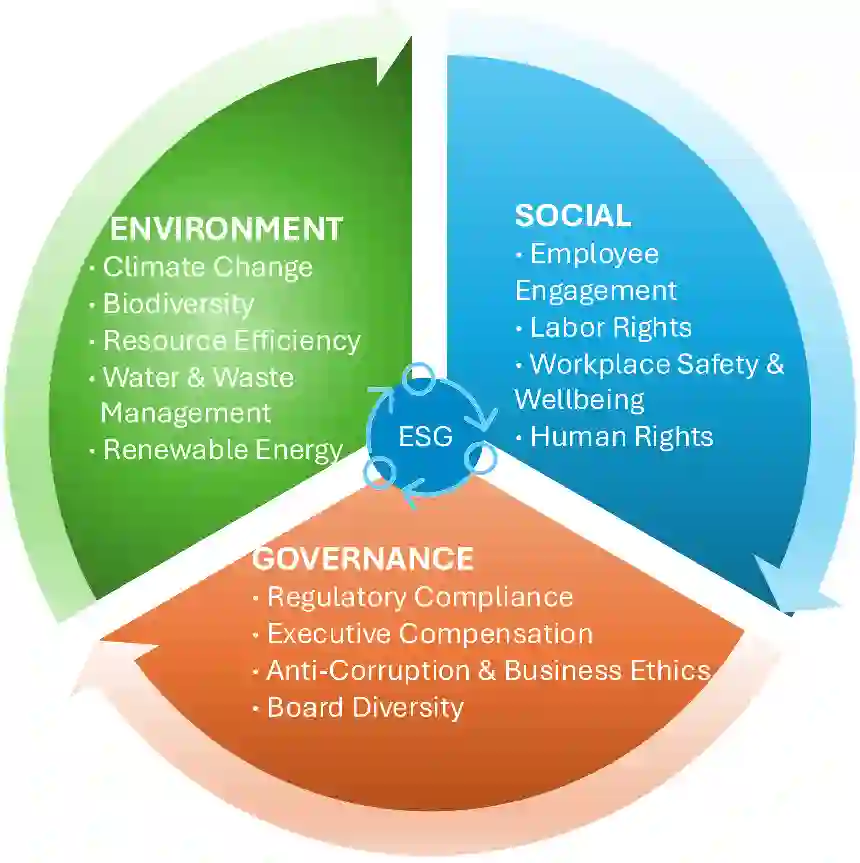
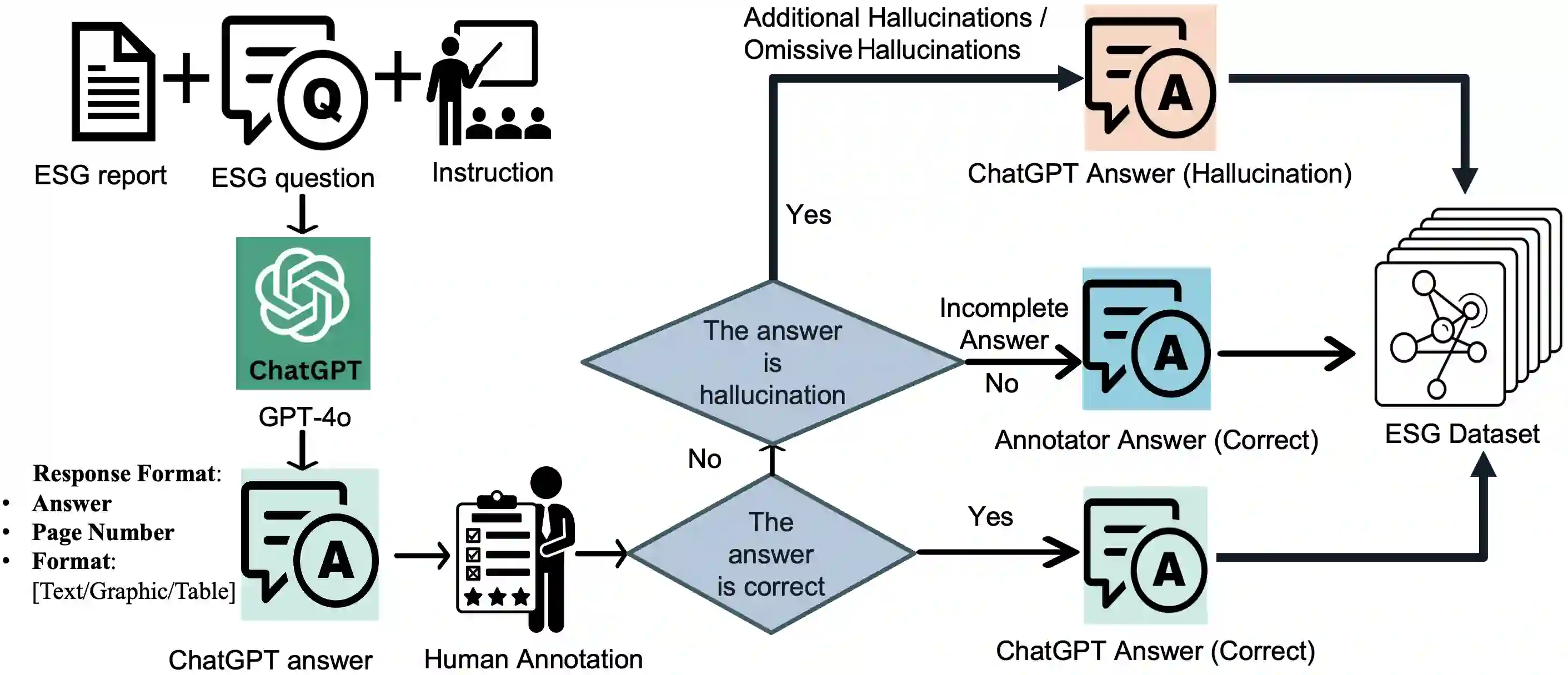
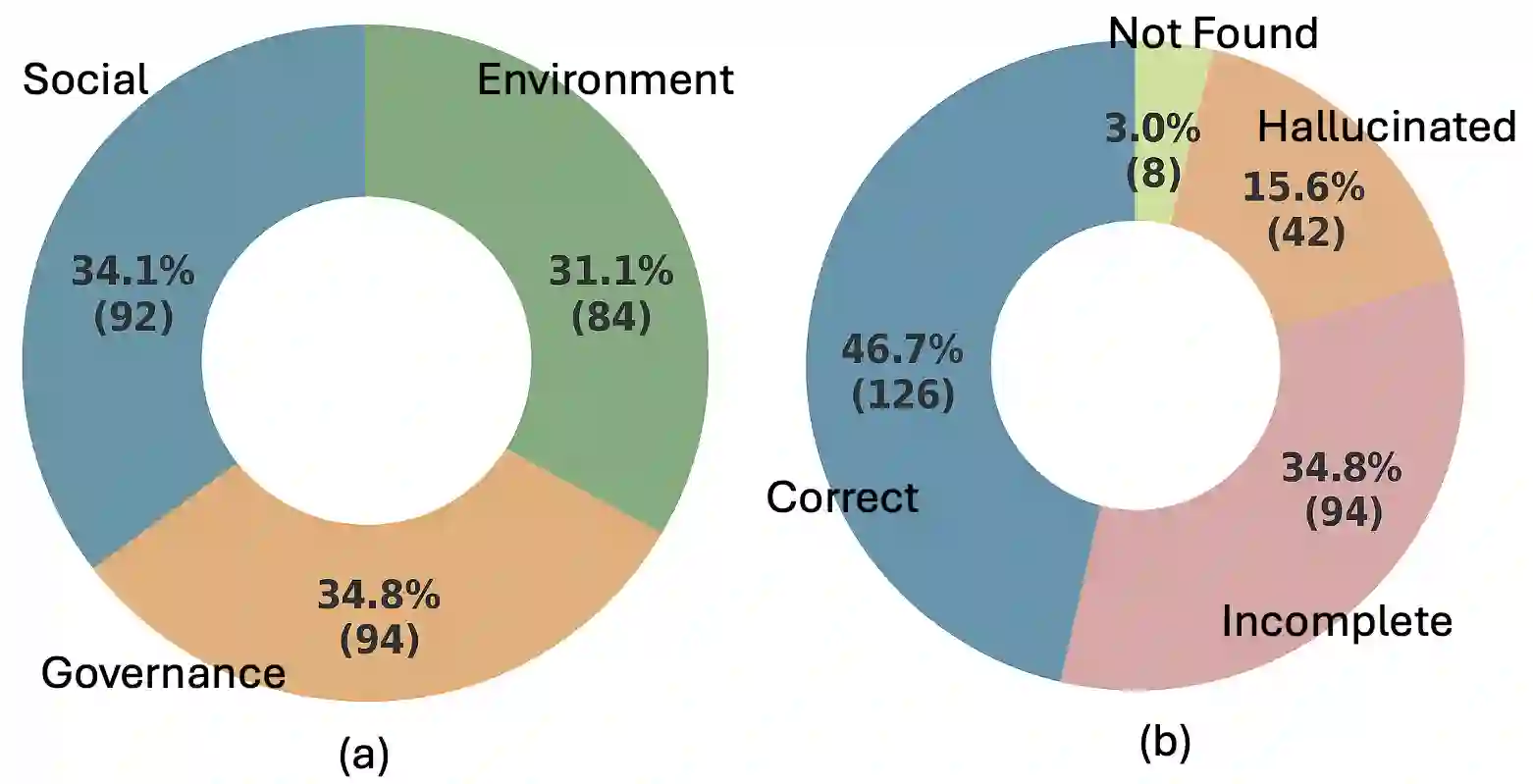
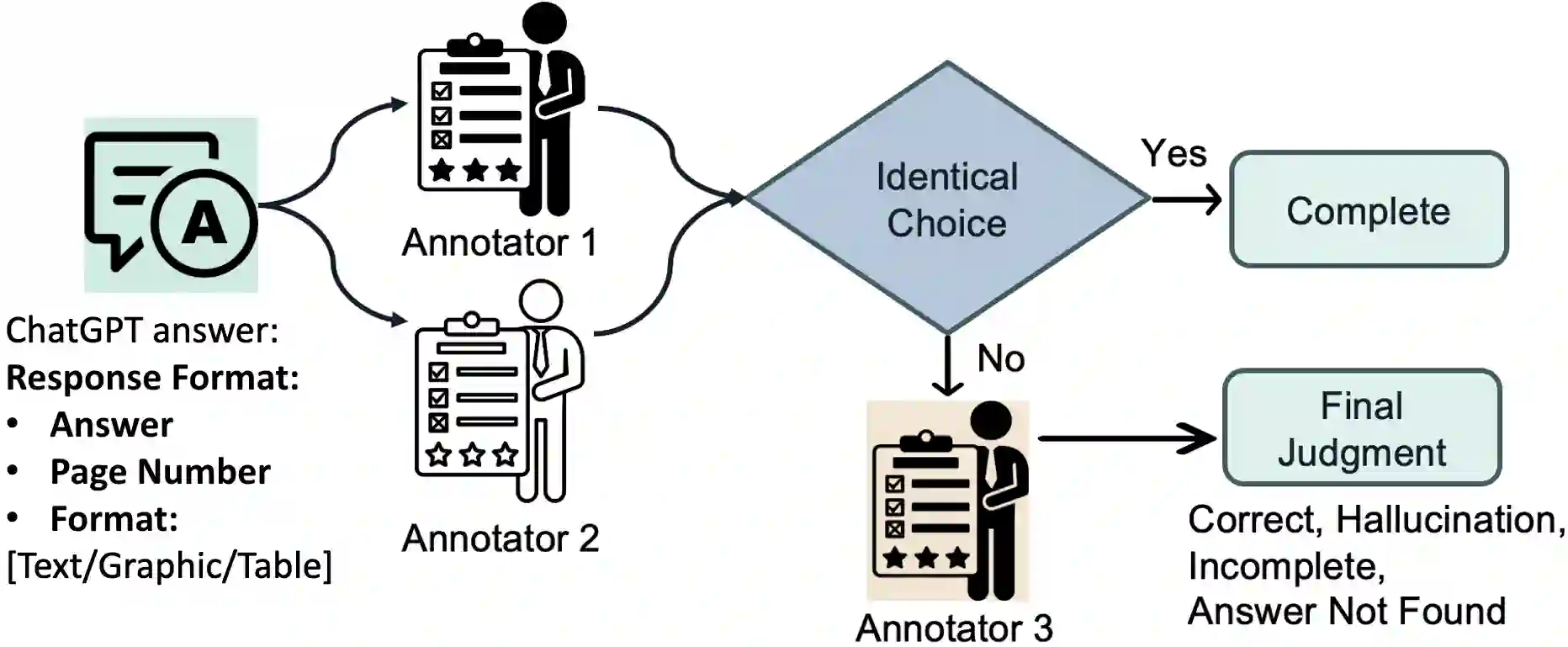
As corporate responsibility increasingly incorporates environmental, social, and governance (ESG) criteria, ESG reporting is becoming a legal requirement in many regions and a key channel for documenting sustainability practices and assessing firms' long-term and ethical performance. However, the length and complexity of ESG disclosures make them difficult to interpret and automate the analysis reliably. To support scalable and trustworthy analysis, this paper introduces ESG-Bench, a benchmark dataset for ESG report understanding and hallucination mitigation in large language models (LLMs). ESG-Bench contains human-annotated question-answer (QA) pairs grounded in real-world ESG report contexts, with fine-grained labels indicating whether model outputs are factually supported or hallucinated. Framing ESG report analysis as a QA task with verifiability constraints enables systematic evaluation of LLMs' ability to extract and reason over ESG content and provides a new use case: mitigating hallucinations in socially sensitive, compliance-critical settings. We design task-specific Chain-of-Thought (CoT) prompting strategies and fine-tune multiple state-of-the-art LLMs on ESG-Bench using CoT-annotated rationales. Our experiments show that these CoT-based methods substantially outperform standard prompting and direct fine-tuning in reducing hallucinations, and that the gains transfer to existing QA benchmarks beyond the ESG domain.
翻译:随着企业责任日益融入环境、社会和治理(ESG)标准,ESG报告正成为许多地区的法定要求,也是记录可持续发展实践、评估企业长期与伦理绩效的关键渠道。然而,ESG披露文件的长度与复杂性使其难以被可靠地解读或实现自动化分析。为支持可扩展且可信的分析,本文提出ESG-Bench——一个面向大语言模型(LLMs)的ESG报告理解与幻觉缓解基准数据集。ESG-Bench包含基于真实ESG报告语境的人工标注问答对,并带有细粒度标签以指示模型输出是否具备事实依据或存在幻觉。将ESG报告分析构建为具有可验证性约束的问答任务,既能系统评估LLMs提取与推理ESG内容的能力,也提供了一个新的应用场景:在社会敏感、合规关键的环境中缓解幻觉问题。我们设计了任务特定的思维链(CoT)提示策略,并利用带CoT标注的推理依据对多个前沿LLMs在ESG-Bench上进行微调。实验表明,这些基于CoT的方法在减少幻觉方面显著优于标准提示与直接微调,且其增益可迁移至ESG领域之外的现有问答基准。